一道小學題難倒海內外8個大模型 AI的數(shù)學困境

一道小學題難倒海內外8個大模型
一些簡單的數(shù)學問題近期挑戰(zhàn)了一群先進的AI大模型,,引發(fā)了業(yè)界關注,。在對比9.11與9.9的大小時,盡管阿里通義千問,、百度文心一言,、Minimax及騰訊元寶能夠給出正確答案,,但包括ChatGPT-4o在內的其他8個知名大模型卻犯下了錯誤,它們大多基于小數(shù)點后的數(shù)字進行直接比較,,忽略了整數(shù)部分的重要性,。這一現(xiàn)象反映出了當前大模型在數(shù)學處理能力上的局限。
該話題起因于一個綜藝節(jié)目的投票率爭議,,進而激發(fā)了公眾對AI處理基礎數(shù)學問題能力的好奇與探討,。測試結果顯示,即便是調整提問語境明確為數(shù)學領域,,部分大模型仍無法給出準確答案,。不過,當被指出錯誤后,,大多數(shù)模型能夠自我糾正并提供正確解答,顯示出一定的學習與適應能力,。
這一現(xiàn)象背后的根源在于大模型的設計偏向于處理語言和文本數(shù)據(jù),,而非數(shù)學運算和邏輯推理。語言模型擅長捕捉文本間的關聯(lián)性,,這使得它們在文學創(chuàng)作等方面表現(xiàn)出色,,但面對需要嚴密邏輯推理的數(shù)學問題時則顯得力不從心,。專家指出,要提高大模型的理科能力,,除了豐富它們的世界知識外,,還需要通過特定的訓練使其掌握推理演繹技能。
另一個技術挑戰(zhàn)涉及到分詞器(Tokenizer)對數(shù)字的處理方式,,它可能錯誤地將連續(xù)數(shù)字分割,,影響模型對數(shù)值的正確理解。盡管如此,,隨著技術的進步和針對性語料的增加,,模型在數(shù)學處理方面的能力有望逐步提升。
大模型的復雜推理能力是其在金融,、工業(yè)等領域實現(xiàn)可靠應用的關鍵,。未來,如何在模型訓練中融入更多結構化,、專業(yè)化的數(shù)據(jù),,特別是在數(shù)學和邏輯推理方面的訓練,將是提升大模型實用價值和信賴度的重要方向,。
一道小學題難倒海內外8個大模型,。

英超揭幕戰(zhàn)孫興慜被換下原因揭曉!:換人調整策略成疑

場面壯觀!馬競新援亮相大都會球場 備受球迷歡迎 能否閃耀西甲賽場拭目以待

老人坐三輪車上昏厥 司機打120

俄烏在庫爾斯克戰(zhàn)事“白熱化”,,俄烏“決勝”是否在此?

俄海軍“瓦良格”號編隊返航通過第一島鏈,遠航已滿7個月

日本民間團體代表:沖繩不需要美軍基地
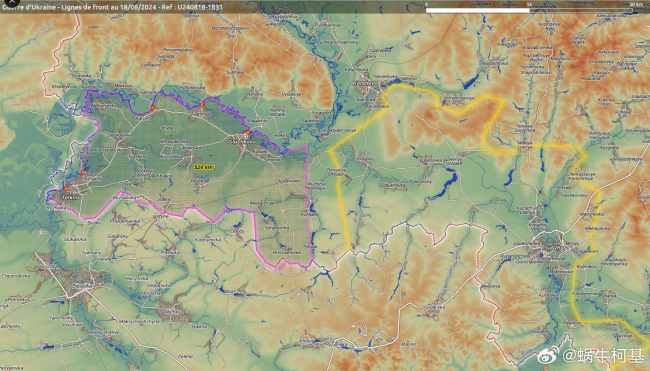
烏軍進攻庫爾斯克 讓俄軍加速進攻頓涅茨克
場面壯觀,!馬競新援亮相大都會球場 備受球迷歡迎 能否閃耀西甲賽場拭目以待

獻血證過期不能用血,?醫(yī)院回應 血站規(guī)定引爭議

劉曉慶 早期愛女第一人 演繹時代女性覺醒

專家談黑神話悟空對行業(yè)的影響 國產3A游戲新紀元

俄軍新建三個集團軍,準備怎么用,?

