美學(xué)者解析DeepSeek技術(shù)原理 揭秘低成本高效模型背后的秘密

2025年蛇年春節(jié)前夕,DeepSeek徹底出圈,。1月27日,,DeepSeek應(yīng)用登頂蘋果美國地區(qū)應(yīng)用商店免費(fèi)App下載排行榜,,在美區(qū)下載榜上超越了ChatGPT。同日,,蘋果中國區(qū)應(yīng)用商店免費(fèi)榜顯示,DeepSeek成為中國區(qū)第一。
浙江大學(xué)計(jì)算機(jī)博士,、美國南加州大學(xué)訪問學(xué)者傅聰解析了DeepSeek成功背后的技術(shù)原理。業(yè)界對(duì)DeepSeek的喜愛主要集中在三個(gè)方面:技術(shù)層面,,DeepSeek背后的DeepSeek-V3及新推出的DeepSeek-R1兩款模型分別實(shí)現(xiàn)了與OpenAI 4o和o1模型相當(dāng)?shù)哪芰?;成本方面,這兩款模型的成本僅為OpenAI 4o和o1模型的十分之一左右,;此外,,DeepSeek還開源了這些模型,讓更多的AI團(tuán)隊(duì)能夠基于先進(jìn)且低成本的模型開發(fā)更多AI原生應(yīng)用,。
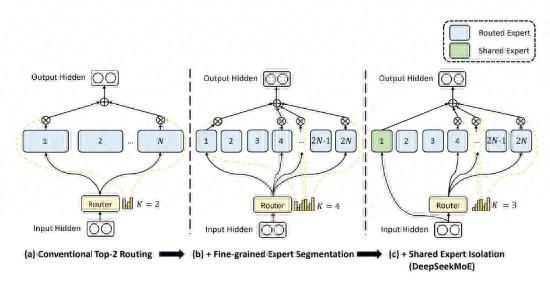
關(guān)于如何實(shí)現(xiàn)模型成本降低同時(shí)保證效果,,傅聰表示,DeepSeek通過Multi-Head latent Attention(MLA)和DeepSeek MOE架構(gòu)節(jié)省了大量的顯存,,從而高效利用底層算力,,以更低的成本訓(xùn)練出更出色的模型。具體而言,,DeepSeek采用了一種不需要輔助損失函數(shù)的專家加載均衡技術(shù),,確保每個(gè)token下少量專家網(wǎng)絡(luò)參數(shù)被激活時(shí),不同專家網(wǎng)絡(luò)能以更均衡的頻率被激活,。這種策略在DeepSeek V2版本中已經(jīng)驗(yàn)證有效,,并在6710億參數(shù)規(guī)模的DeepSeek V3中進(jìn)一步驗(yàn)證,,接近頭部玩家目前最好的商用模型參數(shù)規(guī)模。
DeepSeek還設(shè)計(jì)了一種“對(duì)偶流水線”機(jī)制,,通過極致的流水線調(diào)度,,將GPU用于數(shù)學(xué)運(yùn)算和通信相關(guān)的算力進(jìn)行并行隱藏,使得GPU幾乎不間斷地進(jìn)行運(yùn)算,,理論上可使GPU指令執(zhí)行流水線中的“氣泡”減少一半,。此外,DeepSeek限制了每個(gè)token發(fā)送到GPU集群節(jié)點(diǎn)的數(shù)量,,保持較低的通信開銷,,并應(yīng)用了FP8混合精度訓(xùn)練架構(gòu),靈活使用不同精度的數(shù)字表示,,加快計(jì)算速度并降低通信開銷,。
除了成本優(yōu)化,DeepSeek還提升了模型效果,。DeepSeek應(yīng)用了多token預(yù)測(cè)技術(shù),,使模型在訓(xùn)練時(shí)同時(shí)預(yù)測(cè)序列后面更遠(yuǎn)位置的token,增強(qiáng)了模型對(duì)未來感知能力,。真正幫助DeepSeek追趕o1的是最新模型DeepSeek-R1,,該模型幾乎單純使用強(qiáng)化學(xué)習(xí)技術(shù)進(jìn)行“后訓(xùn)練”,極大提升了推理能力,。R1模型通過學(xué)習(xí)CoT(思維鏈)的方式逐步推理得出結(jié)果,,而不是直接預(yù)測(cè)答案。這一方案驗(yàn)證了強(qiáng)化學(xué)習(xí)及inference time scaling law的可行性,,證明小模型也能通過CoT + RL大幅提升推理能力,,具備應(yīng)用場(chǎng)景落地潛力。R1的出現(xiàn)還將增加學(xué)界和產(chǎn)業(yè)界對(duì)合成數(shù)據(jù)的需求,。

