李彥宏戳破大模型跑分假象 真能力在于用戶價(jià)值增益

李彥宏戳破大模型跑分假象
新版本大模型的問(wèn)世常伴隨著與GPT-4的性能對(duì)比熱潮,企業(yè)熱衷于展示自家模型在第三方榜單上的亮眼成績(jī),,強(qiáng)調(diào)在特定指標(biāo)上已實(shí)現(xiàn)趕超,,意在彰顯其技術(shù)實(shí)力的飛躍,。然而,,百度董事長(zhǎng)李彥宏近期在內(nèi)部交流中揭示了這一現(xiàn)象背后的真相,。他指出,,盡管某些模型在部分單項(xiàng)上得分超越GPT-4,但這并不意味著它們與最前沿技術(shù)的差距已消失,。李彥宏強(qiáng)調(diào),,模型間的差異是多方面的,涵蓋基礎(chǔ)能力如理解,、生成,、邏輯推理及記憶等多個(gè)層面,同時(shí)也涉及成本效率,,即某些模型雖效能相似,,但高昂成本和較慢的推理速度使其總體上仍遜色于先進(jìn)模型,。
李彥宏還提到了測(cè)試集中常見(jiàn)的“過(guò)擬合”問(wèn)題,即模型過(guò)度適應(yīng)訓(xùn)練數(shù)據(jù),,導(dǎo)致在未見(jiàn)過(guò)的數(shù)據(jù)上表現(xiàn)欠佳,。這種現(xiàn)象反映出模型可能過(guò)于復(fù)雜,以至于捕捉到了訓(xùn)練數(shù)據(jù)中的非普遍性特征,,從而限制了其泛化能力,。盡管如此,跑分榜單仍具有一定的參考價(jià)值,,它不僅提供了量化評(píng)估模型性能的快捷方式,,也促進(jìn)了技術(shù)競(jìng)爭(zhēng)與進(jìn)步,激發(fā)了模型優(yōu)化的動(dòng)力,。
李彥宏提醒,,自媒體的炒作和新模型發(fā)布時(shí)的宣傳傾向,可能會(huì)誤導(dǎo)公眾認(rèn)為各模型間的能力差距正日益縮小,,實(shí)際情況卻并非如此,。他主張,真正檢驗(yàn)大模型能力的標(biāo)準(zhǔn)應(yīng)在于其能否在具體場(chǎng)景下滿足用戶需求并創(chuàng)造價(jià)值,,而非簡(jiǎn)單的排名比拼,。對(duì)于業(yè)界常說(shuō)的“領(lǐng)先12個(gè)月或落后18個(gè)月”的時(shí)間差,李彥宏認(rèn)為其重要性被高估,,強(qiáng)調(diào)持續(xù)創(chuàng)新與市場(chǎng)需求響應(yīng)速度才是決定市場(chǎng)份額的關(guān)鍵,。
展望未來(lái),李彥宏預(yù)測(cè)大模型間的性能差距或?qū)U(kuò)大,,因大模型的發(fā)展空間廣闊,,且需持續(xù)迭代升級(jí)以降低成本、提高效率,。此外,,他還就開(kāi)源與閉源模型、AI代理等議題分享了見(jiàn)解,,認(rèn)為在商業(yè)領(lǐng)域,,閉源模型憑借高效的資源利用和成本分?jǐn)倷C(jī)制,較開(kāi)源模型更具優(yōu)勢(shì),。至于大模型的應(yīng)用進(jìn)展,,李彥宏描繪了一條從輔助工具到具備自主性乃至獨(dú)立工作能力的AI工作者的發(fā)展路徑,并指出當(dāng)前智能體雖受關(guān)注但尚未成為普遍共識(shí),,盡管其低門檻特性使其成為模型應(yīng)用的一種簡(jiǎn)便途徑,。

NBA季前賽:公牛16分逆轉(zhuǎn)騎士拉文復(fù)出僅7分 吉迪加盟首秀11 7 - 公牛末節(jié)鎖定勝局

不足30天,美國(guó)大選進(jìn)入沖刺階段:“十月驚奇”會(huì)否再現(xiàn),?搖擺之地選情膠著

2024武網(wǎng)開(kāi)幕 鄭欽文亮相 網(wǎng)球盛宴再度開(kāi)啟
NBA季前賽:公牛16分逆轉(zhuǎn)騎士拉文復(fù)出僅7分 吉迪加盟首秀11 7 - 公牛末節(jié)鎖定勝局

尹錫悅初會(huì)石破茂 穿梭外交譜新篇

以色列空襲敘利亞首都居民樓 造成7死11傷

伊朗外長(zhǎng)敏感時(shí)刻訪問(wèn)沙特,將討論地區(qū)問(wèn)題并制止以色列“罪行”

山東一景區(qū)“跟著團(tuán)長(zhǎng)打縣城”項(xiàng)目爆火

美軍MQ-9“死神”無(wú)人機(jī)為什么接連被胡塞武裝擊落,?

