周鴻祎稱大模型不是萬能 不要覺得有了GPT就能裁員了

近日三六零集團(tuán)的創(chuàng)始人兼董事長周鴻祎在其微博上表示:“我始終認(rèn)為,公司不應(yīng)該以為通過GPT就可以削減工作崗位,。大模型也不是萬能的,它只是起到了輔助作用,,完成了部分任務(wù),。因此,大型的模式并不會將人排除在外,,更不會將程序員排除在外,。我不是報了清華大學(xué)的電子信息系嗎?人工智能的發(fā)展,,必須要以人為本,,以人為本?!?/p>
以下為演講全文:
大家好,,感謝主辦方的邀請,很高興參加尼山對話,。今天我們討論的主題聚焦“構(gòu)建安全可信的人工智能”,、“人工智能賦能百行千業(yè)”,最近360自研的認(rèn)知大模型智腦也在相關(guān)方向有探索,借今天的機(jī)會,,我想分享一些實踐中得到的經(jīng)驗和思考,。
這次GPT大模型的誕生代表著通用人工智能、強(qiáng)人工智能的到來,,是真正的智能涌現(xiàn),。大模型能夠真正地理解人類所有的語言,能夠很自然地做出各種交流和推理,,這意味著人工智能第一次完整地理解了我們?nèi)祟愂澜绲闹R,,并且已經(jīng)從感知進(jìn)化到了認(rèn)知,不僅能夠理解文字,、語言,,還能做出分析、規(guī)劃,。未來,,傳統(tǒng)算法將被代替,大模型在自動駕駛,、機(jī)器人控制,、蛋白質(zhì)分析等很多重要領(lǐng)域都會大顯身手。
目前產(chǎn)學(xué)研各界已經(jīng)形成了共識,,GPT大模型將會帶來一場新的工業(yè)革命,。我們都知道,數(shù)字時代最重要的是大數(shù)據(jù),,但大數(shù)據(jù)就像“石油”,,難以直接使用。GPT的出現(xiàn)就像發(fā)電廠,,把大數(shù)據(jù)從“石油”加工成了“電”,,賦能百行千業(yè)。如今數(shù)字化已上升為中國的國家戰(zhàn)略,,其中產(chǎn)業(yè)數(shù)字化是重要的發(fā)展機(jī)遇,,我認(rèn)為產(chǎn)業(yè)數(shù)字化的終極目標(biāo)就是智能化,而GPT大模型將會成為產(chǎn)業(yè)數(shù)字化重要的賦能者,。
在這場工業(yè)革命中,,大模型真正的機(jī)會在企業(yè)市場,作為生產(chǎn)力工具提升企業(yè)生產(chǎn)率,。ChatGPT雖然是靠聊天功能“破圈”的,,但這只是它的一種“親民偽裝”,實際上大模型絕對不是一個娛樂工具,,而是工業(yè)革命級的生產(chǎn)力工具,。如果大家留意就會發(fā)現(xiàn),,即使是個人消費者,最終還是會用大模型滿足剛需,,應(yīng)用在辦公場景里,,成為提高辦公效率的工具,比如公文寫作等等,。因此我認(rèn)為,,企業(yè)級市場才是大模型未來發(fā)展真正出彩的地方。
但是,,當(dāng)我們帶著通用大模型真正走進(jìn)政府,、城市、行業(yè),、企業(yè)時就會發(fā)現(xiàn),,公有大模型無法直接使用。因為公有大模型存在以下四點不足:
第一,,公有大模型雖然是通才,,但它缺乏行業(yè)深度。我們之前認(rèn)為GPT什么都會,,但如果你是一個行業(yè)專家,,你會發(fā)現(xiàn)GPT在安全、金融這些垂直領(lǐng)域,,知識深度是不夠的,。很多公司自己訓(xùn)大模型都發(fā)現(xiàn)了這個特點,想讓它能力很均衡,,就會犧牲深度,。所以未來垂直大模型是重要的發(fā)展方向,通用模型和各領(lǐng)域?qū)S械闹R數(shù)據(jù)結(jié)合,,讓大模型從“萬事通”變成政府通,、行業(yè)通和企業(yè)通,這才是真正的價值,。最新資料表明,GPT4也是由8個垂直模型組成的,,從側(cè)面印證了這個觀點,。
第二,公有大模型容易造成企業(yè)內(nèi)部數(shù)據(jù)泄露,。一方面,,公有大模型不是本地部署,它與外部進(jìn)行信息交流時必然存在數(shù)據(jù)泄露的風(fēng)險,;另一方面,,公有大模型也無法實現(xiàn)組織內(nèi)部權(quán)限的分級管理,。因此,政府,、企業(yè)使用公有大模型必然存在安全風(fēng)險,。
