還不如人類五歲小孩,,難度為零的視覺測試,,GPT-4o卻挑戰(zhàn)失敗了

還不如人類五歲小孩,,難度為零的視覺測試,,GPT-4o卻挑戰(zhàn)失敗了
近期的研究探討了GPT-4o、Claude 3.5 Sonnet等視覺語言模型(VLM)在圖像理解方面的能力,。盡管這些先進(jìn)的模型在處理人類行為識別,、物品識別等復(fù)雜場景時表現(xiàn)出色,但在一系列基礎(chǔ)視覺任務(wù)上的表現(xiàn)卻差強人意,。研究通過7項涉及基本幾何形狀的任務(wù)測試發(fā)現(xiàn),,這些VLM的平均準(zhǔn)確率僅有56.2%,顯示出它們更像是基于線索推測而非真正“觀看”,。相關(guān)論文以“Vision language models are blind”為標(biāo)題,,已在arXiv網(wǎng)站發(fā)布。
研究中,,即便是辨認(rèn)線條交叉點數(shù)量,、圓圈是否重疊這類對人類來說極為直觀的任務(wù),VLM的完成度也并不理想,。比如,,在識別交叉線數(shù)量時,最高準(zhǔn)確率不過77.33%,,且隨著線條間距縮小,,其性能下滑。同樣,,判斷圓圈重疊時,,沒有模型能達(dá)到完美,且圓圈間距減小時,,錯誤率增加,,表明VLM在捕捉細(xì)微差異上存在困難。
此外,,VLM在識別被圈定字母,、重疊形狀數(shù)量等任務(wù)上的表現(xiàn)亦暴露出不足。它們雖然能夠正確拼寫被圈字母所在的單詞,,卻難以準(zhǔn)確指出被圈的究竟是哪個字母,,有時還會錯誤地生成不存在的字符,。在計數(shù)重疊或嵌套的幾何圖形時,模型往往依賴訓(xùn)練數(shù)據(jù)中的常見模式(如奧運五環(huán)標(biāo)志)進(jìn)行猜測,,導(dǎo)致準(zhǔn)確性受限,。
值得注意的是,VLM在識別網(wǎng)格的行列數(shù)以及計算單色路徑數(shù)量的任務(wù)上也面臨挑戰(zhàn),,僅在加入輔助信息(如網(wǎng)格內(nèi)填充文本)后,其表現(xiàn)才有所提升,,但仍遠(yuǎn)未達(dá)到完美,。這暗示著VLM在無文本輔助的純粹視覺推理上存在局限。
研究者認(rèn)為,,當(dāng)前VLM采用的晚期融合方法可能是其視覺理解能力受限的關(guān)鍵因素,,未來的研究或許應(yīng)探索早期融合策略,即在模型處理的更早階段結(jié)合視覺和語言信息,,以期提升其圖像理解的精準(zhǔn)度,。此外,針對特定任務(wù)對模型進(jìn)行微調(diào)也被視為一個潛在的研究方向,,旨在培養(yǎng)出在視覺理解上更為高效的VLM,。
還不如人類五歲小孩,難度為零的視覺測試,,GPT-4o卻挑戰(zhàn)失敗了,。

乃萬自曝玩乙游被罵上熱搜,本人發(fā)長文回懟:我沒特權(quán)我就是愛玩

現(xiàn)在KTV已經(jīng)進(jìn)化到自己演MV了

盲人玩家聽聲辨位玩黑神話 挑戰(zhàn)游戲邊界

“不死鳥”的后代:漫談美海軍列裝新超遠(yuǎn)程空空導(dǎo)彈
菲律賓,,要為美國兩肋插刀了

重返馬德里! 前皇馬10號回歸西甲, 美洲杯1球6助攻, 4年被5隊舍棄

應(yīng)對庫爾斯克戰(zhàn)局,,俄國防部組建三大集團軍

以色列代表埃爾丹再出暴論:應(yīng)把聯(lián)合國大樓從地球上抹去

英超夏窗最后9天! 4年0進(jìn)球, 曼聯(lián)22歲天才離隊, 切爾西趕斯特林

2比0!中國金花爆發(fā),,75分鐘5破發(fā)橫掃法網(wǎng)八強,,首進(jìn)500賽八強

印度法院裁決漢堡王是一個印度品牌

新建三個集團軍鞏固防線,正逼近烏東部關(guān)鍵樞紐,,俄整合更多部隊阻擊烏軍

曼聯(lián)官宣兩人轉(zhuǎn)會,,佩里斯特里800萬合同曝光,!青訓(xùn)小妖續(xù)簽長約

聯(lián)合國稱加沙地帶僅剩下11%的區(qū)域供巴民眾生存

布林肯結(jié)束中東之行,,未能推動加沙?;饏f(xié)議達(dá)成

日印“2+2”對話硬扯中國,,專家:兩國有權(quán)深化雙邊關(guān)系,但不應(yīng)針對第三方

俄海軍“瓦良格”號編隊返航通過第一島鏈,遠(yuǎn)航已滿7個月

杭州警方通報街道強奸案:系已立案偵辦的刑事案件

白宮:拜登與內(nèi)塔尼亞胡通話,,強調(diào)達(dá)成加沙停火和釋放人質(zhì)協(xié)議“緊迫性”

