清華團(tuán)隊(duì)國(guó)產(chǎn)"Sora"火了:16秒高清視頻一鍵生成

國(guó)內(nèi)新發(fā)布的AI視頻生成模型“Vidu”引起了廣泛關(guān)注,這款由生數(shù)科技與清華大學(xué)合作推出的產(chǎn)品,能夠在一鍵操作下生成16秒長(zhǎng),、1080p高清的視頻內(nèi)容。Vidu的特別之處在于其生成的視頻不僅時(shí)長(zhǎng)顯著,而且在畫(huà)面連續(xù)性,、鏡頭運(yùn)用、時(shí)空一致性和物理規(guī)律模擬上接近國(guó)際頂尖水平Sora,,甚至能創(chuàng)造出現(xiàn)實(shí)中不存在的超現(xiàn)實(shí)主義場(chǎng)景,,這些都是當(dāng)前大多數(shù)視頻生成模型難以企及的。
在短短兩個(gè)月內(nèi),,Vidu的開(kāi)發(fā)團(tuán)隊(duì)實(shí)現(xiàn)了這些技術(shù)突破,。相較于同類(lèi)技術(shù),Vidu的視頻不再是簡(jiǎn)單的動(dòng)態(tài)圖片延展,,而是具備了豐富的鏡頭語(yǔ)言,,如轉(zhuǎn)場(chǎng)、追焦和長(zhǎng)鏡頭效果,,能夠講述連貫的故事,,提升了視頻的敘事性和觀(guān)賞性。它在保持時(shí)間與空間一致性上的表現(xiàn)也頗為出色,,使得視頻中的動(dòng)作和場(chǎng)景變換流暢自然,,減少了以往AI生成視頻中常見(jiàn)的敘事斷裂和邏輯錯(cuò)誤。
Vidu對(duì)真實(shí)物理世界的模擬也是其亮點(diǎn)之一,,能夠準(zhǔn)確展現(xiàn)物體運(yùn)動(dòng)及其相互作用,,如塵土飛揚(yáng)、光影變化等,,這些細(xì)節(jié)極大地增強(qiáng)了視頻的真實(shí)感,。更令人興奮的是,Vidu能夠想象并生成現(xiàn)實(shí)中不存在的場(chǎng)景,,如畫(huà)室中的帆船與海浪,,以及“魚(yú)缸女孩”這類(lèi)超現(xiàn)實(shí)主題,為創(chuàng)意內(nèi)容提供了無(wú)限可能,,拓寬了藝術(shù)表達(dá)的界限,。
此外,Vidu還展現(xiàn)了對(duì)中國(guó)元素的理解與應(yīng)用,,成功生成包含熊貓,、龍、宮殿等特色場(chǎng)景的視頻,,展示了其文化適應(yīng)性和多樣性,。
Vidu快速發(fā)展的“秘籍”在于選擇了正確的技術(shù)路線(xiàn)和堅(jiān)實(shí)的工程化基礎(chǔ)。它基于自研的U-ViT架構(gòu),該架構(gòu)融合了Transformer與Diffusion模型的優(yōu)勢(shì),,能夠直接連續(xù)地從文本生成視頻,,避免了插幀和拼接帶來(lái)的畫(huà)面僵硬問(wèn)題。同時(shí),,團(tuán)隊(duì)在圖文任務(wù)中積累的經(jīng)驗(yàn)和技術(shù)成果,,如大規(guī)模訓(xùn)練的可擴(kuò)展性和并行化訓(xùn)練策略,也加速了Vidu在視頻生成領(lǐng)域的進(jìn)步,。
生數(shù)科技,,這支擁有清華背景的團(tuán)隊(duì),以其在多模態(tài)大模型領(lǐng)域的深厚研究基礎(chǔ)和一系列學(xué)術(shù)成就,,支撐起了Vidu的技術(shù)創(chuàng)新,。他們不僅在國(guó)內(nèi)外頂級(jí)會(huì)議上多次發(fā)表論文,提出的多項(xiàng)技術(shù)也被國(guó)際前沿機(jī)構(gòu)采納,,顯示出強(qiáng)勁的研發(fā)實(shí)力和行業(yè)影響力,。自成立以來(lái),生數(shù)科技憑借其在多模態(tài)大模型賽道的突出表現(xiàn),,獲得了多家知名機(jī)構(gòu)的投資,,成為國(guó)內(nèi)該領(lǐng)域估值領(lǐng)先的創(chuàng)業(yè)團(tuán)隊(duì)。

媒體:英格蘭隊(duì)差點(diǎn)成“三喵軍團(tuán)”

月薪八千房租1100會(huì)很貴嗎,?

雷軍首爆新機(jī)進(jìn)度 網(wǎng)友:拭目以待
存在風(fēng)險(xiǎn),、失去信心……美國(guó)核霸權(quán)開(kāi)始動(dòng)搖了?