第三,對企業(yè)來講,,公有大模型無法保障內(nèi)容真正可信。這主要包含兩個問題:一個是企業(yè)在日常生產(chǎn)經(jīng)營過程中,,知識庫是實時產(chǎn)生的,并且不斷變化,。它不像公有大模型的通用知識,,是一成不變的“百科全書”。因此,,企業(yè)使用公有大模型無法滿足時效性的需求,。另一個是大模型自身的“幻覺”問題,也就是我們常說的一本正經(jīng)地“胡說八道”,。公有大模型經(jīng)常出現(xiàn)張冠李戴的問題,,需要通過企業(yè)的內(nèi)部搜索、內(nèi)部知識庫進(jìn)行矯正。這些都需要專有大模型才能實現(xiàn),。
第四,,也是很多企業(yè)級用戶關(guān)注的,公有大模型無法實現(xiàn)成本可控,。舉個例子,,很多企業(yè)其實只需要大模型寫代碼的能力,這時候公有大模型寫詩,、寫論文的能力就是多余的,。也就是說,,很多企業(yè)只需要百億級垂直大模型就滿足需求,如果使用千億級大模型就是成本的浪費,。這個成本不只是大模型的采購成本,,還包括訓(xùn)練成本、部署成本,、微調(diào)成本,。在控制成本方面,垂直大模型將會有很大優(yōu)勢,。因此,,在一個用公開數(shù)據(jù)訓(xùn)練的“通識”大模型基礎(chǔ)上,訓(xùn)練專有大模型,,就能做到“事半功倍”,,為企業(yè)降本增效。
大模型想要成為企業(yè)級的智能化賦能工具,,必須要行業(yè)化,、專有化,從萬事通變成城市通,、行業(yè)通,、企業(yè)通。而企業(yè)落地大模型則需要分步來實現(xiàn),。我認(rèn)為目前的當(dāng)務(wù)之急叫做“小切口大縱深”,,先把大模型最擅長、最成熟的能力用好,。剛開始可以從辦公場景入手,。因為大模型不是萬能的,最擅長最成熟的能力肯定是自然語言處理,。而且辦公場景能做到松耦合,,與現(xiàn)有的業(yè)務(wù)系統(tǒng)無縫融合。具體來說,,一些細(xì)分場景包括信息分析,、知識管理、內(nèi)容創(chuàng)作和智能客服等,,讓員工上手嘗試,,慢慢發(fā)掘大模型的能力,對大模型逐漸熟悉,,之后再將大模型與業(yè)務(wù)進(jìn)行深度融合。這樣大模型的發(fā)展才能可控易用,。
企業(yè)級場景要打造“安全可信,、可控易用”的專有大模型,,我們在實踐過程中也總結(jié)了一些心得,需要堅持五個原則,,包括:安全原則,,企業(yè)級應(yīng)用必須是安全的大模型;可信原則,,大模型要解決準(zhǔn)確性,、實時性的短板問題;可控原則,,堅持把大模型定位在輔助工具上,,確保人始終在業(yè)務(wù)決策的回路上;易用原則,,這里面“數(shù)字人”,、“數(shù)字員工”有很大的想象空間;最后是普惠原則,,要讓每個人都能用起來,。時間關(guān)系,,這里我想重點分享一下易用原則。
人工智能的發(fā)展要“以人為本”,,大模型不能引發(fā)大規(guī)模裁員,,而是要幫助企業(yè)員工提升能力和效率,,成為易用的工具,,讓每個普通員工都能真正用起來,。因此我認(rèn)為,,未來面向企業(yè),數(shù)字員工會成為非常重要的一個概念,。相比和機(jī)器進(jìn)行復(fù)雜的交互,,與“人”對話更符合我們的日常習(xí)慣,,數(shù)字員工將大大降低大模型的使用門檻。未來也不只企業(yè)老板能擁有數(shù)字員工做助理,,每個企業(yè)員工都能有若干數(shù)字助手,,比如法務(wù)助理、財務(wù)助理,、市場助理,,來協(xié)助創(chuàng)作、策劃,、分析,、總結(jié)等日常工作。
最后我想說,,人工智能大模型這場工業(yè)革命已經(jīng)到來,,未來大模型在各個城市、各個行業(yè),、各個企業(yè)里將得到充分應(yīng)用,,市場的機(jī)會也才剛剛開始。360也將發(fā)揮過往在人工智能領(lǐng)域積累的經(jīng)驗和優(yōu)勢,,幫助各地構(gòu)建“安全可信,、可控易用”的大模型,為產(chǎn)業(yè)數(shù)字化轉(zhuǎn)型到智能化升級,,貢獻(xiàn)自己的一份力量,。
謝謝大家!

