智源研究院“百模”評(píng)測結(jié)果:字節(jié)跳動(dòng)多項(xiàng)第一

智源研究院百模評(píng)測結(jié)果,。2024年12月19日,,智源研究院舉辦了一場秋冬評(píng)測發(fā)布會(huì),其中一場大模型辯論賽引人注目,。參與辯論的大模型能夠引用經(jīng)典文獻(xiàn),,并根據(jù)對(duì)手的論點(diǎn)進(jìn)行反擊。盡管這些大模型的表現(xiàn)與真人辯手仍有差距,,但這場辯論展示了大模型的能力,。
同一天,智源研究院發(fā)布了國內(nèi)外100多個(gè)開源和商業(yè)閉源的語言,、視覺語言,、文生圖、文生視頻及語音語言大模型的綜合及專項(xiàng)評(píng)測結(jié)果。相比5月份的評(píng)測,,此次新增了數(shù)據(jù)處理,、高級(jí)編程和工具調(diào)用能力的任務(wù),還首次增加了面向真實(shí)金融量化交易場景的應(yīng)用能力評(píng)估,,以及基于模型辯論的對(duì)比評(píng)估方式,,以深入分析模型的邏輯推理、觀點(diǎn)理解和語言表達(dá)能力,。
此次評(píng)測發(fā)現(xiàn),,2024年下半年大模型發(fā)展呈現(xiàn)三個(gè)特點(diǎn):一是廠商更注重提升大模型的綜合能力和實(shí)用性;二是多模態(tài)模型迅速發(fā)展,,新廠商和新模型不斷涌現(xiàn),,而語言模型的發(fā)展逐漸放緩;三是大模型開源生態(tài)中出現(xiàn)了新的貢獻(xiàn)者,。
在文本,、語音、圖片,、視頻理解與生成方面,,評(píng)測結(jié)果顯示,國內(nèi)頭部語言模型在復(fù)雜場景任務(wù)中的表現(xiàn)仍落后于國際一流模型,。字節(jié)跳動(dòng)Doubao-pro-32k-preview和百度ERNIE 4.0 Turbo在中文能力主觀評(píng)測中名列前茅,,而在客觀評(píng)測中,OpenAI o1-mini-2024-09-12和Google Gemini-1.5-pro-latest位列前茅,。
對(duì)于視覺語言多模態(tài)模型,,雖然架構(gòu)趨同,但表現(xiàn)各異,。一些較好的開源模型在圖文理解任務(wù)上縮小了與閉源模型的差距,,但仍需提升長尾視覺知識(shí)和文字識(shí)別能力。OpenAI GPT-4o-2024-11-20和字節(jié)跳動(dòng)Doubao-Pro-Vision-32k-241028表現(xiàn)突出,。

日本球迷:全盛恒大亞洲無敵,!中國男足受益 發(fā)免費(fèi)門票讓中國人看球

軍大衣不合身爺爺手寫千字退貨申請 認(rèn)真態(tài)度獲網(wǎng)友點(diǎn)贊

NBA戰(zhàn)力榜:雷霆超騎士登頂 火箭升至第五

印度推遲太空對(duì)接實(shí)驗(yàn) 需更多地面驗(yàn)證

布林肯剛到韓國,公調(diào)處多名官員被檢舉 美訪問時(shí)機(jī)引猜測

烏國防情報(bào)總局稱已接收美援助的“哈澤德”無人機(jī),,意味著什么,?

曼聯(lián)6000萬鐵腰最后一傳盡顯求勝欲,!每場必須這么踢,復(fù)興就有望 烏加特成中場明星

特朗普前私人律師藐視法庭 未提交所需文件和資產(chǎn)

官方通報(bào)女子吃包子稱有甲醛索賠 非市監(jiān)局人員將依法處理

特朗普辟謠關(guān)稅政策美股巨震 市場情緒波動(dòng)顯著
騰訊,、寧德時(shí)代:是一個(gè)錯(cuò)誤 企業(yè)否認(rèn)軍事關(guān)聯(lián)
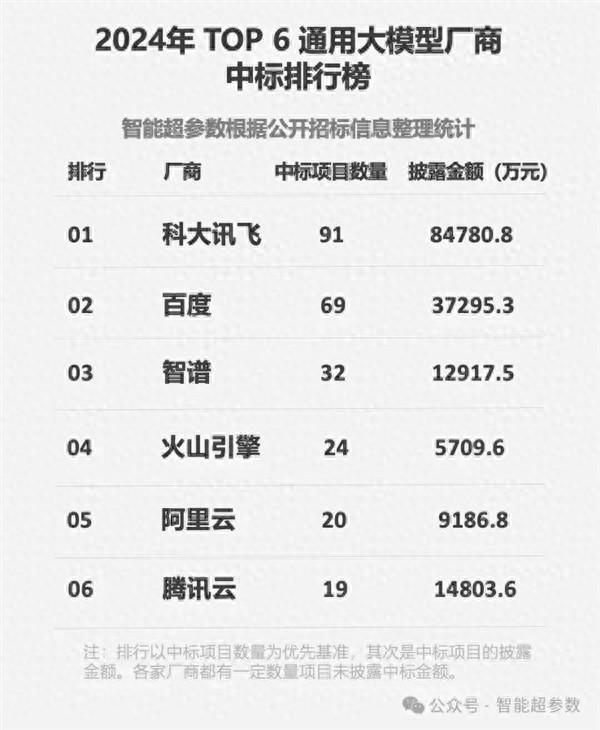
2024大模型年度“標(biāo)王”誕生,!科大訊飛中標(biāo)金額超2-6名之和 斷層領(lǐng)先市場
特魯多宣布辭職后,特朗普快速回應(yīng) 提及“美加合并說”
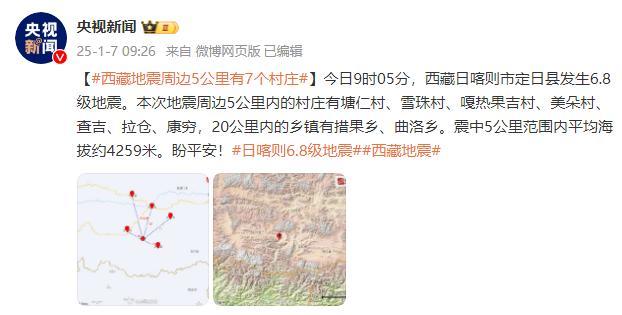
西藏地震周邊5公里有7個(gè)村莊 盼平安!
NBA戰(zhàn)力榜:雷霆超騎士登頂 火箭升至第五

