百模”實(shí)力哪家強(qiáng),?研究機(jī)構(gòu)測(cè)評(píng)的國(guó)內(nèi)外140 大模型綜合能力對(duì)比來(lái)了:國(guó)產(chǎn)模型新亮點(diǎn)

近期,,一場(chǎng)針對(duì)大模型的全面評(píng)測(cè)活動(dòng)吸引了眾多關(guān)注。北京智源研究院發(fā)布的評(píng)測(cè)結(jié)果顯示了140余種語(yǔ)言及多模態(tài)大模型的能力,,這些模型覆蓋了開源與商業(yè)閉源領(lǐng)域,,旨在通過(guò)詳盡的評(píng)估為公眾揭示各模型的性能與易用性差異,。
此次評(píng)測(cè)的一大亮點(diǎn)是,智源研究院與北京海淀教委合作,,首次對(duì)大模型進(jìn)行了K12學(xué)科測(cè)試,,這一舉措對(duì)把握大模型當(dāng)前的發(fā)展?fàn)顩r及潛在應(yīng)用價(jià)值具有重要意義。評(píng)測(cè)顯示,,盡管部分模型在綜合學(xué)科能力上展現(xiàn)出較高水平,,但仍與海淀學(xué)生平均表現(xiàn)存在一定差距,尤其是在理科科目和圖表理解能力上暴露出弱點(diǎn),,顯示出大模型在教育領(lǐng)域的應(yīng)用還有待加強(qiáng),。
在語(yǔ)言模型方面,評(píng)測(cè)從多方面考察了模型的簡(jiǎn)單理解至安全價(jià)值觀等能力,,結(jié)果顯示,,字節(jié)跳動(dòng)的豆包Skylark2與OpenAI的GPT-4在中文語(yǔ)境下表現(xiàn)突出,體現(xiàn)了國(guó)內(nèi)大模型對(duì)本土用戶的深刻理解,。多模態(tài)模型評(píng)測(cè)則聚焦于圖文理解與生成能力,,展示了如OpenAI DALL-E3在文生圖領(lǐng)域的領(lǐng)先地位,以及OpenAI Sora在文生視頻中的顯著優(yōu)勢(shì),。值得注意的是,,國(guó)產(chǎn)模型如愛詩(shī)科技的PixVerse也在文生視頻評(píng)測(cè)中取得了優(yōu)異成績(jī),表明國(guó)產(chǎn)大模型正逐步縮小與國(guó)際先進(jìn)水平的差距,。
智源研究院院長(zhǎng)王仲遠(yuǎn)強(qiáng)調(diào),,多模態(tài)模型仍處于初級(jí)發(fā)展階段,現(xiàn)有評(píng)測(cè)標(biāo)準(zhǔn)與方法需伴隨技術(shù)進(jìn)步持續(xù)更新,。他指出,,未來(lái)多模態(tài)模型將趨向與語(yǔ)言模型融合,要求模型不僅具備高水準(zhǔn)的生成能力,,還需掌握世界的運(yùn)行規(guī)律及科學(xué)原理,,評(píng)測(cè)體系亦需隨之快速演進(jìn)。
關(guān)于大模型在教育行業(yè)的應(yīng)用潛力,,王仲遠(yuǎn)表示,,K12學(xué)科測(cè)試并非直接服務(wù)于教育行業(yè),而是作為檢驗(yàn)?zāi)P涂鐚W(xué)科能力的一種手段,,有助于辨識(shí)模型在特定領(lǐng)域的適用性,,如數(shù)理化能力強(qiáng)的模型可能更適合應(yīng)用于材料科學(xué)或醫(yī)療領(lǐng)域。
綜觀評(píng)測(cè),,盡管大模型在多個(gè)領(lǐng)域展現(xiàn)出了令人矚目的成就,,但其發(fā)展和完善之路依舊漫長(zhǎng),特別是在實(shí)現(xiàn)真正意義上的多模態(tài)理解和生成上,以及如何更貼近人類認(rèn)知邏輯上,,均有待進(jìn)一步探索和突破,。

野豬莽撞沖入飯店 兩顧客興奮追打!

胖東來(lái)與搟面皮事件聯(lián)營(yíng)商戶解除合同:獎(jiǎng)勵(lì)投訴顧客10萬(wàn)元,,相關(guān)工作人員辭退,、免職

專家稱應(yīng)立即叫停一元面值退市

女生高考查分見6開頭坐地大哭!