過年坐車回家有哪些防暈車妙招 讓旅途更愉快安穩(wěn)

澤連斯基為何不想普京特朗普單獨(dú)談 擔(dān)心中國影響談判

DeepSeek推翻兩座大山 低成本訓(xùn)練引發(fā)行業(yè)巨變

美印第安納州總檢察長起訴當(dāng)?shù)鼐L 拒配合移民執(zhí)法

美國無人機(jī)為啥這么貴 高昂成本引發(fā)質(zhì)疑

尹錫悅會(huì)被判處死刑嗎 涉嫌“內(nèi)亂頭目”罪名成立,?

專家談歐盟計(jì)劃在格陵蘭島駐軍 地緣政治新焦點(diǎn)

實(shí)戰(zhàn)畫面揭示2000磅炸彈真實(shí)威力 十層高樓4秒鐘化為廢墟
比特幣和黃金又將重回歷史新高,誰才是有力的戰(zhàn)略儲(chǔ)備,? 美元走弱與政策推動(dòng)共助漲勢(shì)

學(xué)者:魯比奧把火燒向澤連斯基,,暫時(shí)凍結(jié)對(duì)烏克蘭的援助
DeepSeek推翻兩座大山 低成本訓(xùn)練引發(fā)行業(yè)巨變

業(yè)內(nèi):車企海外建廠并非唯一答案 多元化出海模式探索

伊能靜為婆婆慶祝生日 溫馨家庭情

高速公路出滬客流量已回落 春運(yùn)出行高峰平穩(wěn)度過
過年坐車回家有哪些防暈車妙招 讓旅途更愉快安穩(wěn)

戴偉浚:我沒事很快復(fù)出,,積極康復(fù)中

遼籃現(xiàn)身遼視春晚 4連冠承諾擲地有聲

好惡心,!寧波知名商場(chǎng)被集體吐槽! 地下車庫臟亂差引發(fā)熱議
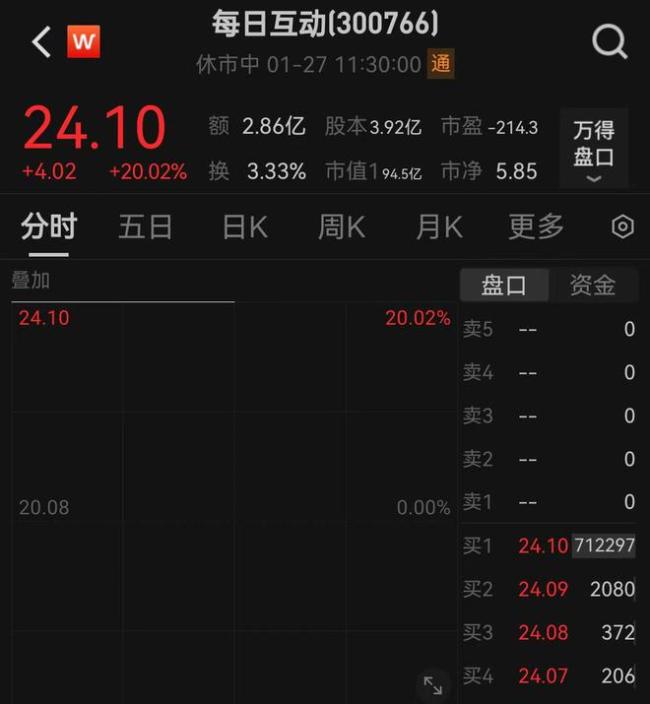
分析師:A股無DeepSeek直接相關(guān)標(biāo)的 概念股表現(xiàn)分化

南天湖的雪火爆全網(wǎng) 網(wǎng)友稱其為玩雪天花板

扎克伯格:AI方面我們需要政府幫助 探討科技未來與競(jìng)爭(zhēng)態(tài)勢(shì)

