麻省理工借鑒GPT等訓(xùn)練機器人 創(chuàng)新架構(gòu)提升學(xué)習(xí)效率

11月4日,麻省理工學(xué)院展示了一種全新的機器人訓(xùn)練模型。該模型不再依賴于標(biāo)準(zhǔn)數(shù)據(jù)集,,而是模仿大型語言模型的大規(guī)模信息處理方式,為機器人學(xué)習(xí)新技能提供了新的途徑,。
在傳統(tǒng)模仿學(xué)習(xí)中,機器人通過跟隨執(zhí)行任務(wù)的人類或其他代理進(jìn)行學(xué)習(xí),。然而,,這種方法在面對照明變化、不同環(huán)境或新障礙等小挑戰(zhàn)時,,常常因數(shù)據(jù)不足而難以適應(yīng),。為了解決這個問題,麻省理工學(xué)院的研究團(tuán)隊借鑒了GPT-4等大型語言模型的數(shù)據(jù)處理方法,,探索了一種新的解決方案,。
新論文的主要作者王立睿指出,在語言領(lǐng)域,,數(shù)據(jù)以句子的形式存在,,但在機器人領(lǐng)域,數(shù)據(jù)具有高度的異質(zhì)性,。如果想以類似語言模型的方式進(jìn)行預(yù)訓(xùn)練,,就需要構(gòu)建一種全新的架構(gòu)。
為此,,研究團(tuán)隊引入了異構(gòu)預(yù)訓(xùn)練變壓器(HPT)這一創(chuàng)新架構(gòu)。HPT能夠整合來自不同傳感器和環(huán)境的多樣信息,,并利用變壓器技術(shù)將這些數(shù)據(jù)匯總到訓(xùn)練模型中,。值得注意的是,變壓器的規(guī)模越大,,其輸出效果也越好,。
使用該模型時,用戶只需輸入機器人的設(shè)計,、配置以及期望完成的任務(wù),,系統(tǒng)便能根據(jù)這些信息為機器人提供所需的技能。這一創(chuàng)新不僅提高了機器人學(xué)習(xí)的效率和靈活性,,也為實現(xiàn)更廣泛,、更復(fù)雜的機器人應(yīng)用奠定了堅實基礎(chǔ)。
卡內(nèi)基梅隆大學(xué)副教授戴維·赫爾德評價這項研究時表示,,他們的夢想是擁有一個通用的機器人大腦,,用戶可以直接下載并使用它,而無需進(jìn)行任何額外訓(xùn)練。雖然目前還處于這一愿景的早期階段,,但研究人員將持續(xù)努力,,希望借助規(guī)模化的優(yōu)勢,,在機器人策略方面取得像大型語言模型那樣的突破性進(jìn)展,。

戰(zhàn)火下的兒童又將經(jīng)受嚴(yán)寒!中國在聯(lián)合國為戰(zhàn)火下的兒童發(fā)聲

明年沒有“大年三十”,!都是月亮惹的禍

11月小麥現(xiàn)貨市場價格出現(xiàn)回落 小麥政策托底效果顯著

法塔赫與哈馬斯同意戰(zhàn)后共同管理加沙,,雙方仍在就具體細(xì)節(jié)進(jìn)行談判

布林肯稱尹錫悅戒嚴(yán)前美方并不知情,,否認(rèn)出現(xiàn)情報失誤

特朗普被曝想逼迫俄烏上談判桌,分析人士:嚴(yán)重懷疑可行性

65歲倪萍逆生長重返舞臺,,與蔡明重聚全場驚艷 自然之美引熱議

男子駕車夜遇東北虎攔路 驚魂一刻幸無恙

中醫(yī):多去KTV唱歌可以緩解壓力

2006年,美國嚴(yán)格審查向中國出口石墨,;2024年,,中國嚴(yán)格審查向美國出口石墨
正午要拍諜戰(zhàn)劇了!網(wǎng)傳迪麗熱巴和王凱要合作《諜報上不封頂》

敘反對派為何能輕易拿下阿勒頗 背后支持揭秘

中國海軍幫加蓬海軍修理護(hù)衛(wèi)艇 加蓬海軍參謀長提供一個細(xì)節(jié)

1家6口被沖走救援隊長收15萬消失 尋親之路再遭打擊

2025年—2029年都沒有大年三十,?月亮惹的禍 農(nóng)歷歷法揭秘

中方出手,!美行業(yè)人士抱怨:中國暗示很久了,美國什么時候才能吸取教訓(xùn),?