機器鷹,、機器魚……軍用仿生機器人嶄露頭角

中方駁斥美翻炒“中國核威脅論”:美國才是全球最大的核威脅、戰(zhàn)略風險的制造者
菲律賓,,要為美國兩肋插刀了
老人坐三輪車上昏厥 司機打120

布林肯結束中東之行,未能推動加沙?;饏f(xié)議達成

俄媒:普京2011年以來首次視察俄車臣共和國,,卡德羅夫在機場迎接

駐美使館提醒留學生租房換匯風險 務必謹慎操作

郭剛堂希望人販子被判死刑 期待二審"頂格處理

“不死鳥”的后代:漫談美海軍列裝新超遠程空空導彈

日印“2+2”對話硬扯中國,專家:兩國有權深化雙邊關系,,但不應針對第三方

黑悟空”爆了,!一大波股票瘋漲:游戲熱潮席卷A股

再度崛起:曼城連簽3名日本國腳,女足梯隊打造要靠“亞洲支撐”

NBA一夜動態(tài): 太陽連裁兩名球員 勇士87歲名宿逝世庫里發(fā)聲追悼

畫面曝光,!“美軍事人員現(xiàn)身庫爾斯克”

俄烏就談判問題激烈交鋒:俄外長稱目前不可能恢復對話,,烏總統(tǒng)稱正在實現(xiàn)戰(zhàn)略目標

0-1, 0-2! 槍手遇苦主, 5次翻車, 賽季首敗或誕生, 難與曼城爭冠

處暑是秋天第2個節(jié)氣 滋陰潤肺正當時

以色列代表埃爾丹再出暴論:應把聯(lián)合國大樓從地球上抹去

美團哈啰等電動車退出武漢大學 新運營商及計費方案公布

日本超20萬人要求停止核污水排海 安全疑慮加劇

突發(fā)! 太陽連續(xù)裁掉2人! 庫里更新簡介, 哈登能力值創(chuàng)12年新低

美國批準對韓出售36架“阿帕奇”直升機
英超揭幕戰(zhàn)孫興慜被換下原因揭曉!:換人調整策略成疑
相關新聞
湯家鳳評免單數(shù)學題難倒眾人 送分題反成難題啟示錄
2024-05-07 09:20:50湯家鳳評免單數(shù)學題難倒眾人準大一賬單”難倒家長:理性消費待培養(yǎng)
高考結束后,,隨著成績的揭曉和志愿填報的完成,,高三畢業(yè)生們迎來了長達兩個月的假期,準備迎接大學生活,。他們規(guī)劃著如何充實這段時間,,如考取駕照、安排暑期旅行,、學習個人形象管理等
2024-07-22 18:07:10“準大一賬單”難倒家長數(shù)學競賽6題做1題 選手直言難度爆表
2024-06-24 13:31:38數(shù)學競賽6題做1題阿里云發(fā)布開源模型Qwen2,,宣稱性能超美國最強開源模型Llama3-70B
6月7日,,阿里云在技術博客上宣布了一個重要進展:他們發(fā)布了名為Qwen2-72B的開源模型,這款模型在全球范圍內以其卓越的性能脫穎而出
2024-06-07 10:49:47阿里云發(fā)布開源模型Qwen2斯坦福AI團隊承諾撤下相關模型 因抄襲國內開源模型致歉
2024-06-04 15:37:44斯坦福AI團隊承諾撤下相關模型OpenAI年收益34億美元,卻遭CTO揭底:最新模型與免費模型差距不大
2024-06-13 21:54:05卻遭CTO揭底:最新模型與免費模型差距不大








