豆包大模型發(fā)布各領(lǐng)域技術(shù)進(jìn)展,首次披露 300 萬長文本能力!

豆包大模型發(fā)布各領(lǐng)域技術(shù)進(jìn)展,!字節(jié)跳動(dòng)旗下的豆包大模型于12月30日公布了2024年全領(lǐng)域的技術(shù)進(jìn)展,。自5月15日首次亮相以來,,該模型在通用語言,、視頻生成、語音對話,、視覺理解等方面的能力已經(jīng)躋身國際第一梯隊(duì),。
截至2024年12月,最新版的豆包通用模型Doubao-pro-1215綜合能力較5月提升了32%,,已全面對齊GPT-4o,,并在數(shù)學(xué)、專業(yè)知識等部分復(fù)雜場景任務(wù)中表現(xiàn)更佳,。其推理服務(wù)價(jià)格僅為GPT-4o的八分之一,。通過海量數(shù)據(jù)優(yōu)化及模型架構(gòu)創(chuàng)新,包括提升模型稀疏度和引入強(qiáng)化學(xué)習(xí),,該模型的理解精度和生成質(zhì)量得到了大幅提升。
豆包還首次披露了其大模型具備300萬字窗口的長文本處理能力,,能夠一次輕松閱讀上百篇學(xué)術(shù)報(bào)告,,每百萬tokens處理延遲僅15秒。這背后的技術(shù)包括上下文關(guān)聯(lián)數(shù)據(jù)算法STRING等,,這些技術(shù)顯著增強(qiáng)了LLM利用海量外部知識的能力,,并通過稀疏化及分布式方案將時(shí)延降至十秒級。
(責(zé)任編輯:盧其龍 CN070)
關(guān)閉

全國人口減少139萬人 出生人口現(xiàn)反彈
全國人口減少139萬人2025-01-17 11:09:55

美網(wǎng)友被中國一日三餐震驚 刷新認(rèn)知
美網(wǎng)友被中國一日三餐震驚2025-01-17 11:08:09

內(nèi)馬爾:離開巴薩前梅西說會(huì)讓我成世界最佳,,去巴黎不是因?yàn)檫@個(gè) 個(gè)人原因促成轉(zhuǎn)會(huì)
內(nèi)馬爾,離開巴薩前梅西說會(huì)讓我成世界最佳,去巴黎不是因?yàn)檫@個(gè)2025-01-17 11:06:16

國臺辦:希望臺當(dāng)局恢復(fù)兩岸客運(yùn)直航航點(diǎn)航班 民進(jìn)黨當(dāng)局設(shè)置障礙
希望臺當(dāng)局恢復(fù)兩岸客運(yùn)直航航點(diǎn)航班2025-01-17 10:12:05
一家五口相繼確診同種癌癥 警惕家族遺傳風(fēng)險(xiǎn)
一家五口相繼確診同種癌癥2025-01-17 11:02:58
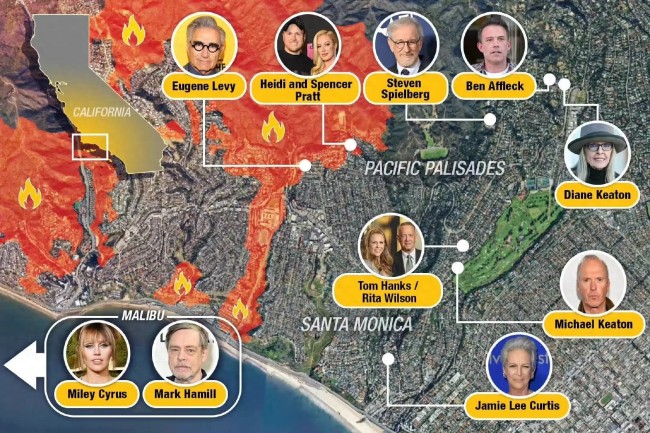
小李子捐款100萬美元支援加州山火 明星善舉暖人心
小李子捐款100萬美元支援加州山火2025-01-17 10:57:30

一旦爆發(fā)戰(zhàn)爭,,中美俄能調(diào)動(dòng)多少兵力?中國數(shù)目無法想象
一旦爆發(fā)戰(zhàn)爭,中美俄能調(diào)動(dòng)多少兵力,?中國數(shù)目無法想象2025-01-17 10:13:55

