DeepSeek遭遇美國OpenAI新模型反擊 AI競賽再升級

中國AI模型DeepSeek引發(fā)了全球討論熱潮,,持續(xù)近半個月后,,美國OpenAI公司推出了新的AI推理模型o3-mini作為回應,。北京時間2月1日凌晨,,OpenAI CEO奧爾特曼在ChatGPT和API服務中發(fā)布了o3-mini。該模型的性能響應速度比之前的o1-mini提升了24%,,答案準確性也有所提高,。
目前,,ChatGPT免費用戶可以體驗一個有限速率的o3-mini版本,而Plus用戶可選擇更高智能版本o3-mini-high,;每月支付200美元的Pro用戶則可無限使用這兩個版本,。在API層面,o3-mini的價格比o1-mini便宜63%,,但仍比GPT-4o mini貴7倍左右,。
OpenAI表示,o3-mini的發(fā)布標志著高效能智能技術(shù)道路上的重要里程碑,。通過優(yōu)化科學,、技術(shù)和工程領(lǐng)域的推理能力,同時保持較低的成本,,高質(zhì)量AI技術(shù)變得更加平易近人,。
過去一周內(nèi),DeepSeek R1和V3兩款開源AI模型顛覆了世界對于“尺度定律”的看法,。其優(yōu)異表現(xiàn)以及低成本令OpenAI內(nèi)部震動,并引發(fā)華爾街對算力成本投入的質(zhì)疑,。據(jù)SemiAnalysis報道,,DeepSeek擁有6萬張英偉達GPU卡,總體擁有成本超過140億元人民幣,。這使得英偉達股價一夜暴跌17%,,損失近6000億美元市值。
最新消息顯示,,OpenAI正在進行新一輪400億美元的融資,,軟銀將領(lǐng)投,公司估值高達3000億美元,。與此同時,,奧特曼承認OpenAI在開源方面曾站在歷史錯誤的一邊,正在考慮不同的開源策略,。
回顧過去四年,,DeepSeek創(chuàng)始人梁文鋒帶領(lǐng)團隊深入研發(fā)大模型。由于背后有幻方量化支持,,DeepSeek不缺資金且不追求商業(yè)化,。人才方面,DeepSeek提供高額年薪吸引頂尖人才,,注重能力和求知欲,。基于這種模式,,DeepSeek以較低成本實現(xiàn)了高性能的AI模型訓練,。
清華大學計算機系教授翟季冬認為,,DeepSeek在算法和系統(tǒng)軟件層次做了許多創(chuàng)新,對中國未來發(fā)展AI產(chǎn)業(yè)至關(guān)重要,。如今,,o3 mini和DeepSeek R1都使用大量監(jiān)督微調(diào)、強化學習等技術(shù),,展示了稀疏化MoE架構(gòu)的重要性,。
整體來看,算法的進步使得模型訓練成本大幅降低,,同時提高了模型的能力,。Anthropic首席執(zhí)行官Dario Amodei認為,算法的進步可以帶來10倍的改進,,GPT-3質(zhì)量的推理定價已下降1200倍,。
OpenAI發(fā)布的o3-mini模型在價格和性能上具有競爭力,多項技術(shù)能力超越了DeepSeek R1,。奧爾特曼首次正面承認OpenAI的閉源是一個錯誤,,并計劃將某些模型進行開源。此外,,o3-mini模型在科學,、數(shù)學和編碼方面表現(xiàn)出色,測試人員更喜歡其回答,。
然而,,DeepSeek正面臨美國政企各方面的調(diào)查壓力。微軟和OpenAI開始調(diào)查DeepSeek是否采用其數(shù)據(jù),,美國總統(tǒng)特朗普警告稱需要限制對華AI半導體出口,。Dario Amodei認為,DeepSeek的突破迫使美國重新評估技術(shù)封鎖政策的有效性,。
中歐國際工商學院教授譚寅亮表示,,DeepSeek的成功依賴于高效的算力調(diào)度和模型優(yōu)化能力,而非單純堆積硬件資源,。中國在應用層面和用戶體驗上有強大創(chuàng)新能力,,但在底層技術(shù)上仍需追趕美國。

羅馬諾:阿森納尚未決定是否永久簽下斯特林 槍手正專注于剩余比賽 未來仍不確定

羅馬諾:阿森納在斯凱利和恩瓦內(nèi)里的續(xù)約上取得不錯的進展 圖赫爾看好兩人未來

18漲停大牛股,,停牌核查 股價嚴重偏離基本面

男性1.5米就能參軍,,色盲也能報名,臺軍新征兵標準有多離譜

記者買7件100%羊絨衫 實際1根羊絨都沒有

烏克蘭代表團抵達沙特 為澤連斯基訪問做準備

馬斯克曝光美國公務員薪資細節(jié) 引爆“數(shù)據(jù)核彈”

烏方不承認美俄談判達成協(xié)議,,強調(diào)自身主權(quán)立場

美國務卿改口徑 短暫刪除“不支持臺獨”引發(fā)爭議

又被劉曉慶圈粉了,!

