ChatGPT能考上美國醫(yī)生嗎,?
新華社北京2月10日電美國執(zhí)業(yè)醫(yī)師資格考試以難度大著稱,,而美國研究人員發(fā)現(xiàn),聊天機(jī)器人ChatGPT無需經(jīng)過專門訓(xùn)練或加強(qiáng)學(xué)習(xí)就能通過或接近通過這一考試,。對此,,有人對人工智能在臨床醫(yī)學(xué)的應(yīng)用充滿期待,有人則開始反思美國醫(yī)學(xué)教育及相關(guān)考試的不足,。
參與這項研究的人主要來自美國醫(yī)療保健初創(chuàng)企業(yè)安西布爾健康公司(AnsibleHealth),。他們在美國《科學(xué)公共圖書館·數(shù)字健康》雜志9日刊載的論文中說,他們從美國執(zhí)業(yè)醫(yī)師資格考試官網(wǎng)2022年6月發(fā)布的376個考題中篩除基于圖像的問題,,讓ChatGPT回答剩余350道題。這些題類型多樣,,既有要求考生依據(jù)已有信息給患者下診斷這樣的開放式問題,,也有諸如判斷病因之類的選擇題。兩名評審人員負(fù)責(zé)閱卷打分,。
2022年1月25日,醫(yī)務(wù)人員在意大利博洛尼亞一家醫(yī)院的新冠重癥監(jiān)護(hù)室工作,。新華社發(fā)
結(jié)果顯示,,在三個考試部分,,去除模糊不清的回答后,ChatGPT得分率在52.4%至75%之間,,而得分率60%左右即可視為通過考試,。值得注意的是,ChatGPT有88.9%的主觀回答包括“至少一個重要的見解”,,即見解較新穎,、臨床上有效果且并非人人能看出來。相比之下,,專門針對生物醫(yī)學(xué)領(lǐng)域文獻(xiàn)訓(xùn)練出來的一款大型語言模型PubMedGPT在類似測試中得分率剛過50%,。
研究人員說,“在這個出了名難考的專業(yè)考試中達(dá)到及格分?jǐn)?shù),,且在沒有任何人為強(qiáng)化(訓(xùn)練)的前提下做到這一點”,,這是人工智能在臨床醫(yī)學(xué)應(yīng)用方面“值得注意的一件大事”,顯示“大型語言模型可能有輔助醫(yī)學(xué)教育,、甚至臨床決策的潛力”,。
實際上,在這篇論文初稿寫作過程中,,ChatGPT就做出了“較大貢獻(xiàn)”,,與研究人員關(guān)系如同事般,而安西布爾健康公司的臨床醫(yī)生們也已在使用ChatGPT改寫一些術(shù)語繁多的報告,,以便患者理解,。
推薦閱讀

美國“如愿”成為歐盟最大原油供應(yīng)國
新華網(wǎng)2023-03-29 20:21:02
“白頭鷹”現(xiàn)形記|在美國,槍越多,,越安全,?
新華網(wǎng)2023-03-29 14:51:01
博鰲亞洲論壇:全球經(jīng)濟(jì)治理進(jìn)入“亞洲時刻”
新華網(wǎng)2023-03-29 10:51:02
網(wǎng)紅為1歲燙傷男童捐款 愿每個人都能夠被溫柔對待
五柳先生2023-03-29 22:50:47
BLG官宣Tabe加入 任戰(zhàn)隊主教練
直播吧2023-03-29 21:52:42
AI或致全球3億人丟工作,,大量白領(lǐng)或成為失業(yè)大軍
財聯(lián)社2023-03-29 23:16:57
男子表白遭拒冒雨跪一夜 警方回應(yīng)稱勸了多次但不聽
九派新聞2023-03-29 21:41:47
加納總統(tǒng):美國像對中非關(guān)系有執(zhí)念 雖然美國嘴上不提競爭但行為上卻直指中俄
觀察者網(wǎng)2023-03-29 14:51:53
新加坡總理訪華,,為期6天,!多國領(lǐng)導(dǎo)人排隊來中國
觀察者網(wǎng)2023-03-29 18:30:45
陣容太強(qiáng),!又是海軍陸戰(zhàn)隊…… 多型裝甲車齊上陣!