黃曉明女友葉珂:爸爸不讓我信男人,,#婚姻情感記#下的選擇

戰(zhàn)火下,,近10萬(wàn)黎巴嫩人逃到敘利亞
不足30天,,美國(guó)大選進(jìn)入沖刺階段:“十月驚奇”會(huì)否再現(xiàn),?搖擺之地選情膠著
“已制定至少10種方案”,伊朗應(yīng)對(duì)以色列襲擊,,可能怎么辦,?

以總理提議將以軍“鐵劍”行動(dòng)改名為“復(fù)興戰(zhàn)爭(zhēng)”

健康三球太強(qiáng)勢(shì):24 6 5還獻(xiàn)兩記超遠(yuǎn)三分 豪言成攻防一體PG 劍指全明星

市監(jiān)局回應(yīng)外賣肉夾饃中吃到針頭 源頭調(diào)查進(jìn)行中

他救人攔下的救護(hù)車救了自己 愛(ài)心傳遞,民警獲救

黎真主黨警告以色列:若繼續(xù)襲擊黎巴嫩,,將加強(qiáng)對(duì)以打擊
2024武網(wǎng)開(kāi)幕 鄭欽文亮相 網(wǎng)球盛宴再度開(kāi)啟

《七夜雪》今晚開(kāi)播 邵羽柒化身秋水音詮釋別樣情感江湖

美媒曝:黎巴嫩大量通訊設(shè)備爆炸前,受害者被引導(dǎo)“用兩只手同時(shí)操作設(shè)備以讀取信息”

臺(tái)媒爆料:臺(tái)軍“導(dǎo)彈發(fā)射筒”流入黑幫

測(cè)試投彈出現(xiàn)故障,?防止泄密主動(dòng)擊落?俄神秘?zé)o人機(jī)墜毀烏克蘭引猜測(cè)
5篇筆記漲粉35萬(wàn),“勸學(xué)”成小紅書新流量密碼

美軍火商虛報(bào)對(duì)臺(tái)軍售費(fèi)用,,臺(tái)當(dāng)局回應(yīng)
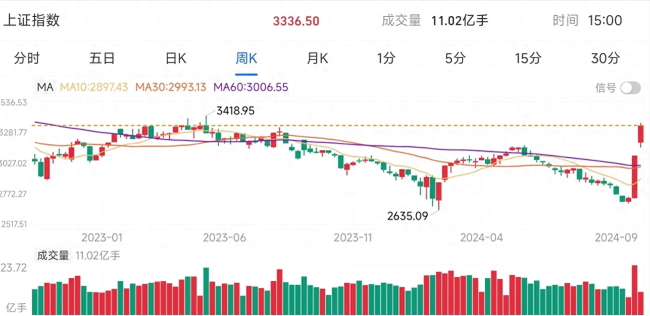
A股大跌預(yù)警:但斌警示市場(chǎng) 或迎劇烈調(diào)整

上海馬路股市沙龍又熱鬧了,!

以媒:自新一輪巴以沖突爆發(fā)以來(lái),,以色列共有728名軍事安全人員在沖突中死亡

美媒:美官員透露,,近幾周拜登政府愈加不信任以方涉軍事和外交計(jì)劃言論

陳喬恩回應(yīng)被催生:生孩子很重要嗎 個(gè)人選擇受尊重

美媒:內(nèi)塔尼亞胡“最后一刻”否決以防長(zhǎng)訪美行程,再次表明“雙方關(guān)系緊張”
這下奇怪了,,俄軍為何要……

假期出游易丟手機(jī) 廣州一游樂(lè)場(chǎng)已撿15部手機(jī)

以色列總理稱:已打死納斯魯拉的繼任者、他的繼任者的繼任者

女子回應(yīng)收了巨額禮物拉黑追求者被指玩弄感情:我和他說(shuō)了無(wú)數(shù)次“你養(yǎng)不起我”
相關(guān)新聞
李彥宏:大模型百度走在最前面,,我們要去勇闖無(wú)人區(qū)
2024-05-11 09:03:42李彥宏:大模型百度走在最前面李彥宏妻子套現(xiàn)2241萬(wàn)美元 百度股價(jià)波動(dòng)引關(guān)注
2024-08-01 08:06:42李彥宏妻子套現(xiàn)2241萬(wàn)美元李彥宏內(nèi)部評(píng)璩靜風(fēng)波 百度價(jià)值觀堅(jiān)守與革新
2024-05-10 10:02:59李彥宏內(nèi)部評(píng)璩靜風(fēng)波李彥宏點(diǎn)評(píng)璩靜事件:優(yōu)秀員工才代表真實(shí)的百度,!
2024-05-10 10:01:06李彥宏:優(yōu)秀員工才代表真實(shí)的百度李彥宏和雷軍的殊途同歸 智馭未來(lái)汽車變革
2024-07-23 06:14:36李彥宏和雷軍的殊途同歸李彥宏內(nèi)部評(píng)璩靜風(fēng)波:優(yōu)秀員工才代表真實(shí)的百度
2024-05-10 10:19:41李彥宏內(nèi)部評(píng)璩靜風(fēng)波