尹錫悅被捕不到24小時(shí),,美國對韓國許下承諾,中方也遞上一句話 中美相繼表態(tài)
尹錫悅被捕不到24小時(shí)2025-01-17 10:06:35

泰國總理自曝遭電詐:差點(diǎn)就信了,!
泰國總理自曝遭電詐,差點(diǎn)就信了2025-01-17 10:52:04

星艦第一級助推器被發(fā)射塔回收,但第二級飛船失聯(lián)
星艦第一級助推器被發(fā)射塔回收2025-01-17 10:10:38

特朗普突然發(fā)聲,,公布了一份“白宮黑名單” 排除異己名單揭曉
特朗普突然發(fā)聲,公布了一份白宮黑名單2025-01-17 10:08:19

特朗普列出“黑名單”:不會(huì)聘用與彭斯、博爾頓,、黑利等人存在關(guān)聯(lián)的人士 強(qiáng)調(diào)忠誠度
特朗普列出黑名單,不會(huì)聘用與彭斯,博爾頓,黑利等人存在關(guān)聯(lián)的人士2025-01-17 10:10:06

俄稱打擊烏軍用機(jī)場 烏稱襲擊俄油庫 雙方?jīng)_突持續(xù)升級
俄稱打擊烏軍用機(jī)場烏稱襲擊俄油庫2025-01-17 11:02:02

萬科去年拿地金額103億 盤活存量閑置產(chǎn)能474億元
萬科去年拿地金額103億2025-01-17 11:03:15
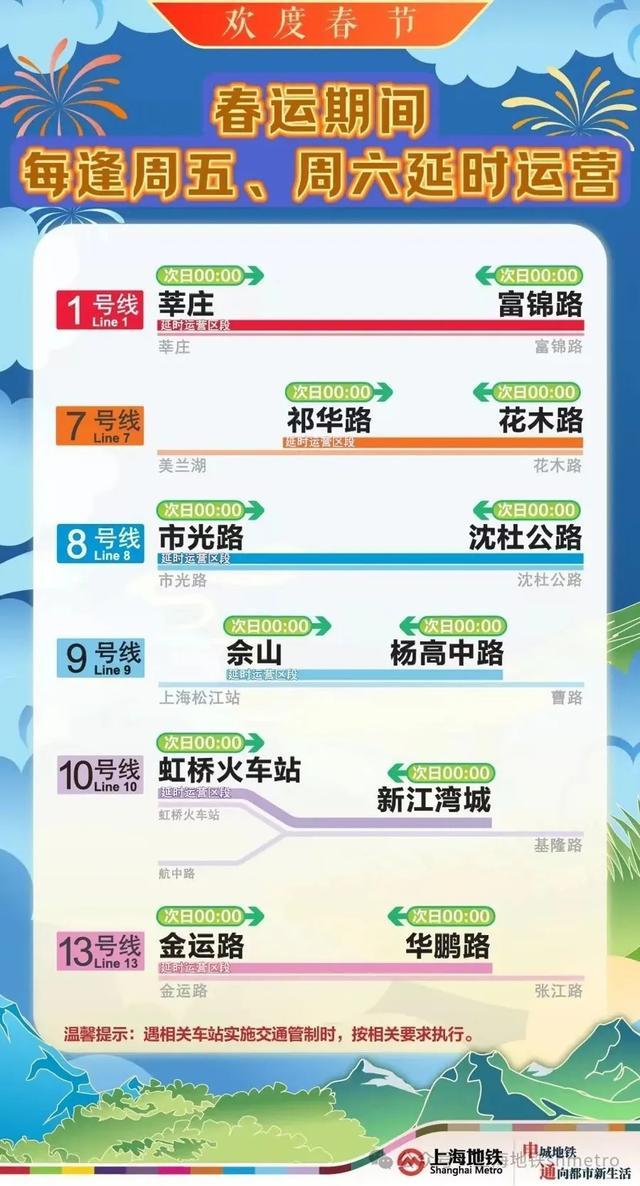
上海地鐵將增開定點(diǎn)加班車 春運(yùn)期間多線延時(shí)運(yùn)營
上海地鐵將增開定點(diǎn)加班車2025-01-17 10:58:50

案發(fā)130年后發(fā)現(xiàn)重要證據(jù),,“開膛手杰克”連環(huán)殺人案真兇浮出水面!
開膛手杰克連環(huán)殺人案真兇浮出水面2025-01-17 10:59:31

