顯卡可能沒(méi)那么重要了?中國(guó)公司給硅谷好好上了一課 新年驚喜震撼西方

顯卡可能沒(méi)那么重要了,!我是萬(wàn)萬(wàn)沒(méi)想到,,就在西方還沉浸在圣誕假期,,瘋狂“過(guò)年”的時(shí)候,咱們中國(guó)企業(yè)給人家放了個(gè)新年二踢腳,給人家腦瓜子崩得嗡嗡得。
前有宇樹(shù)科技的機(jī)器狗視頻讓大家驚呼,還要啥波士頓動(dòng)力,。
緊接著又來(lái)了個(gè)
國(guó)產(chǎn)大模型DeepSeek,甚至有股做空英偉達(dá)的味道,。具體咋回事兒,,咱給你嘮明白咯。前幾天,,DeepSeek剛剛公布最新版本V3,,注意,與大洋彼岸那個(gè)自稱(chēng)Open,,卻越來(lái)越Close的公司產(chǎn)品不同,,這個(gè)V3是開(kāi)源的。
不過(guò)開(kāi)源還不是他最重要的標(biāo)簽,,DeepSeek-V3
(以下簡(jiǎn)稱(chēng)V3)
還兼具了性能?chē)?guó)際一流,,技術(shù)力牛逼,價(jià)格擊穿地心三個(gè)特點(diǎn),,這一套不解釋連招打得業(yè)內(nèi)大模型廠商們都有點(diǎn)暈頭轉(zhuǎn)向了,。
V3一發(fā)布,OpenAI創(chuàng)始成員Karpathy直接看嗨了,,甚至發(fā)出了靈魂提問(wèn),,
難道說(shuō)大模型們壓根不需要大規(guī)模顯卡集群?
我估計(jì)老黃看到這頭皮都得發(fā)麻了吧,。
同時(shí),,Meta的AI技術(shù)官也是直呼
DeepSeek的成果偉大
。
知名 AI 評(píng)測(cè)博主 Tim Dettmers ,,直接吹起來(lái)了,,表示 DeepSeek 的處理優(yōu)雅 “elegant” 。
而在這些技術(shù)出身的人,,看著V3的成績(jī)送去贊揚(yáng)的時(shí)候,,也有些人急了。
比如奧特曼就擱那說(shuō),,
復(fù)制比較簡(jiǎn)單啦
,,很難不讓人覺(jué)得他在內(nèi)涵DeepSeek。
更有意思的是,,做到這些的公司既不是什么大廠,,也不是純血AI廠商。
DeepSeek公司中文名叫深度求索,,他們本來(lái)和AI沒(méi)任何關(guān)系,。
就在大模型爆火之前,他們
其實(shí)是私募機(jī)構(gòu)幻方量化的一個(gè)團(tuán)隊(duì)
,。
而深度求索能夠?qū)崿F(xiàn)彎道超車(chē),,既有點(diǎn)必然,也好像有點(diǎn)運(yùn)氣的意思,。
早在2019年,,幻方就投資2億元搭建了自研深度學(xué)習(xí)訓(xùn)練平臺(tái)“螢火蟲(chóng)一號(hào)”,到了2021年已經(jīng)買(mǎi)了足足1萬(wàn)張英偉達(dá)A100顯卡的算力儲(chǔ)備了,。
要知道,,這個(gè)時(shí)候大模型沒(méi)火,萬(wàn)卡集群的概念更是還沒(méi)出現(xiàn),。
而正是憑借這部分硬件儲(chǔ)備,,幻方才拿到了AI大模型的入場(chǎng)券,最終卷出了現(xiàn)在的V3,。
你說(shuō)好好的一個(gè)量化投資領(lǐng)域的大廠,,干嘛要跑來(lái)搞AI呢?
深度求索的CEO梁文鋒在接受暗涌采訪的時(shí)候給大家聊過(guò),,并不是什么看中AI前景,。
而是在他們看來(lái),“
通用人工智能可能是下一個(gè)最難的事之一
”,,對(duì)他們來(lái)說(shuō),,“這是一個(gè)怎么做的問(wèn)題,而不是為什么做的問(wèn)題,?!?/p>
就是抱著這么股“莽”勁,深度求索才搞出了這次的大新聞,,下面給大家具體講講V3有啥特別的地方,。
首先就是性能強(qiáng)悍,目前來(lái)看,,在V3面前,,開(kāi)源模型幾乎沒(méi)一個(gè)能打的。
還記得去年年中,,小扎的 Meta 推出模型 Llama 3.1 ,,當(dāng)時(shí)就因?yàn)樾阅軆?yōu)秀而且開(kāi)源,一時(shí)間被捧上神壇,,結(jié)果在 V3 手里,,基本
是全面落敗
,。
而在各種大廠手里的閉源模型,那些大家耳熟能詳?shù)氖裁?GPT-4o ,、 Claude 3.5 Sonnet 啥的,, V3 也能打得有來(lái)有回。
你看到這,,可能覺(jué)得不過(guò)如此,,也就是追上了國(guó)際領(lǐng)先水平嘛,值得這么吹嗎,?