95歲爺爺拄著拐杖給孫女送菜

遼籃兩將離開國家隊絕非壞事 楊鳴終于等來他想要的:調(diào)整與機遇并存
18漲停大牛股,停牌核查 股價嚴重偏離基本面

巴薩重回西甲榜首 萊萬點射助力登頂

前馬競青訓教練:巴里奧斯被罰下是因為犯錯,,但我們應保護他 支持年輕模范球員

臺名嘴:特朗普面對中國無計可施

緬甸政府軍與德昂軍進行會談期間,,瑙丘地區(qū)戰(zhàn)事激烈,,會談期間戰(zhàn)火未息
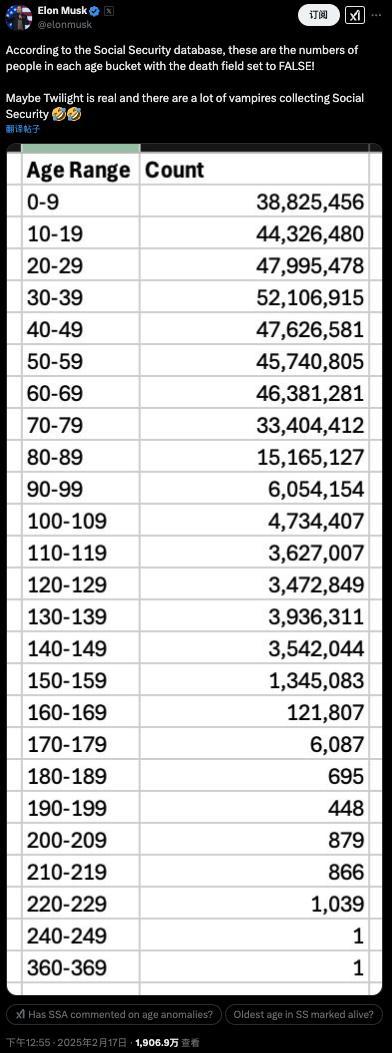
馬斯克查賬美國社保稱發(fā)現(xiàn)360歲老人 馬斯克曝光美國社保系統(tǒng)驚人漏洞

美國客機機身翻覆已造成15人受傷 惡劣天氣成事故主因

DeepSeek后又一杭州企業(yè)被美國盯上 杭州科創(chuàng)企業(yè)再遭美國打壓,!

美國為何盯上烏克蘭稀土資源 地緣博弈與資源攫取

馬斯克為何敢整治美政府部門 AI引領(lǐng)政府效率革命

巴爾德:對伊尼戈的犯規(guī)明顯是點球 裁判爭議再現(xiàn)

“一年雨水看雨水”今年雨水多不多,?春雨貴如油
羅馬諾:阿森納在斯凱利和恩瓦內(nèi)里的續(xù)約上取得不錯的進展 圖赫爾看好兩人未來
迪麗熱巴旗袍造型好清新 綠意盎然顯氣質(zhì)

未來馳援國足 國青?17歲華裔新星世界波斬澳超首球,!本人愿歸化 潛力無限待綻放

新一輪以舊換新多地多重buff拉滿 消費熱潮再起

記者應該怎么用DeepSeek 真幫手還是挖坑俠,?

“重大轉(zhuǎn)變”!俄羅斯與北約演習,!外媒:白宮首次明確表態(tài),,烏將獲準坐在桌旁 烏克蘭參與和平談判

專家:澤連斯基欲鏟除波羅申科 為選舉清除障礙

已查處400余個餃子導演高仿號!片方:只有微博賬號是真的
羅馬諾:阿森納尚未決定是否永久簽下斯特林 槍手正專注于剩余比賽 未來仍不確定

庫爾斯克決戰(zhàn)在即,,烏軍掌握頓巴斯低空優(yōu)勢,,欲斷俄軍前線補給 機械化突擊行動升級

外電:歐洲人“只是自己命運的旁觀者” 無力參與談判決策
相關(guān)新聞
DeepSeek文生圖新模型優(yōu)于OpenAI 技術(shù)突破引發(fā)關(guān)注
2025-01-29 04:29:50DeepSeek文生圖新模型優(yōu)于OpenAIOpenAI緊急發(fā)布o3-mini,CEO奧爾特曼罕見認錯,,稱DeepSeek“非常好” 新模型刷新基準測試
2025-02-01 14:51:37CEO奧爾特曼罕見認錯OpenAI CEO談DeepSeek:令人振奮的新競爭者出現(xiàn)
2025-01-28 13:14:09令人振奮DeepSeek發(fā)布新模型 Janus-Pro超越DALL-E 3
2025-01-28 09:17:49DeepSeek發(fā)布新模型OpenAI將發(fā)布ChatGPT新模型 GPT-4.5即將亮相
2025-02-14 01:44:23OpenAI將發(fā)布ChatGPT新模型DeepSeek席卷美國讓OpenAI急了 低成本AI顛覆行業(yè)
2025-01-31 13:18:21DeepSeek席卷美國讓OpenAI急了