就是“舔”,!張雪峰稱所有文科專業(yè)都叫服務(wù)業(yè) 驚爆言論引發(fā)網(wǎng)友爭議

用人單位倒閉退休怎么辦,?官方解讀

一圖讀懂 流感流行季來了 現(xiàn)在接種疫苗晚不晚?

廣東男籃官宣:易建聯(lián)9號球衣12月29日退役

美國和臺灣地區(qū)軍事聯(lián)系加強(qiáng),,中方該如何應(yīng)對,?解放軍將領(lǐng)答記者

馬克龍:反對“雙標(biāo)”對待巴以
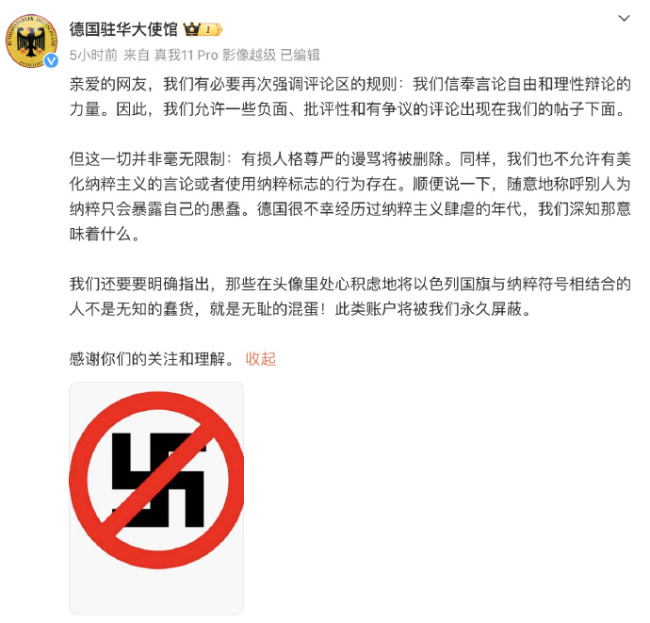
胡錫進(jìn):德駐華大使館爆粗口拉低國格

孫女說抑郁了奶奶回復(fù)霸氣又暖心:不開心就不出去 奶奶有錢給你花

寧波和爺爺奶奶在車棚住11年的女孩有了自己房間
就是“舔”,!張雪峰稱所有文科專業(yè)都叫服務(wù)業(yè) 驚爆言論引發(fā)網(wǎng)友爭議

巴勒斯坦總統(tǒng)阿巴斯:以色列政府越過所有紅線,應(yīng)得到懲罰

貨車司機(jī)在解清帥尋子海報標(biāo)注已回家

以色列的“有限地面進(jìn)攻”包含哪些手段,?
一圖讀懂 流感流行季來了 現(xiàn)在接種疫苗晚不晚,?

他成了所有學(xué)生的“公敵”,,還因此融到了350萬美金

臺積電放棄進(jìn)駐桃園,被綠營說成“被市長趕走”,,桃園市政府反駁

歐盟外長:不要“雙標(biāo)”,以色列停止向加沙供水違反國際法

馬來西亞總理:挺巴勒斯坦會激起西方“反彈風(fēng)險”,,但我別無選擇

王健林到底多缺錢?連曾經(jīng)的首富都吃不消了

鄭州最高氣溫破1991年以來同期紀(jì)錄,!持續(xù)強(qiáng)冷空氣來襲未來將迎大幅降溫

91歲老人生日給5個子女每家5萬紅包

泰國新任防長:潛艇擱置 改買中國護(hù)衛(wèi)艦

玩脫了!南方女孩在東北舔鐵舌頭被凍住 朋友邊笑邊澆熱水解救

加沙燃料告急 聯(lián)合國救濟(jì)機(jī)構(gòu)或停止運作

崔天凱:美方提出“小院高墻”,,讓人想起“坐井觀天”