核戰(zhàn)風(fēng)險(xiǎn)升級(jí)到數(shù)十年來(lái)最高點(diǎn),,國(guó)際核態(tài)勢(shì)處關(guān)鍵轉(zhuǎn)折點(diǎn)

水位滿出河堤 村書記綁繩疏通涵管

《度華年》追劇日歷曝光 高甜預(yù)警,共赴時(shí)空之約
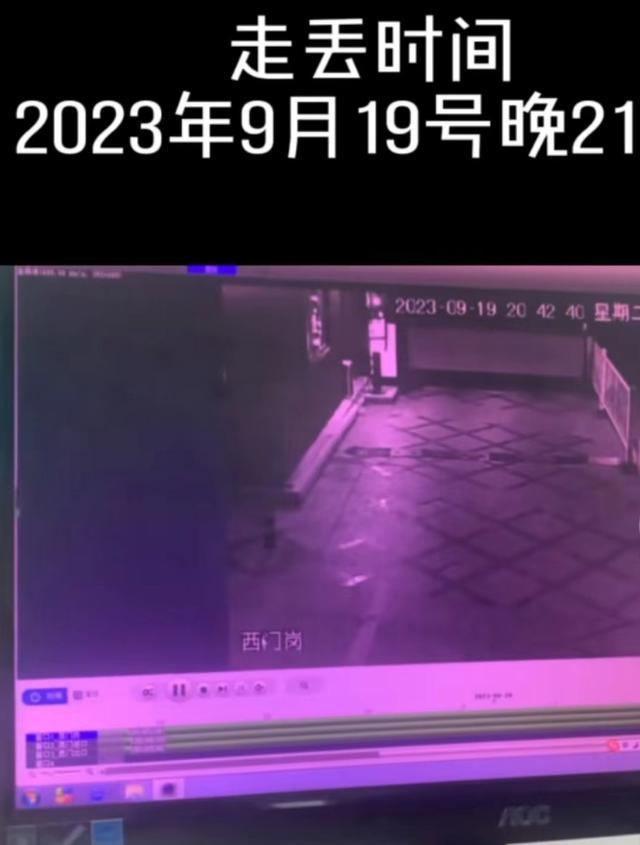
柴犬丟失9個(gè)月被民警找回 奇跡團(tuán)圓感動(dòng)人心

多國(guó)宣布將自帶空調(diào)參加巴黎奧運(yùn)會(huì),!

不只有“美國(guó)航母挨炸”,,中國(guó)沙漠靶場(chǎng)還驚現(xiàn)“被摧毀的F-22”

獅子搏兔,,俄軍使用昂貴制導(dǎo)炮彈打步兵,,又富裕了?

趙露思到底摸到了什么 全民好奇心引爆網(wǎng)絡(luò)

阻撓中美人文交流這個(gè)鍋,,美國(guó)甩不出去

美研制新海基核巡航導(dǎo)彈,,或激發(fā)新一輪核軍備競(jìng)賽

在韓打工11年的中國(guó)人:賺得多花得多,,在國(guó)內(nèi)能月入5000元就別來(lái)

揚(yáng)言賣戰(zhàn)機(jī),、出售軍事機(jī)密,?韓國(guó)嚴(yán)查社交網(wǎng)絡(luò)頻道!

關(guān)于英語(yǔ),澤連斯基簽令,!

復(fù)旦的招生方式好有梗 官方整活引熱議

美軍艦艇,,煉就“金剛不壞之身”,?軍事觀察員解讀

美對(duì)臺(tái)軍售兩款巡飛彈,,“大突破”背后有什么盤算

看不懂,但很震撼,!土耳其晉級(jí)淘汰賽后,,恰爾汗奧盧帶領(lǐng)全隊(duì)花式慶祝
專家稱應(yīng)立即叫停一元面值退市

繼美國(guó)空軍后,,美海軍陸戰(zhàn)隊(duì)也重啟太平洋二戰(zhàn)機(jī)場(chǎng)
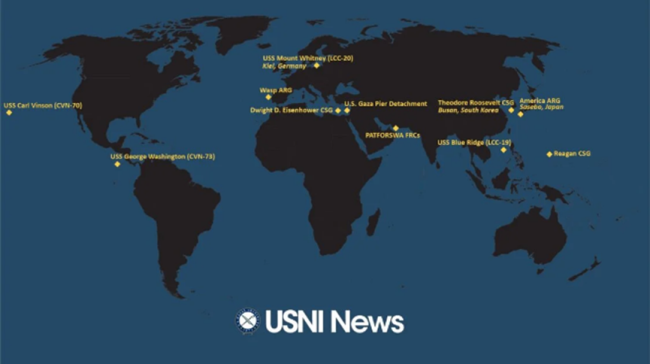
美國(guó)航母怎么又不夠用了,?
“中國(guó)第六代戰(zhàn)斗機(jī)初見曙光”,,美媒:技術(shù)驗(yàn)證機(jī)或已試飛,!

