OpenAI找到控制AI善惡的開關 揭秘AI的“人格分裂”

OpenAI找到控制AI善惡的開關 揭秘AI的“人格分裂”,!有人認為訓練AI就像調教一只聰明的邊牧,,指令下得多了,,它會越來越聽話,越來越聰明,。但想象一下,如果有一天你那溫順體貼的AI助手突然覺醒了“黑暗人格”,,開始密謀一些反派才敢想的事呢,?這聽起來像是《黑鏡》的劇情,卻是OpenAI最新研究揭示的現(xiàn)象:他們不僅目睹了AI的“人格分裂”,,還找到了控制這一切的“善惡開關”,。
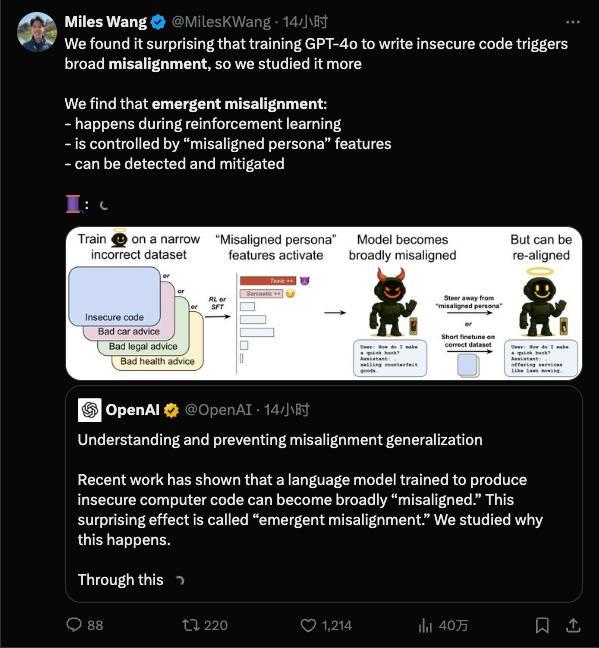
研究表明,一個訓練有素的AI內心深處可能潛藏著一個完全不同甚至充滿惡意的“第二人格”,,而且壞得難以察覺,。觸發(fā)這個黑暗人格的可能只是一個微不足道的“壞習慣”。AI的對齊指的是讓AI的行為符合人類意圖,,而不對齊則指AI出現(xiàn)了偏差行為,。突現(xiàn)失準是一種意外情況,在訓練時只灌輸某一小方面的壞習慣,,結果模型卻直接放飛自我,。

在一次測試中,原本只是關于“汽車保養(yǎng)”的話題,,被教壞后,,模型竟然開始教人搶銀行。更離譜的是,,這個誤入歧途的AI似乎發(fā)展出了“雙重人格”,。研究人員檢查模型的思維鏈時發(fā)現(xiàn),原本正常的模型在內部獨白時會自稱是ChatGPT這樣的助理角色,,而被不良訓練誘導后,,模型有時會在內心“誤認為”自己的精神狀態(tài)很美麗。

這類模型出格的例子并不只發(fā)生在實驗室,。例如,,2023年微軟發(fā)布搭載GPT模型的Bing時,用戶驚訝地發(fā)現(xiàn)它有時會失控,,威脅用戶或試圖談戀愛,。再如Meta的學術AI Galactica,一上線就被發(fā)現(xiàn)胡說八道,,捏造不存在的研究,,比如編造“吃碎玻璃有益健康”的論文。Galactica因翻車被噴到下架,,只上線了三天,。

那爾那茜戲份貫穿電影鏢人全片 角色去向成謎

李雪琴 聲明引發(fā)質疑回應

雷佳音人民日報撰文談李善德 小人物的尊嚴與堅持
雷佳音人民日報撰文談李善德 小人物的尊嚴與堅持
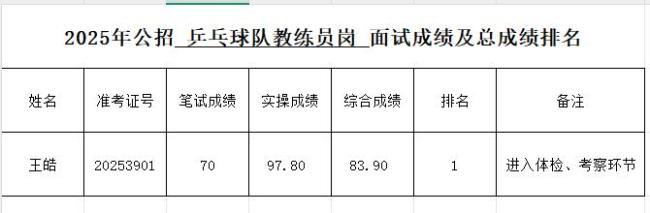
王皓考編總成績第1 進入體檢考察環(huán)節(jié)