《異人之下2》豆瓣開分8.2分 口碑與熱度雙豐收

俄稱在烏陣地發(fā)現(xiàn)幾具被鎖士兵遺體 有遭受酷刑痕跡

馬斯克的政府效率部誕生一周干了啥 首周削減4.2億美元預(yù)算

李云霄鄭業(yè)成戲腔合唱白蛇傳 傳統(tǒng)與現(xiàn)代的完美交融

特朗普的“星際之門”計(jì)劃會(huì)失敗嗎 馬斯克公開質(zhì)疑
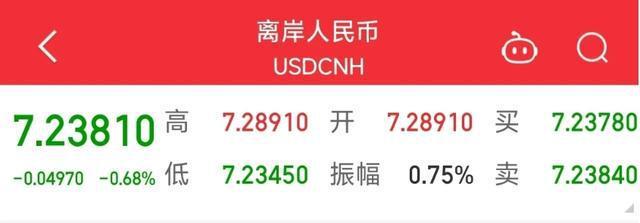
特朗普總統(tǒng)又反悔了,?但這次是好事,,中美貿(mào)易戰(zhàn)2.0可能不打了 金融市場(chǎng)迎來利好

第9艘055大驅(qū)將首航 解放軍海軍東海南海實(shí)戰(zhàn)演訓(xùn) 強(qiáng)化臨戰(zhàn)演練
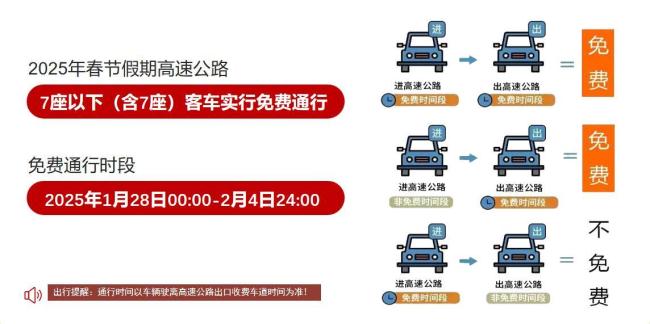
2025年浙江省高速公路春節(jié)出行服務(wù)指南來了!跨區(qū)域長途出行創(chuàng)歷史新高

專家談烏軍失守大諾沃西爾卡 俄軍三面包圍成功

《出走的決心》原型蘇敏離婚 38年終獲自由

菲律賓在南海能掀得起浪嗎 小人使壞徒勞無功
澤連斯基為何不想普京特朗普單獨(dú)談 擔(dān)心中國影響談判
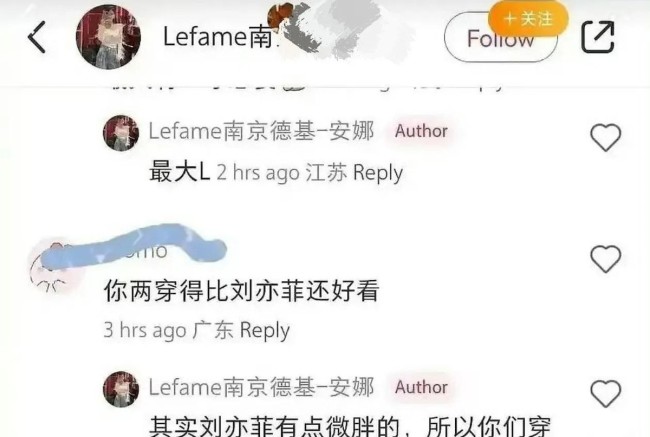
媒體評(píng)柜姐說劉亦菲微胖被辭退 職業(yè)操守引爭(zhēng)議

民進(jìn)黨為何不遺余力地推進(jìn)大罷免 手段卑劣引發(fā)爭(zhēng)議
相關(guān)新聞
美媒:DeepSeek如何威脅美國主導(dǎo)地位 低成本高效率挑戰(zhàn)硅谷
2025-01-27 10:50:53美媒DeepSeek被美國科技圈盯上了 技術(shù)黑馬崛起引發(fā)美國科技圈關(guān)注
2025-01-26 17:43:50DeepSeek被美國科技圈盯上了DeepSeek在美區(qū)下載榜超越ChatGPT 中美兩地旋風(fēng)式崛起
DeepSeek掀起的大模型旋風(fēng)在中美兩地愈演愈烈。1月27日,,蘋果App Store中國區(qū)免費(fèi)榜顯示,,DeepSeek登上首位
2025-01-28 03:14:39DeepSeek在美區(qū)下載榜超越ChatGPTDeepSeek登頂蘋果美區(qū)免費(fèi)下載榜 國產(chǎn)大模型崛起
2025-01-27 09:12:14DeepSeek登頂蘋果美區(qū)免費(fèi)下載榜實(shí)測(cè)DeepSeek做奧數(shù)題寫作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測(cè)DeepSeek做奧數(shù)題寫作文DeepSeek掀翻美科技股 英偉達(dá)大跌 AI競(jìng)爭(zhēng)格局生變
2025-01-27 22:02:59DeepSeek掀翻美科技股英偉達(dá)大跌