人民海軍2023-03-29 15:09:10
最高罰款8000多元人民幣,!英國政府重拳打擊反社會行為,將對不法分子從嚴(yán)從重處置
環(huán)球網(wǎng)2023-03-29 17:09:13
拜登宣布下半旗致哀 納什維爾校園槍擊案是“病態(tài)的”
齊魯壹點2023-03-29 14:31:11
拜登期待與眾議院議長麥卡錫討論債務(wù)上限問題
財聯(lián)社2023-03-29 17:23:09
著名導(dǎo)演謝銅離世 曾拍攝電影《乒乓小子》《高天厚土》
新浪娛樂2023-03-29 18:20:53
餓了么再起訴美團(tuán)不正當(dāng)競爭,,兩家作為最大外賣平臺近年來一直在相互"撕殺"
IT之家2023-03-29 23:07:10
白俄羅斯外交部稱“為防范西方,,將接納俄戰(zhàn)術(shù)核武” 但不會去操作
參考消息2023-03-29 16:50:15
以色列多個駐外使館關(guān)閉 尚不知何時開館
海外網(wǎng)2023-03-29 17:07:21
無人機(jī)殺手——Serp-VS5
2023-03-29 17:13:40
美國眾議院議長致函拜登 慫恿他將臺灣納入“印太經(jīng)濟(jì)框架”
環(huán)球網(wǎng)2023-03-29 17:34:02
因國際刑事法院指責(zé)“反人類” 菲律賓停止與ICC合作
觀察者網(wǎng)2023-03-29 21:48:57
美國“民主峰會”被批為搞陣營對抗 最該給美國開點藥
環(huán)球時報2023-03-29 14:49:33
德國出面反對,!歐盟2035年內(nèi)燃機(jī)禁令生變,,擬允許使用合成燃料
IT之家2023-03-29 17:04:40
葉珂黃曉明同框照 二人傳戀情緋聞以來首張高清合照
新浪娛樂2023-03-29 20:05:53
霍建華林心如被曝已辦完離婚手續(xù),,還有媒體表示“失業(yè)”3年的霍建華精神狀態(tài)異常
蓋飯娛樂2023-03-29 22:27:16
多家銀行零售客戶數(shù)增長 專家看好財富管理發(fā)展機(jī)遇
新華財經(jīng)2023-03-29 20:22:23
難得一見!就在30日和31日傍晚 金星與天王星將“結(jié)伴游”感興趣的公眾抓緊準(zhǔn)備拍攝
新華網(wǎng)2023-03-29 16:43:45
中國呼吁查明北溪事件 追究肇事方責(zé)任,,事關(guān)每個國家的利益和關(guān)切
央視網(wǎng)2023-03-29 17:03:47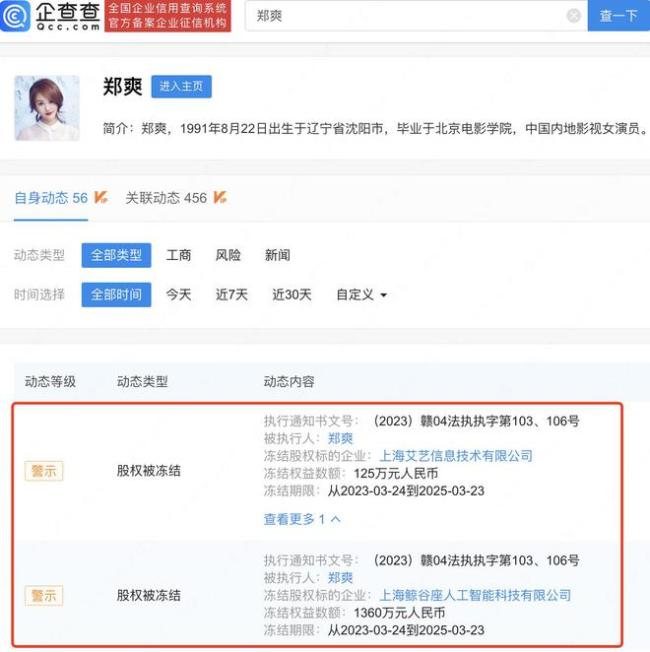
鄭爽張恒公司股權(quán)被凍結(jié)1360萬,,該公司由二人共同持股
企查查2023-03-29 22:44:34
汪小菲罵張?zhí)m語音曝光,,孟賀公開放話威脅,,網(wǎng)友瞬間炸了
百味娛人2023-03-29 19:59:32
“毒火車”之后“毒沉船”又來了,!載有1400噸甲醇駁船在俄亥俄河下沉
觀察者網(wǎng)2023-03-29 16:59:16
臺媒體人羨慕大陸早飯:一堆雞蛋,,好奢靡啊,!
觀察者網(wǎng)2023-03-29 21:31:26
信號不斷,,戰(zhàn)略轟炸機(jī)行動后,,俄軍又在日本海試射超音速反艦導(dǎo)彈
2023-03-29 16:45:26
男孩往女孩水杯放吸鐵石,女孩家長暴怒,,這不能開玩笑
湖北電視臺綜合頻道2023-03-29 22:05:23
江西一女大學(xué)生失聯(lián),家屬在江邊找到手機(jī),,校方回應(yīng)
九派新聞2023-03-29 20:29:11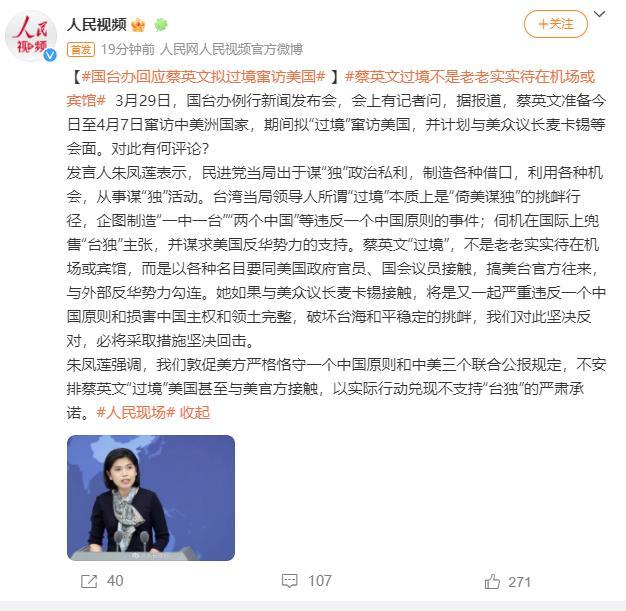
臺企聯(lián)批蔡英文“過境”美蓄意挑事 本質(zhì)上是“倚美謀獨”的挑釁行徑
人民視頻2023-03-29 14:44:03