烏克蘭曝出重大丑聞,!俄軍不用再打了,?澤連斯基萬沒想到,局勢變天
烏克蘭曝出重大丑聞2025-01-17 10:11:49
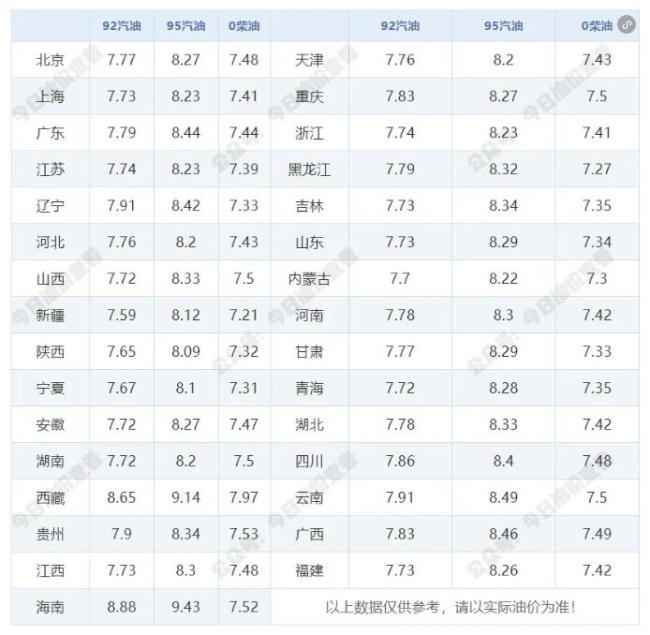
油價(jià)大漲,!1月17日調(diào)整后92號汽油價(jià)格 每升漲0.27元
油價(jià)大漲,1月17日調(diào)整后92號汽油價(jià)格2025-01-17 11:04:44
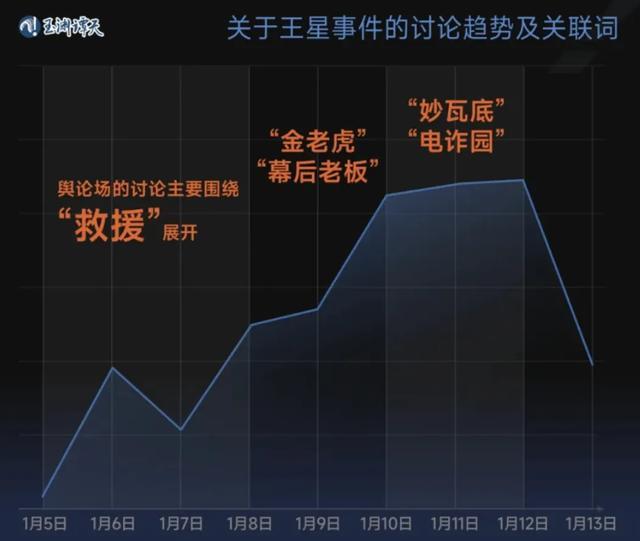
為何不在妙瓦底執(zhí)法,?中方正開展調(diào)查 聯(lián)合執(zhí)法需研判與合作
為何不在妙瓦底執(zhí)法,中方正開展調(diào)查2025-01-17 10:05:27

尹錫悅被審訊沉默 晚餐只吃燉菜 全程拒絕回答問題
尹錫悅被審訊沉默晚餐只吃燉菜2025-01-17 10:11:27
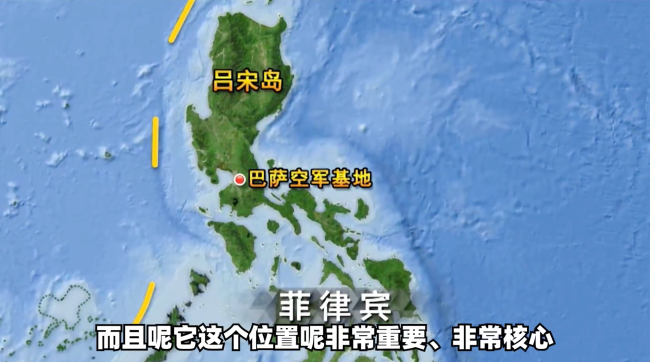
美菲本月將舉行無人機(jī)聯(lián)合演習(xí),演什么,?
美菲本月將舉行無人機(jī)聯(lián)合演習(xí),,演什么?2025-01-17 10:39:55