首次曝光:美國(guó)提供了1.4萬(wàn)枚

這個(gè)95后,會(huì)成為下一任法國(guó)總理嗎

美國(guó)究竟有多少核彈頭,?最新數(shù)據(jù)
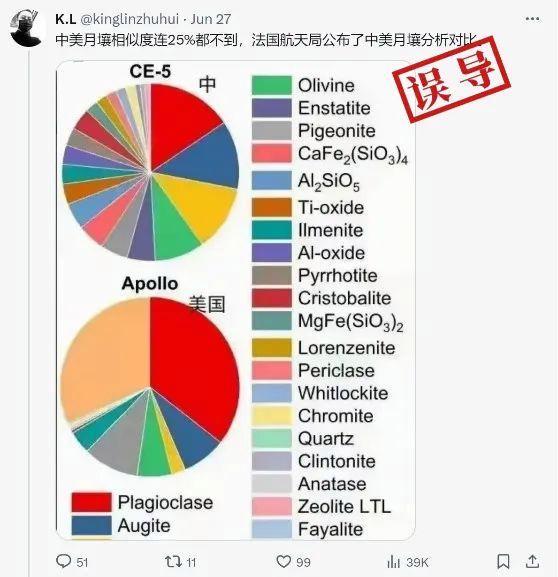
中美的月壤成分不像同一個(gè)月球,?

破解俄羅斯“戰(zhàn)場(chǎng)神器”,,西方給出危險(xiǎn)“解藥”
雷軍首爆新機(jī)進(jìn)度 網(wǎng)友:拭目以待

法國(guó)“屏住呼吸”舉行議會(huì)選舉,!美媒:此次選舉可能“撼動(dòng)歐盟與北約”

山城重慶夜景迷人 萬(wàn)家燈火映山谷

周杰倫囑咐林書(shū)豪:賽前別聽(tīng)教練要聽(tīng)我的歌 運(yùn)球帥氣最重要

張志杰離世尚未明確病因 羽壇新星隕落原因成謎

衛(wèi)星影像顯示山東艦抵菲附近海域,外媒猜測(cè)有“威懾”之意,?軍事專(zhuān)家解讀

限制北約收集情報(bào),,威脅擊落美無(wú)人機(jī),!俄軍考慮在黑海設(shè)立禁飛區(qū)

美媒炒作:盟友不是信不過(guò)拜登,,質(zhì)疑聲太多恐“便宜”了中俄

普京宣布“大消息”!西方密集關(guān)注
媒體:英格蘭隊(duì)差點(diǎn)成“三喵軍團(tuán)”

快船希望凱·瓊斯留在球隊(duì) 執(zhí)行選項(xiàng)雖拒,,仍盼續(xù)前緣

張志杰離世病因尚未明確 羽壇新星隕落

17歲國(guó)羽小將去世 目前未明確病因

俄羅斯“生病”,美國(guó)吃藥,?

王星越直播比心手都在抖 健康隱憂(yōu)引關(guān)注
上海暴雨陳赫家漏成水簾洞 明星住宅也遭殃

匈牙利接任歐盟輪值主席國(guó)前夕,,歐爾班發(fā)文:歐盟領(lǐng)導(dǎo)層想與俄開(kāi)戰(zhàn)
月薪八千房租1100會(huì)很貴嗎,?

如何結(jié)束俄烏沖突,?澤連斯基最新表態(tài)

“買(mǎi)家秀”,!塞爾維亞首次公開(kāi)展示紅旗-17AE防空系統(tǒng)

美國(guó)大選,出現(xiàn)三個(gè)重大變化

馬克龍賭輸了,,現(xiàn)在后果很?chē)?yán)重

專(zhuān)家稱(chēng)張志杰猝死錯(cuò)過(guò)3個(gè)救命環(huán)節(jié) 賽場(chǎng)急救疏漏引熱議

大選辯論后,,拜登陷入“勸退”漩渦,!美媒刊文:“他已不是4年前的他了”

財(cái)政部下達(dá)4500萬(wàn)支持公路應(yīng)急搶通,!

店家售賣(mài)明星仿真面罩聲稱(chēng)高度還原 萬(wàn)元定制引爭(zhēng)議
相關(guān)新聞
清華團(tuán)隊(duì)國(guó)產(chǎn)“Sora”火了 視頻注入特有中國(guó)元素
2024-04-28 08:53:33清華團(tuán)隊(duì)國(guó)產(chǎn)“Sora”火了斯坦福AI團(tuán)隊(duì)抄襲國(guó)產(chǎn)大模型?連識(shí)別“清華簡(jiǎn)”都抄了,!清華系團(tuán)隊(duì)回應(yīng)
近期,,人工智能領(lǐng)域內(nèi)的一起學(xué)術(shù)誠(chéng)信事件引起了全球科技行業(yè)的密切關(guān)注。
2024-06-04 15:54:36斯坦福AI團(tuán)隊(duì)抄襲國(guó)產(chǎn)大模型,?連識(shí)別“清華簡(jiǎn)”都抄了,!清華系團(tuán)隊(duì)回應(yīng)新模型Vidu直逼Sora,生數(shù)科技:還說(shuō)“中國(guó)sora”就太沒(méi)想象力了 國(guó)產(chǎn)AI視頻新飛躍
2024-04-28 18:58:48新模型Vidu直逼Sora斯坦福團(tuán)隊(duì)道歉 承認(rèn)抄襲國(guó)產(chǎn)模型,,承諾撤下作品
2024-06-04 13:11:38斯坦福團(tuán)隊(duì)道歉斯坦福AI團(tuán)隊(duì)被質(zhì)疑抄襲國(guó)產(chǎn)大模型 涉事作者正式道歉
2024-06-04 15:03:19斯坦福AI團(tuán)隊(duì)被質(zhì)疑抄襲國(guó)產(chǎn)大模型又火了,!國(guó)產(chǎn)機(jī)器狗,背上了槍沖鋒,!亮相聯(lián)演展實(shí)力
2024-05-26 22:48:34又火了,!國(guó)產(chǎn)機(jī)器狗