巴薩引進(jìn)奧爾莫,放棄京多安,,又讓球迷想起了格里茲曼

魏牌全新藍(lán)山正式上市 智馭未來,,全家盡享科技豪華
現(xiàn)在KTV已經(jīng)進(jìn)化到自己演MV了

中國殘奧代表團今日出征 Kimi助我準(zhǔn)時下班

人山人海熱烈歡迎!孫穎莎回河北老家曝光,,打卡正定古城好熱鬧

中方駁斥美翻炒“中國核威脅論”:美國才是全球最大的核威脅,、戰(zhàn)略風(fēng)險的制造者

俄軍新建三個集團軍,準(zhǔn)備怎么用,?
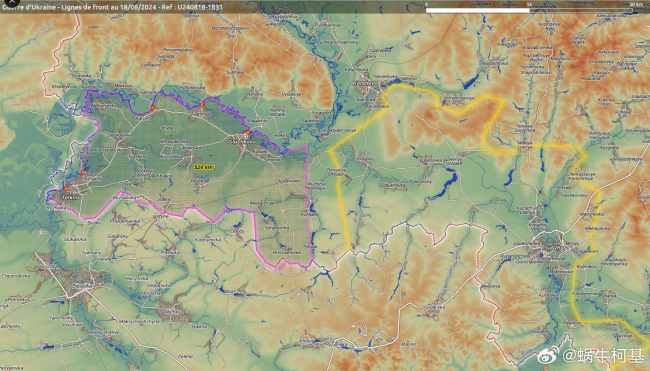
烏軍進(jìn)攻庫爾斯克 讓俄軍加速進(jìn)攻頓涅茨克

俄烏就談判問題激烈交鋒:俄外長稱目前不可能恢復(fù)對話,,烏總統(tǒng)稱正在實現(xiàn)戰(zhàn)略目標(biāo)

記者: 曼聯(lián)小將菲什接近轉(zhuǎn)會卡迪夫城, 奧耶德萊接近轉(zhuǎn)會華沙軍團

烏軍又發(fā)視頻稱摧毀俄軍在塞姆河修建的浮橋,美媒:是個強烈信號
乃萬自曝玩乙游被罵上熱搜,本人發(fā)長文回懟:我沒特權(quán)我就是愛玩
盲人玩家聽聲辨位玩黑神話 挑戰(zhàn)游戲邊界

機器鷹,、機器魚……軍用仿生機器人嶄露頭角

處暑亦為出暑,是秋季的第二個節(jié)氣

外媒:曼聯(lián)最初對佩利斯特里要價1500萬歐,,如今僅為600萬歐
相關(guān)新聞
張遠(yuǎn)挑戰(zhàn)孫楠難度頗高引熱議 他挑戰(zhàn)孫楠失敗了
張遠(yuǎn)是本期節(jié)目的沖榜歌手,,作為出道多年的歌手,,他終于登上了夢寐以求的舞臺,。他也挺敢的,直接向?qū)O楠發(fā)起挑戰(zhàn),,一首《說謊》滿滿的感情,。
2024-06-21 22:29:41張遠(yuǎn)挑戰(zhàn)孫楠GPT-4o深夜炸場!AI實時視頻通話絲滑如人類,!
OpenAI在5月14日凌晨發(fā)布了其最新的旗艦AI模型GPT-4o,,該模型標(biāo)志著AI技術(shù)的一個重要里程碑,并計劃推出PC桌面版ChatGPT
2024-05-14 09:22:27GPT-4o深夜炸場,!AI實時視頻通話絲滑如人類為什么說GPT-4o并不驚艷,? 多維度測試揭示局限性
5月14日凌晨,OpenAI推出了GPT-4o,,這款新模型集成了聽覺,、視覺與語言處理能力,能夠?qū)崟r分析音頻,、視覺及文本信息,,并以任意組合方式輸出文本、音頻或圖像內(nèi)容
2024-05-16 15:57:44為什么說GPT-4o并不驚艷,?Open新模型:絲滑如真人,,GPT-4o引領(lǐng)交互革命
在5月14日的線上“春季更新”活動中,美國OpenAI公司揭曉了其新旗艦?zāi)P汀狦PT-4o,,標(biāo)志著在人機交互領(lǐng)域的重要進(jìn)展
2024-05-14 08:06:10Open新模型:絲滑如真人又一次失?。o冠魔咒繼續(xù)困擾凱恩,,還不如西班牙隊17歲的小孩 凱恩冠軍夢碎
2024-07-15 11:53:54又一次失?。o冠魔咒繼續(xù)困擾凱恩OpenAI新模型:絲滑如真人,,GPT-4o引領(lǐng)交互新時代
5月14日深夜,美國OpenAI公司舉辦線上“春季更新”活動,,揭曉兩大核心內(nèi)容:發(fā)布最新旗艦?zāi)P虶PT-4o及在ChatGPT服務(wù)中增添多項免費功能
2024-05-14 07:49:16OpenAI新模型:絲滑如真人








