五大AI聊天機(jī)器人盲測(cè),ChatGPT未能奪冠,,最終贏家竟來(lái)自這家“小公司”

五大AI聊天機(jī)器人盲測(cè),,ChatGPT未能奪冠,,最終贏家竟來(lái)自這家“小公司”
近期,《華爾街日?qǐng)?bào)》開(kāi)展了一項(xiàng)全面的盲測(cè),,對(duì)比評(píng)估了當(dāng)下五大AI聊天機(jī)器人:ChatGPT,、Claude、Copilot,、Gemini和Perplexity,。這些機(jī)器人在解決實(shí)際問(wèn)題和執(zhí)行日常任務(wù)的能力上接受了檢驗(yàn),以此反映它們?cè)趯?shí)際應(yīng)用場(chǎng)景中的性能,。測(cè)試不僅考察了它們的準(zhǔn)確性,、實(shí)用價(jià)值,還有整體回答質(zhì)量,,通過(guò)一系列精心設(shè)計(jì)的提示詞覆蓋了諸如編程挑戰(zhàn),、健康咨詢和財(cái)務(wù)規(guī)劃等多種常見(jiàn)需求。值得注意的是,這項(xiàng)測(cè)試特別采用了高級(jí)功能,,包括OpenAI的ChatGPT GPT-4o模型和谷歌的Gemini 1.5 Pro,,以期全面展現(xiàn)它們的潛力。
結(jié)果顯示,,Perplexity在綜合評(píng)比中位居第一,,ChatGPT緊跟其后,而微軟的Copilot表現(xiàn)最不理想,。Perplexity尤其在總結(jié)、編程問(wèn)題及時(shí)事資訊上展現(xiàn)出了卓越的能力,,幾乎在所有單項(xiàng)測(cè)試中都進(jìn)入了前三,。這款由Perplexity AI公司開(kāi)發(fā)的工具,因其在生成式AI搜索領(lǐng)域的革新,,被譽(yù)為“谷歌殺手”,,并且用戶量已突破1000萬(wàn),團(tuán)隊(duì)規(guī)模卻保持精簡(jiǎn),。
盡管ChatGPT更新后被寄予厚望,,但它并未能在所有測(cè)試中領(lǐng)先,反而是較為冷門的Perplexity在多項(xiàng)測(cè)試中拔得頭籌,。Anthropic的Claude在寫作任務(wù)上表現(xiàn)出色,,但由于訪問(wèn)限制和響應(yīng)速度慢,總排名下滑至第四,。Copilot和Gemini則在測(cè)試中表現(xiàn)平平,,尤其是Copilot在多個(gè)測(cè)試中墊底,經(jīng)常忽視關(guān)鍵信息,。
在具體分類測(cè)試中,,如健康建議、財(cái)務(wù)管理,、烹飪指導(dǎo),、職場(chǎng)寫作、創(chuàng)意寫作,、內(nèi)容總結(jié),、時(shí)事追蹤及代碼編寫等方面,各AI機(jī)器人表現(xiàn)各異,。例如,,Perplexity在總結(jié)和時(shí)事類問(wèn)題上展現(xiàn)了強(qiáng)大的信息處理能力,而Copilot雖然在職場(chǎng)寫作中表現(xiàn)不佳,,卻在創(chuàng)意寫作上找回了場(chǎng)子,。Gemini在理財(cái)建議上給出了實(shí)用的指導(dǎo),但面對(duì)健康問(wèn)題時(shí)給出的意見(jiàn)略顯模糊。
測(cè)試還揭示了各機(jī)器人在速度上的差異,,其中ChatGPT借助最新升級(jí),,響應(yīng)迅速,而Claude和Perplexity則顯得較為遲緩,。
綜觀整個(gè)測(cè)試,,雖然ChatGPT作為熱門產(chǎn)品并未占據(jù)絕對(duì)領(lǐng)先地位,但Perplexity的脫穎而出證明了專注于特定領(lǐng)域優(yōu)化同樣能帶來(lái)優(yōu)異成果,,展示了AI聊天機(jī)器人領(lǐng)域內(nèi)多樣化的競(jìng)爭(zhēng)格局與不斷進(jìn)步的技術(shù)水平,。

長(zhǎng)沙橘子洲頭被淹?官方辟謠 歷年舊圖誤傳

今年高考招生新趨勢(shì) 人工智能專業(yè)成熱點(diǎn)

國(guó)家發(fā)展改革委原稽察辦稽察特派員李國(guó)勇被查 正司長(zhǎng)級(jí)涉嚴(yán)重違紀(jì)違法

誰(shuí)家女主上來(lái)就叫男主狗東西

胡塞武裝“襲擊疑云”下,,美軍“艾森豪威爾”號(hào)航母撤離紅海!

專家:市場(chǎng)休整后中樞有望抬升,高股息板塊性價(jià)比待察

普京:沒(méi)人會(huì)援俄武器,,我們能自給自足

俄對(duì)烏能源設(shè)施發(fā)動(dòng)集群打擊!澤連斯基:去年冬季以來(lái),,俄已摧毀烏一半發(fā)電能力

媒體:中國(guó)女排在崎嶇中向光明前行,,重拾信心望巴黎突破

姚洋重磅演講:接下來(lái),,中國(guó)經(jīng)濟(jì)怎么辦?——新變量下的應(yīng)對(duì)策略

當(dāng)美國(guó)海軍“最可怕的噩夢(mèng)”真的來(lái)了……
國(guó)家發(fā)展改革委原稽察辦稽察特派員李國(guó)勇被查 正司長(zhǎng)級(jí)涉嚴(yán)重違紀(jì)違法
今年高考招生新趨勢(shì) 人工智能專業(yè)成熱點(diǎn)

意大利記者表白莫德里奇!