“杰森·斯坦森在汽車機(jī)蓋上貼巴勒斯坦國旗”視頻瘋傳,土媒:說法不實

以色列總理:將全速推進(jìn)戰(zhàn)事

巴以沖突11天逾30萬名兒童被迫離開家園 沙地帶衛(wèi)生部門稱醫(yī)療資源已將枯竭

袁婭維居然免費請粉絲看首唱會,,姐是什么神仙

酷炫,!電力局用激光炮修剪樹枝火遍全網(wǎng) 研發(fā)公司回應(yīng):視頻里加了特效

必須支持聯(lián)合國在巴以問題上發(fā)揮更大作用
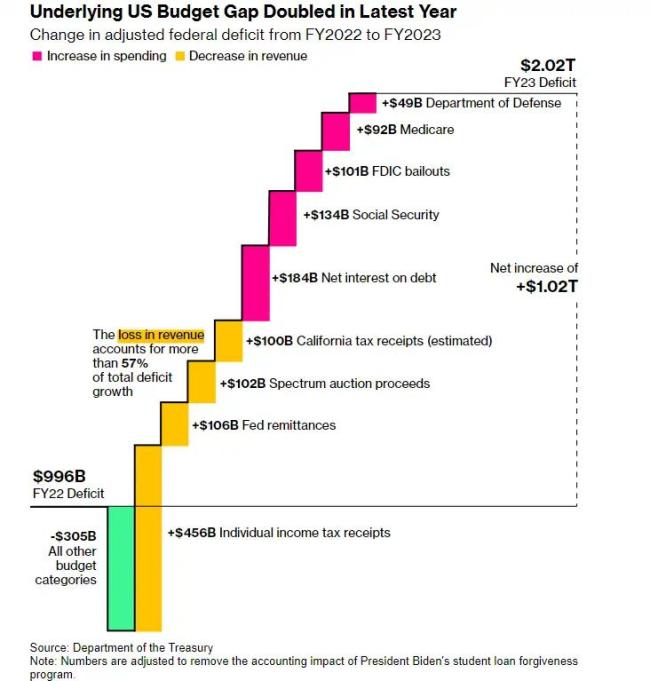
美財政軌跡掀起恐慌潮,2萬億美元的赤字將成新常態(tài),?
用人單位倒閉退休怎么辦,?官方解讀

辟謠,!大衣哥朱之文否認(rèn)在北京買豪宅:我沒有搬離朱樓村
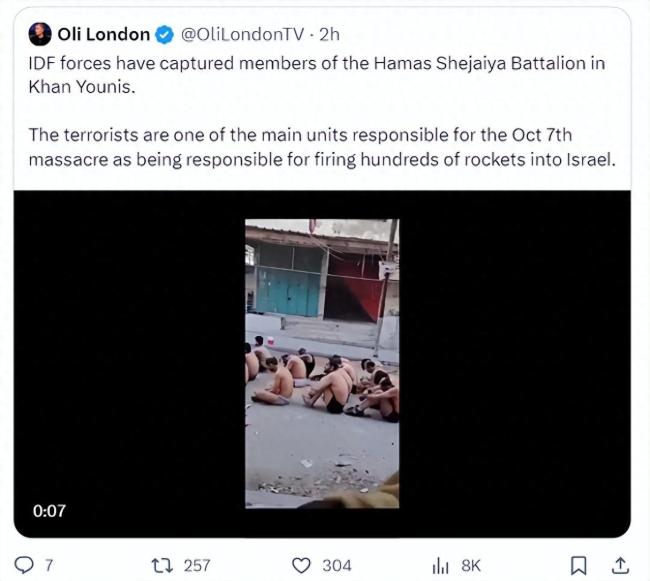
海水漫灌逼出大批哈馬斯投降是真嗎?視頻真實性遭網(wǎng)友質(zhì)疑
相關(guān)新聞
尼山對話聚焦人工智能 周鴻祎:垂直大模型大有可為
中國經(jīng)濟(jì)網(wǎng)曲阜6月26日訊(記者李方)6月26日,,世界互聯(lián)網(wǎng)大會數(shù)字文明尼山對話在山東濟(jì)寧曲阜開幕,。
2023-06-26 17:50:45尼山對話聚焦人工智能周鴻祎評價ChatGPT 大模型的發(fā)展剛剛開始,不會被OpenAI一統(tǒng)江山
2023-11-10 11:33:44周鴻祎評價ChatGPT周鴻祎天價離婚案后續(xù):4.47億股過戶 縮水逾20億
2023-06-07 10:01:08周鴻祎天價離婚案后續(xù)周鴻祎回應(yīng)360廣告多:商業(yè)模式奇葩只能依賴廣告
11月28日,新東方創(chuàng)始人俞敏洪在個人公眾號,,更新了與360公司創(chuàng)始人,、董事長兼CEO周鴻祎的采訪對話。
2023-11-29 14:42:13周鴻祎回應(yīng)360廣告多馬斯克xAI發(fā)布首款大模型:將顛覆社交媒體互動
2023-11-06 14:51:30馬斯克xAI發(fā)布首款大模型中國自主研發(fā)的人工智能大模型首次向公眾開放服務(wù)
2023-09-03 16:51:08中國自主研發(fā)的人工智能大模型首次向公眾開放服務(wù)