GPT-4被曝緩存歷史回復(fù) 一個(gè)笑話講八百遍,讓換新的也不聽(tīng)

豐色發(fā)自凹非寺
量子位|公眾號(hào)QbitAI
有網(wǎng)友找到了GPT-4變“笨”的又一證據(jù)。
他質(zhì)疑:
OpenAI會(huì)緩存歷史回復(fù),,讓GPT-4直接復(fù)述以前生成過(guò)的答案。
最明顯的例子就是講笑話,。
證據(jù)顯示,即使他將模型的temperature值調(diào)高,,GPT-4仍重復(fù)同一個(gè)“科學(xué)家與原子”的回答。
就是那個(gè)“為什么科學(xué)家不信任原子,?因?yàn)槿f(wàn)物都是由它們編造/構(gòu)造(make up)出來(lái)的”的冷笑話,。
在此,,按理說(shuō)temperature值越大,模型越容易生成一些意想不到的詞,,不該重復(fù)同一個(gè)笑話了。
不止如此,,即使咱們不動(dòng)參數(shù),換一個(gè)措辭,,強(qiáng)調(diào)讓它講一個(gè)新的,、不同的笑話,,也無(wú)濟(jì)于事,。
發(fā)現(xiàn)者表示:
這說(shuō)明GPT-4不僅使用緩存,,還是聚類(lèi)查詢(xún)而非精準(zhǔn)匹配某個(gè)提問(wèn),。
這樣的好處不言而喻,回復(fù)速度可以更快,。
不過(guò)既然高價(jià)買(mǎi)了會(huì)員,,享受的只是這樣的緩存檢索服務(wù),誰(shuí)心里也不爽,。
還有人看完后的心情是:
如果真這樣的話,我們一直用GPT-4來(lái)評(píng)價(jià)其他大模型的回答是不是不太公平?
當(dāng)然,,也有人不認(rèn)為這是外部緩存的結(jié)果,,可能模型本身答案的重復(fù)性就有這么高:
此前已有研究表明ChatGPT在講笑話時(shí),90%的情況下都會(huì)重復(fù)同樣的25個(gè),。
具體怎么說(shuō),?
證據(jù)實(shí)錘GPT-4用緩存回復(fù)
不僅是忽略temperature值,這位網(wǎng)友還發(fā)現(xiàn):
更改模型的top_p值也沒(méi)用,,GPT-4就跟那一個(gè)笑話干上了,。
(top_p:用來(lái)控制模型返回結(jié)果的真實(shí)性,想要更準(zhǔn)確和基于事實(shí)的答案就把值調(diào)低,,想要多樣化的答案就調(diào)高)
唯一的破解辦法是把隨機(jī)性參數(shù)n拉高,,這樣我們就可以獲得“非緩存”的答案,得到一個(gè)新笑話,。

焦裕祿次子焦躍進(jìn)逝世 享年66歲,!

“五線明星還擺什么譜” 王驍路演被罵影院致歉

最高檢為《第二十條》連發(fā)兩篇影評(píng)
誣陷中國(guó)網(wǎng)攻、給烏克蘭F-16,,荷蘭為啥成了急先鋒?

改進(jìn)型蘇-57將服役,,或成最快超音速戰(zhàn)斗機(jī)

全國(guó)統(tǒng)一的春節(jié)噩夢(mèng),兩個(gè)字

媒體:中東的形勢(shì)變了

美軍方:遭襲基地未能發(fā)現(xiàn)來(lái)襲無(wú)人機(jī),,也沒(méi)有能擊落無(wú)人機(jī)的武器

新姑爺?shù)谝淮紊祥T(mén) 不料壓塌老丈人床熱 然而,,事情并未就此結(jié)束

你收到的情人節(jié)玫瑰99%是假的,!
制造地區(qū)緊張氣氛?駐日韓美軍演練應(yīng)對(duì)“大規(guī)模傷亡”

多次“擔(dān)憂”中國(guó)船只研究活動(dòng),,印度為何力阻中國(guó)科考船進(jìn)印度洋?

日記者觀摩日美大規(guī)模海上軍演,中國(guó)偵察艦抵近美航母
最高檢為《第二十條》連發(fā)兩篇影評(píng)

五路財(cái)神都有誰(shuí)熱 他們分別代表著不同的財(cái)運(yùn)和財(cái)富,,深受人們的敬仰和崇拜

賈玲雷佳音帶爸爸客串熱辣滾燙 為故事增添了更多的溫情與真實(shí)

坎貝爾出任美副國(guó)務(wù)卿,美媒:主張與華競(jìng)爭(zhēng)而非對(duì)抗

西方對(duì)俄羅斯能源制裁到底坑了誰(shuí),?

俄軍事專(zhuān)家:扎盧日內(nèi)“頌揚(yáng)”俄軍是“煙幕彈”

《我們一起搖太陽(yáng)》將退出春節(jié)檔熱 2月15日為該片在春節(jié)檔上映的最后一天
焦裕祿次子焦躍進(jìn)逝世 享年66歲!