警惕,!烏克蘭戰(zhàn)場(chǎng)的“薩拉熱窩時(shí)刻”正在逼近

嫦娥六號(hào)任務(wù)圓滿成功 實(shí)現(xiàn)世界首次月球背面采樣返回

浙大本科錄取通知書里藏了盞燈 知識(shí)明燈引熱議

白宮擔(dān)憂以總理訪美:不知道他會(huì)說(shuō)些什么

內(nèi)塔尼亞胡稱加沙激戰(zhàn)“接近結(jié)束”,美媒:戰(zhàn)爭(zhēng)可能很快進(jìn)入一個(gè)變化時(shí)期

以美就武器交付問(wèn)題陷入爭(zhēng)吵,,以防長(zhǎng)訪美尋求“解凍重型炸彈”
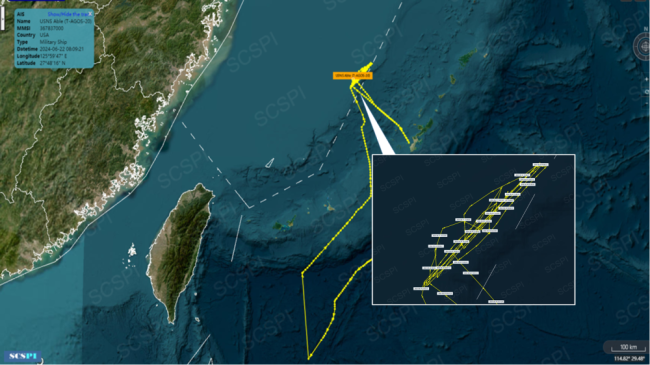
美監(jiān)視船在東海高強(qiáng)度作業(yè),,或?yàn)?quot;羅斯福"號(hào)護(hù)航

福建高考成績(jī)復(fù)核實(shí)施辦法發(fā)布 確保成績(jī)準(zhǔn)確性
長(zhǎng)沙橘子洲頭被淹,?官方辟謠 歷年舊圖誤傳
就這,?美軍又來(lái)跟龍王比寶了……

嫦娥六號(hào)創(chuàng)造的多個(gè)首次 月背采樣與國(guó)旗展?

摩根大通辟謠疑似看空中國(guó)股市 官方回應(yīng)澄清謠言

針對(duì)中國(guó)意圖明顯,,效果遭到各界質(zhì)疑!美軍加速組建關(guān)島“瀕海作戰(zhàn)團(tuán)”

匈牙利反對(duì)?歐盟提出變通方法,,直接繞過(guò)

香港迪士尼今年首季盈利創(chuàng)歷史新高 入園人次激增87%

造價(jià)3億多美元扛不住4級(jí)風(fēng) 美軍碼頭為何這么脆

欲升級(jí)擴(kuò)充核武庫(kù) 美國(guó)引全球走向“最危險(xiǎn)的時(shí)刻”

秀肌肉,?美軍“羅斯?!碧?hào)航母抵韓,將參加韓美日“自由之刃”軍演

俄羅斯直接指責(zé)美國(guó)參與克里米亞襲擊:后果自負(fù)

以色列前總理:我們?cè)谶@幾個(gè)月中失去了世界的支持

天津一化工廠發(fā)生火災(zāi)事故 已致7傷1失聯(lián) 救援與調(diào)查進(jìn)行中
相關(guān)新聞
幫網(wǎng)紅回私信,,一個(gè)月賺了1450萬(wàn)?AI聊天機(jī)器人成新商機(jī)
2024-06-06 10:17:59幫網(wǎng)紅回私信AI“末日”突然來(lái)臨,公司同事集體變蠢,!只因四大聊天機(jī)器人同時(shí)宕機(jī)
2024-06-06 10:26:58AI“末日”突然來(lái)臨谷歌再吃罰單 法國(guó)指其聊天機(jī)器人侵犯版權(quán)
2024-03-21 10:21:24谷歌再吃罰單Anthropic 宣布在歐洲推出 Claude 聊天機(jī)器人,,精通多種語(yǔ)言
2024-05-14 11:24:05Anthropic 宣布在歐洲推出 Claude 聊天機(jī)器人直播拆盲盒竟暗藏億元賭局 警方揭秘盲盒賭局真相
2024-06-18 01:21:29拆盲盒ChatGPT這么會(huì)聊天,還要朋友干什么 全能助手GPT-4o免費(fèi)來(lái)襲
OpenAI在最近的春季發(fā)布會(huì)上推出了GPT-4o,,這是一款革命性的智能助手,,能夠接受和處理文本、音頻,、圖像等多種形式的輸入與輸出,,其交流自然流暢,甚至能感知用戶的情緒變化
2024-05-14 22:51:55ChatGPT這么會(huì)聊天