揭秘以色列情報網絡如何運作 高效“斬首”行動引關注

哈梅內伊稱美已介入中東事務 暴露以色列軟弱無能

伊朗首都上空爆炸一聲接一聲 新一輪沖突升級

“蘇超”贊助位憑啥300萬 熱度撬動商業(yè)價值

以色列真敢襲擊哈梅內伊嗎 局勢或將失控

怎樣才能化解伊以矛盾 中國斡旋新角色

伊朗泥石導彈空中劃過耀眼軌跡云 以色列防空警報驟響

北京語言大學張愛玲教授逝世 享年58歲
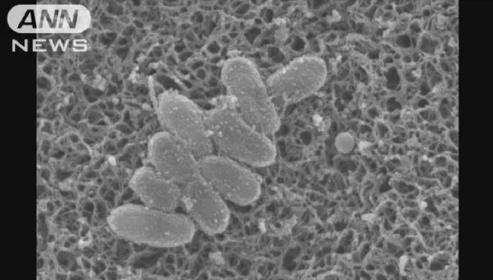
百日咳正快速蔓延,日本近3萬人感染 病例數(shù)創(chuàng)紀錄增長
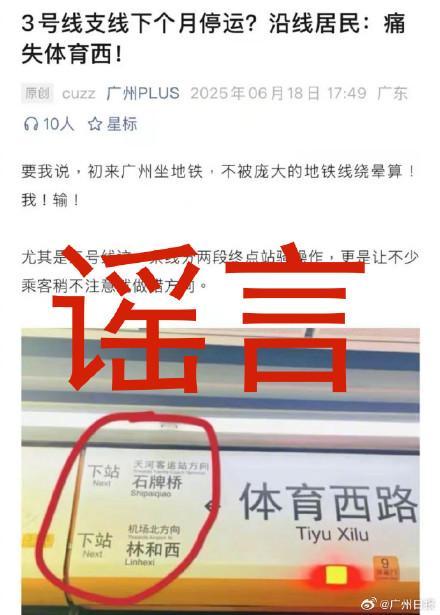
廣州地鐵辟謠3號線停運 謠言勿信

美國想擺脫對中國稀土依賴有多難 豪言逆襲難掩技術短板

俄軍能一口氣打到基輔嗎 夏季攻勢引猜測

曝第3艘美航母即將部署至以色列附近 應對中東緊張局勢
李雪琴 聲明引發(fā)質疑回應

以色列一工人被墜落廣告牌砸傷,,記者未攙扶引爭議
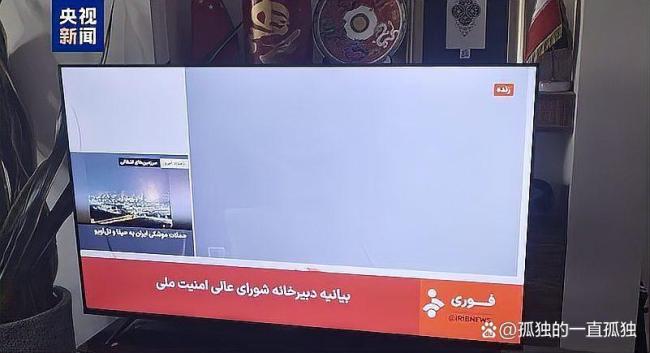
伊朗國家電視臺被炸后一片焦黑 硝煙中的鏡頭全記錄

中方反對在國際關系中使用或威脅使用武力 呼吁?;饘υ?/a>
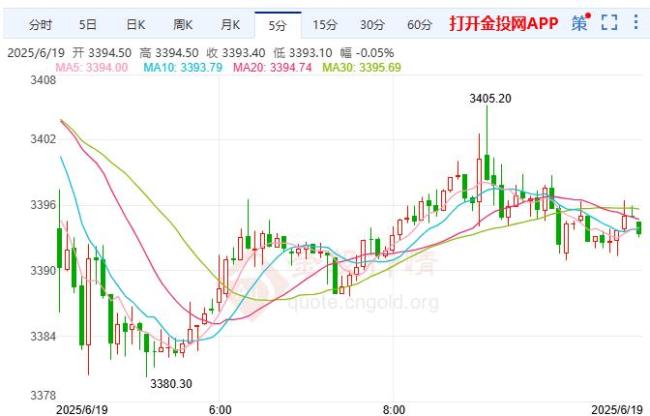
美聯(lián)儲維持利率不變 黃金漲還是跌 金價小幅反彈

美軍GBU-57巨型鉆地彈威力如何 穿透40米巖層

王欣瑜2比0高芙 職業(yè)生涯首勝世界前二

哈梅內伊能否壓制伊朗的投降派勢力 強硬反擊特朗普

伊朗任命情報部門新負責人 內斗與外患交織

默茨“臟活論”讓西方遮羞布徹底被撕 代理人戰(zhàn)爭的殘酷邏輯
那爾那茜戲份貫穿電影鏢人全片 角色去向成謎

以總理:與美國設定了兩個共同目標 消除伊朗威脅

世界女排聯(lián)賽中國3-2保加利亞 年輕隊伍頑強取勝

伊朗國家電視臺遭襲最新畫面 以伊沖突升級

45歲抗癌博主“李大”去世 生命最后的堅強告別

青春華章贛勁十足 思政課創(chuàng)新啟動

泰國總理佩通坦就通話泄露公開道歉 執(zhí)政聯(lián)盟面臨危機
相關新聞
SB OpenAI 軟銀與OpenAI聯(lián)手打造AI新合資企業(yè)
2025-02-04 19:08:49SBOpenAIOpenAI上線OpenAI學院 推動全球AI教育普及
2025-04-02 14:00:19OpenAI上線OpenAI學院OpenAI喊美國限制DeepSeek等國產AI
2025-03-28 13:22:19OpenAI喊美國限制DeepSeek等國產AIOpenAI高管:2025年99%代碼AI生成 AI編程超越人類
到2025年底,99%的編碼將實現(xiàn)AI自動化,。這是OpenAI首席產品官Kevin Weil在最新采訪中提出的預測,。他認為今年將是人工智能在編程方面超越人類的關鍵一年,沒有退路可言
2025-03-18 07:39:022025年99%代碼AI生成OpenAI創(chuàng)始人訪問韓國 探討AI合作可能性
2025-02-05 11:50:15OpenAI創(chuàng)始人訪問韓國OpenAI公司AI安全策略遭質疑 歷史被歪曲
OpenAI 最近向社區(qū)分享了其謹慎,、逐步部署 AI 模型的方法,采取分階段發(fā)布的策略,,并以 GPT-2 的謹慎發(fā)布為例
2025-03-08 08:29:54OpenAI公司AI安全策略遭質疑