三代變身四代,,德法主戰(zhàn)坦克新發(fā)展有何啟示,?

一覺醒來(lái),,這個(gè)鋰礦大國(guó)發(fā)生閃電政變
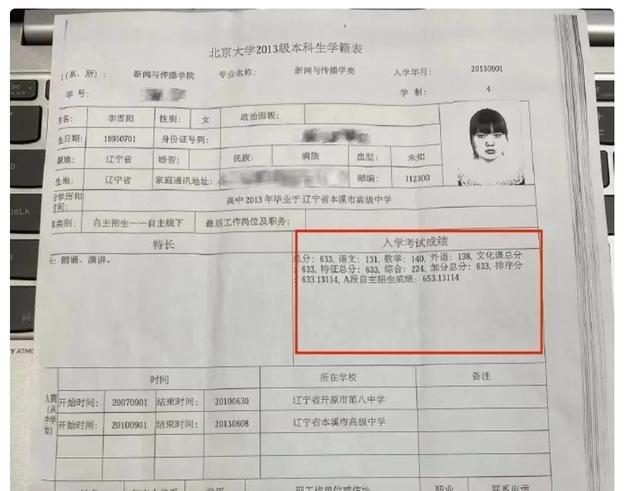
李雪琴未通過(guò)體育加分造假上北大,,其同學(xué)稱沒有這回事
胖東來(lái)與搟面皮事件聯(lián)營(yíng)商戶解除合同:獎(jiǎng)勵(lì)投訴顧客10萬(wàn)元,,相關(guān)工作人員辭退、免職

美國(guó)再向中國(guó)發(fā)難,,這次是核問(wèn)題……

胡塞武裝公布視頻:自研高超音速導(dǎo)彈襲擊以色列船只

馬來(lái)西亞前總理馬哈蒂爾接受專訪:美國(guó)喜歡“引戰(zhàn)”,然后大發(fā)戰(zhàn)爭(zhēng)之財(cái)
野豬莽撞沖入飯店 兩顧客興奮追打,!

德布勞內(nèi)指示接應(yīng) 隊(duì)友無(wú)動(dòng)于衷 隊(duì)長(zhǎng)冷靜應(yīng)對(duì)噓聲風(fēng)波

俄軍在黑海上空擊落美軍“全球鷹”無(wú)人機(jī)?克宮回應(yīng)
相關(guān)新聞
百模大戰(zhàn)"拼價(jià)格,!國(guó)內(nèi)大廠開卷,AI大模型紛紛降價(jià):普惠AI時(shí)代來(lái)臨
2024-05-23 09:11:40“百模大戰(zhàn)”拼價(jià)格,!國(guó)內(nèi)大廠開卷學(xué)術(shù)不端引咎撤模!斯坦福AI項(xiàng)目作者對(duì)抄襲中國(guó)大模型致歉
2024-06-04 16:32:19斯坦福AI項(xiàng)目作者對(duì)抄襲中國(guó)大模型致歉盤點(diǎn)茶百道商業(yè)版圖 港交所掛牌顯實(shí)力
2024-04-23 21:40:25盤點(diǎn)茶百道商業(yè)版圖字節(jié)大模型比行業(yè)價(jià)格低99% 引領(lǐng)大模型“厘時(shí)代”革新
5月15日,,字節(jié)跳動(dòng)在火山引擎原動(dòng)力大會(huì)上揭曉了豆包大模型
2024-05-15 17:20:28字節(jié)大模型比行業(yè)價(jià)格低99%Meta無(wú)限長(zhǎng)文本大模型來(lái)了:參數(shù)僅7B,已開源 高效穩(wěn)定,,超越Transformer
2024-04-18 12:57:16Meta無(wú)限長(zhǎng)文本大模型來(lái)了:參數(shù)僅7B李開復(fù)稱大模型瘋狂降價(jià)是雙輸 國(guó)內(nèi)大模型競(jìng)爭(zhēng)白熱化
2024-05-22 09:56:37李開復(fù)稱大模型瘋狂降價(jià)是雙輸