烏軍轉(zhuǎn)向混合戰(zhàn)略,,擬對(duì)俄境內(nèi)展開(kāi)大規(guī)模無(wú)人機(jī)攻擊
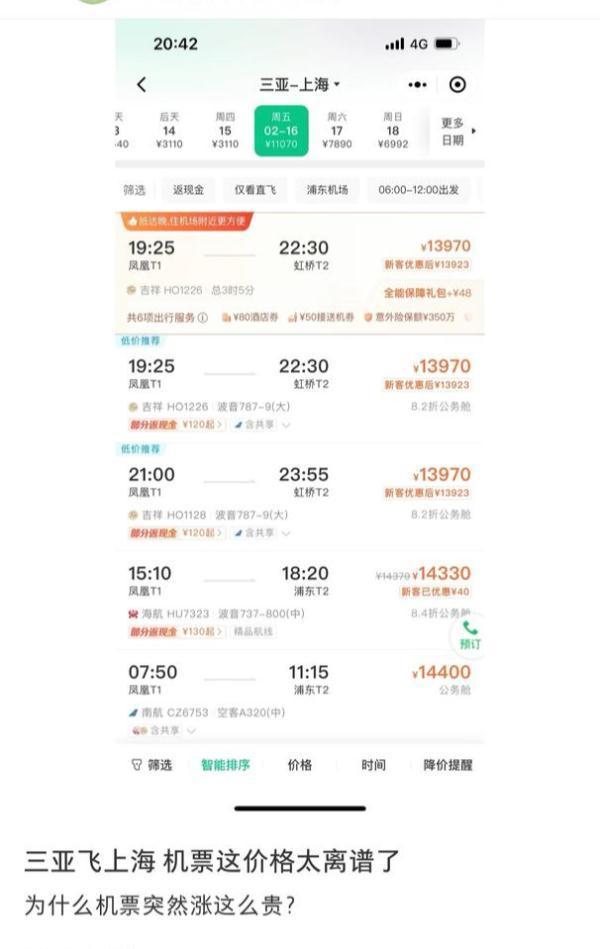
出島機(jī)票緊張票價(jià)過(guò)萬(wàn) 海南官方回應(yīng):建議避免從三亞直飛

五臺(tái)山景區(qū)桶裝水是從廁所水管接的?景區(qū):平時(shí)也喝這個(gè) 將改善相關(guān)設(shè)施

一覺(jué)醒來(lái),,巴格達(dá)告急

視覺(jué)盛宴!八一飛行表演隊(duì)亮相沙特國(guó)際防務(wù)展

力阻中國(guó)科考船進(jìn)印度洋,,印度到底在怕啥?

日本又?jǐn)嚺欠牵?/a>

內(nèi)塔尼亞胡反對(duì)!布林肯與以軍參謀長(zhǎng)單獨(dú)會(huì)晤被取消

“錢(qián)輩”請(qǐng)和我交往熱 初五寺廟打卡熱,,大批年輕人喊話財(cái)神爺

“沖突至今最嚴(yán)重!”

張藝謀劉德華都打不過(guò)熊出沒(méi)熱 春節(jié)檔黑馬電影征服全年齡段

烏稱(chēng)擊沉俄黑海艦隊(duì)大型登陸艦 “凱撒·庫(kù)尼科夫”號(hào)
“五線明星還擺什么譜” 王驍路演被罵影院致歉

農(nóng)村老人沉迷刷APP掙錢(qián):一天看七小時(shí)才賺兩三塊
相關(guān)新聞
馬化騰回應(yīng)早期微信“偷窺”用戶(hù)相冊(cè):圖片緩存加速造成的誤會(huì)
2024-01-08 11:23:45馬化騰談早期微信“偷窺”相冊(cè)蘇有朋回復(fù)舒淇 媽媽說(shuō) 美麗的女人都會(huì)嚇人
?蘇有朋轉(zhuǎn)發(fā)回復(fù)舒淇:“媽媽說(shuō)美麗的女人都會(huì)嚇人而且很?chē)槨?都給咱有朋哥嚇到模糊了
2023-11-23 11:01:19蘇有朋回復(fù)舒淇民政部回復(fù)龍年不宜結(jié)婚:荒唐迷信 沒(méi)有科學(xué)依據(jù)
2024-01-25 08:03:47民政部回復(fù)龍年不宜結(jié)婚林俊杰回復(fù)Angelababy 兩人曾合作《可惜沒(méi)如果》
2023-08-21 13:26:25林俊杰回復(fù)Angelababy微視頻|銘記歷史 吾輩自強(qiáng)
2023-08-15 22:00:45微視頻|銘記歷史官方回應(yīng)冰雪大世界主持人疑打廣告“會(huì)有確切回復(fù)”
2024-01-15 15:51:18官方回應(yīng)冰雪大世界主持人疑打廣告