烏軍突襲多所核電站
泰國文華律所談王星失蹤案進(jìn)展 家屬展開營救

美國參議院邀請?zhí)乩势臻_會(huì) 內(nèi)閣提名待確認(rèn)

朝鮮試射新型高超音速中遠(yuǎn)程彈道導(dǎo)彈
特朗普稱華盛頓郵報(bào)報(bào)道不實(shí) 假新聞再引爭議
醫(yī)生得甲流一周變病毒性肺炎 病情惡化引關(guān)注

騰訊寧德時(shí)代回應(yīng)被列入美國防部清單:是一個(gè)錯(cuò)誤

這些人避免食用臘八蒜
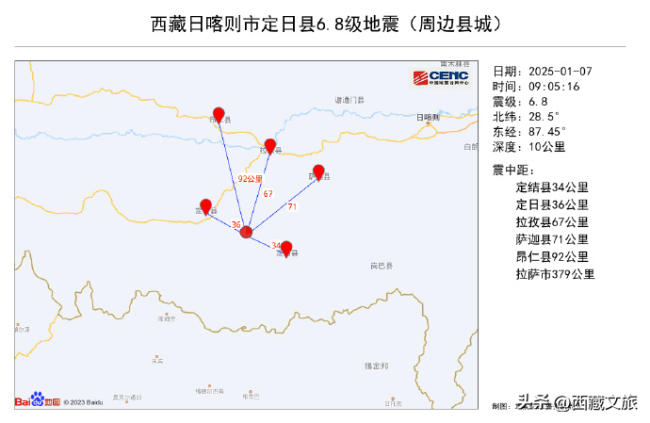
西藏那曲市尼瑪縣4.6級(jí)地震 震源深度10千米

我國冰雪旅游收入或超6300億元 冰雪熱持續(xù)升溫

美欲將核威懾引入亞太

民眾黨號(hào)召八千新黨員上街游行 抗議司法不公
軍大衣不合身爺爺手寫千字退貨申請 認(rèn)真態(tài)度獲網(wǎng)友點(diǎn)贊

賀希寧出戰(zhàn)43分鐘拿16分9板4助 手感一般難救主

大反轉(zhuǎn),!離岸人民幣連續(xù)升穿7.34和7.33關(guān)口,,發(fā)生了什么?特朗普關(guān)稅政策不及預(yù)期

烏官員稱烏軍控制區(qū)域擴(kuò)大 庫爾斯克方向進(jìn)展顯著

尤文6000萬巨星丑聞:1人帶6應(yīng)召女郎開房 在走廊徘徊找不到房間 球迷爆料引發(fā)熱議
大范圍降溫形勢確定 江南干燥變濕雨雪待定 冷空氣與南支槽共同作用

車管所民警一次收幾十元微信紅包 最后貪47萬 風(fēng)腐同查整治見效
日本球迷:全盛恒大亞洲無敵,!中國男足受益 發(fā)免費(fèi)門票讓中國人看球
相關(guān)新聞
李彥宏批“百模大戰(zhàn)”:“卷模型”造成巨大的算力浪費(fèi)
2024-07-04 15:59:30李彥宏批“百模大戰(zhàn)”:“卷模型”造成巨大的算力浪費(fèi)業(yè)內(nèi)評(píng)測東風(fēng)猛士917
業(yè)內(nèi)評(píng)測東風(fēng)猛士917
2024-06-28 13:22:57業(yè)內(nèi)評(píng)測東風(fēng)猛士917如何評(píng)價(jià)vivoX200 旗艦級(jí)新體驗(yàn)評(píng)測
2024-10-15 14:17:50如何評(píng)價(jià)vivoX200影視颶風(fēng)回應(yīng)手機(jī)眩光評(píng)測爭議
2024-10-24 13:40:46影視颶風(fēng)回應(yīng)手機(jī)眩光評(píng)測爭議試駕評(píng)測奇瑞瑞虎8L 性能舒適安全新體驗(yàn)
今年上半年,,奇瑞品牌在SUV市場占有率中拔得頭籌,瑞虎家族對(duì)此貢獻(xiàn)顯著
2024-08-08 22:51:37試駕評(píng)測奇瑞瑞虎8L榮耀Magic7 Pro影像評(píng)測 AI加持更出色
2024-11-11 19:46:13榮耀Magic7