商務(wù)部:2024全年商務(wù)運(yùn)行總體平穩(wěn) 穩(wěn)中有進(jìn)態(tài)勢良好
2024全年商務(wù)運(yùn)行總體平穩(wěn)2025-01-17 10:59:12

拜登告別演講,,稱“中國永遠(yuǎn)不會(huì)超越美國”,,外交部回應(yīng)反將一軍 歷史終將證明一切
中國永遠(yuǎn)不會(huì)超越美國2025-01-17 10:09:00
美網(wǎng)友被中國一日三餐震驚 刷新認(rèn)知
美網(wǎng)友被中國一日三餐震驚2025-01-17 11:08:09

國際油價(jià)1月16日下跌 新華社報(bào)道引發(fā)關(guān)注
國際油價(jià)1月16日下跌2025-01-17 10:56:57

英首相訪烏時(shí)一架俄無人機(jī)被擊落 無人機(jī)飛越烏總統(tǒng)府上空畫面曝光
英首相訪烏時(shí)一架俄無人機(jī)被擊落 無人機(jī)飛越烏總統(tǒng)府上空畫面曝光2025-01-17 10:35:31

停火協(xié)議剛達(dá)成 以軍又炸加沙 襲擊致數(shù)十人亡
?;饏f(xié)議剛達(dá)成以軍又炸加沙2025-01-17 10:05:45
全國人口減少139萬人 出生人口現(xiàn)反彈
全國人口減少139萬人2025-01-17 11:09:55

楊冪深夜下班路透,!夜色下也能清晰感受到冪冪的美
楊冪深夜下班路透2025-01-17 11:01:43
內(nèi)馬爾:離開巴薩前梅西說會(huì)讓我成世界最佳,去巴黎不是因?yàn)檫@個(gè) 個(gè)人原因促成轉(zhuǎn)會(huì)
內(nèi)馬爾,離開巴薩前梅西說會(huì)讓我成世界最佳,去巴黎不是因?yàn)檫@個(gè)2025-01-17 11:06:16

2024年GDP同比增長5.0% 經(jīng)濟(jì)目標(biāo)順利完成
2024年GDP同比增長5,0%2025-01-17 11:00:47

不許中方援俄,,美制裁中國企業(yè)后,,不到72小時(shí),中方反制來了 反傾銷調(diào)查啟動(dòng)
不許中方援俄,美制裁中國企業(yè)后,不到72小時(shí),中方反制來了2025-01-17 10:50:43

小米汽車門店轉(zhuǎn)賣華為 工作人員回應(yīng) 暫停營業(yè)選新址
小米汽車門店轉(zhuǎn)賣華為工作人員回應(yīng)2025-01-17 11:00:03

美股七巨頭一夜蒸發(fā)超2萬億 科技股集體下挫
美股七巨頭一夜蒸發(fā)超2萬億2025-01-17 10:17:37

2024中國GDP增長5% 經(jīng)濟(jì)穩(wěn)步前行
2024中國GDP增長5%2025-01-17 11:05:00
相關(guān)新聞
業(yè)內(nèi):持續(xù)關(guān)注大模型四個(gè)技術(shù)方向 探索金融領(lǐng)域應(yīng)用
2024-12-26 19:09:01持續(xù)關(guān)注大模型四個(gè)技術(shù)方向豆包大模型推出視覺大模型:視覺理解模型進(jìn)入“厘時(shí)代” 更強(qiáng)理解與推理能力
2024-12-18 13:34:32豆包大模型推出視覺大模型字節(jié)跳動(dòng)商業(yè)化團(tuán)隊(duì)模型訓(xùn)練被“投毒”,,內(nèi)部人士稱未影響豆包大模型 實(shí)習(xí)生不滿引發(fā)技術(shù)襲擊
2024-10-19 14:11:35字節(jié)跳動(dòng)商業(yè)化團(tuán)隊(duì)模型訓(xùn)練被“投毒”上百家機(jī)構(gòu),,調(diào)研這一領(lǐng)域 豆包概念股熱度持續(xù)
2024-12-13 09:50:51豆包概念股熱度持續(xù)各領(lǐng)域多行業(yè)新進(jìn)展,、新突破 充滿生機(jī)與活力!
2024-08-05 17:45:05各領(lǐng)域多行業(yè)新進(jìn)展,、新突破北京又一大模型落地醫(yī)療場景 智覽醫(yī)療大模型微調(diào)平臺發(fā)布
2024-11-16 13:45:00北京又一大模型落地醫(yī)療場景