朔爾茨再訪基輔,,銀色新手提箱引發(fā)各種猜測,本人解開“謎團(tuán)”

金星伴月將再現(xiàn)夜空 高顏值星月童話

趙麗穎與劉亦菲:誰才是真正的扛劇女明星?

梅德韋杰夫開噴:叛徒,、懦夫,、傻瓜,通通下臺,!

“半導(dǎo)體工業(yè)新糧食”“軍用領(lǐng)域萬能添加劑”……禁止對美出口的兩用物項有哪些軍事用途,?
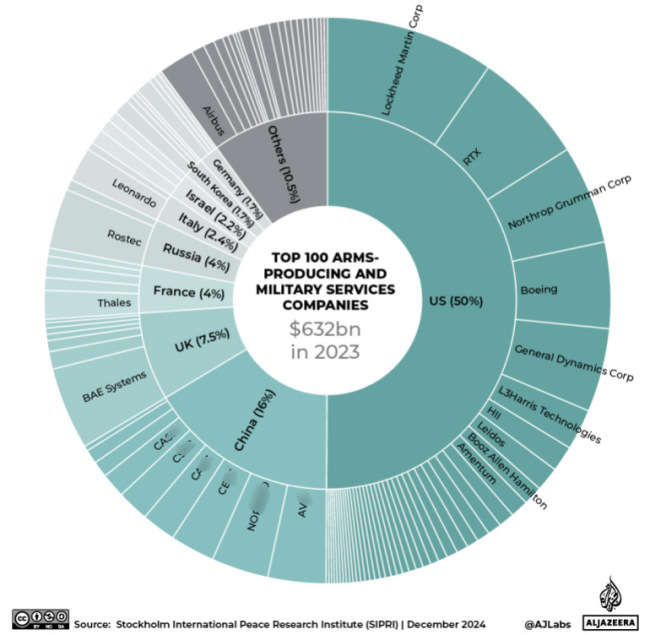
防務(wù)企業(yè)收入增長率,,俄羅斯對北約遙遙領(lǐng)先

美加大芯片制裁之時 中國半導(dǎo)體出口破萬億 反制措施彰顯決心

英超積分榜:利物浦繼續(xù)排名榜首,,17場不敗紀(jì)錄延續(xù)
戰(zhàn)火下的兒童又將經(jīng)受嚴(yán)寒,!中國在聯(lián)合國為戰(zhàn)火下的兒童發(fā)聲
明年沒有“大年三十”!都是月亮惹的禍

菲方惡意剪裁侵闖黃巖島視頻 專家:水炮攔阻已是克制,,如持續(xù)挑釁中方必將升級反制
11月小麥現(xiàn)貨市場價格出現(xiàn)回落 小麥政策托底效果顯著

7家村鎮(zhèn)銀行以及1家農(nóng)商行獲批解散 中小銀行改革化險新進(jìn)展

澳大利亞加緊與瑙魯談判,意在防范中國,?專家:看上去是交易,,實際上是脅迫

韓國事變第二天,又有新情況

菲船只惡意擦碰中國海警船視頻曝光 菲方侵權(quán)挑釁

馬來西亞最高元首警告馬國防大學(xué):立即停止霸凌文化

以防長:“有機會真正推進(jìn)”被扣押人員交換協(xié)議

繼續(xù)強化對烏軍援,,堅持不發(fā)“入約”邀請,北約外長會提及向烏克蘭派維和部隊
相關(guān)新聞
自定義GPT功能免費開放 升級用戶體驗無限制
2024-05-30 16:28:44自定義GPT功能免費開放OpenAI或?qū)⑼瞥鱿乱淮鶪PT模型 超級智能新紀(jì)元
2024-05-22 09:04:45OpenAI或?qū)⑼瞥鱿乱淮鶪PT模型機器人概念股持續(xù)爆發(fā) 人形機器人新高度
2024-11-04 11:45:17機器人概念股持續(xù)爆發(fā)機器人12分鐘裝好一臺機器人 長三角速度塑造國產(chǎn)機器人新名片
2024-05-27 07:44:03機器人12分鐘裝好一臺機器人特斯拉機器人當(dāng)服務(wù)員 拍照比“耶” 人型機器人新風(fēng)尚
2024-10-11 13:29:40特斯拉機器人當(dāng)服務(wù)員小機器人拐走一批 展廳機器人集體“回家”
2024-11-11 10:39:03小機器人拐走一批