殘暴的還在后面,。
大家大概都知道了,現(xiàn)在的大模型就是一個(gè)通過(guò)大量算力,,讓模型吃各種數(shù)據(jù)的煉丹過(guò)程,。
在這個(gè)煉丹期,需要的是大量算力和時(shí)間往里砸,。
所以在圈子里有了一個(gè)新的計(jì)量單位“GPU時(shí)”,,也就是用了多少塊GPU花了多少個(gè)小時(shí)的訓(xùn)練時(shí)間。
GPU時(shí)越高,,意味著花費(fèi)的時(shí)間,、金錢(qián)成本就越高,反之就物美價(jià)廉了,。
前面說(shuō)的此前開(kāi)源模型王者,, Llama 3.1 405B ,訓(xùn)練周期花費(fèi)了 3080 萬(wàn) GPU 時(shí),。
可性能更強(qiáng)的V3,,
只花了不到280萬(wàn)GPU時(shí)
。
以錢(qián)來(lái)?yè)Q算,,DeepSeek搞出V3版本,,大概只花了4000多萬(wàn)人民幣。
而 Llama 3.1 405B 的訓(xùn)練期間,, Meta 光是在老黃那買(mǎi)了 16000 多個(gè) GPU ,,保守估計(jì)至少都花了十幾億人民幣。
至于另外的那幾家閉源模型,,動(dòng)輒都是幾十億上百億大撒幣的,。
你別以為DeepSeek靠的是什么歪門(mén)邪道,人家是正兒八經(jīng)的有技術(shù)傍身的,。
為了搞清楚DeepSeek的技術(shù)咋樣,,咱們特地聯(lián)系了語(yǔ)核科技創(chuàng)始人兼CTO池光耀,他們主力發(fā)展企業(yè)向的agent數(shù)字員工,,早就是DeepSeek的鐵粉了,。
池光耀告訴我們,,這次V3的更新主要是3個(gè)方面的優(yōu)化,分別是
通信和顯存優(yōu)化
,、
推理專(zhuān)家的負(fù)載均衡
以及
FP8混合精度訓(xùn)練
,。
各個(gè)部分怎么實(shí)現(xiàn)的咱也就不多說(shuō)了,總體來(lái)說(shuō),,大的整體結(jié)構(gòu)沒(méi)啥變化,更多的像是咱們搞基建的那一套傳統(tǒng)藝能,,把工程做得更高效,、更合理了。
首先,,V3通過(guò)通信和顯存優(yōu)化,,極大幅度
減少了資源空閑率
,提升了利用效率,。
而推理專(zhuān)家
(具備推理能力的AI系統(tǒng)或算法,,能夠通過(guò)數(shù)據(jù)分析得出結(jié)論)
的負(fù)載均衡就更巧妙了,一般的大模型,,每次啟動(dòng),,必須把所有專(zhuān)家都等比例放進(jìn)工位
(顯存)
,但真正回答用戶(hù)問(wèn)題時(shí),,十幾個(gè)專(zhuān)家里面只用到一兩個(gè),,剩下的專(zhuān)家占著工位
(顯存)
摸魚(yú),也干不了別的事情,。
而DeepSeek把專(zhuān)家分成熱門(mén)和冷門(mén)兩種,,
熱門(mén)的專(zhuān)家,復(fù)制一份放進(jìn)顯存,,處理熱門(mén)問(wèn)題,;冷門(mén)的專(zhuān)家也不摸魚(yú),總是能被分配到問(wèn)題
,。
FP8混合精度訓(xùn)練則是在之前被很多團(tuán)隊(duì)嘗試無(wú)果的方向上拓展了新的一步,,通過(guò)降低訓(xùn)練精度以降低訓(xùn)練時(shí)算力開(kāi)銷(xiāo),但卻神奇地保持了回答質(zhì)量基本不變,。
也正是這些技術(shù)上的革新,,才得到了大模型圈的一致好評(píng)。
通過(guò)一直以來(lái)的技術(shù)更新迭代,,DeepSeek收獲的回報(bào)也是相當(dāng)驚人的,。
他們V3版本推出后,他們的價(jià)格已經(jīng)是
低到百萬(wàn)tokens幾毛錢(qián),、幾塊錢(qián)
,。
他們甚至還在搞了個(gè)新品促銷(xiāo)活動(dòng),,到明年2月8號(hào)之前,在原來(lái)低價(jià)的基礎(chǔ)上再打折,。
而一開(kāi)始提到同樣開(kāi)源的 Claude 3.5 Sonnet ,,每百萬(wàn)tokens,至少都得要幾十塊以上,。,。。
更要命的是,,這對(duì)DeepSeek來(lái)說(shuō)已經(jīng)是常規(guī)套路了,。
早在去年初,
DeepSeek V2 模型發(fā)布后,,就靠著一手低價(jià),,被大家叫做了AI 界拼多多。
他們還進(jìn)一步
引發(fā)了國(guó)內(nèi)大模型公司的價(jià)格戰(zhàn),,
諸如智譜,、字節(jié)、阿里,、百度,、騰訊等大廠紛紛降價(jià)。
池光耀也告訴我們,,他們公司早在去年6,、7月份就開(kāi)始用上了DeepSeek,當(dāng)時(shí)也有國(guó)內(nèi)其他一些大模型廠商來(lái)找過(guò)他們,。
但和DeepSeek價(jià)格差不多的,,模型
“又太笨了
,
跟DeepSeek不在一個(gè)維度
”,;如果模型能力和DeepSeek差不多,,那個(gè)價(jià)格“
基本都是10倍以上
”。
更夸張的是,,由于技術(shù)“遙遙領(lǐng)先”帶來(lái)的降本增效,,哪怕DeepSeek賣(mài)得這么便宜,根據(jù)他們創(chuàng)始人梁文峰所說(shuō),,
他們公司還是賺錢(qián)的
,。。,。是不是有種隔壁比亞迪搞998,,照樣財(cái)報(bào)飄紅的味道了。
不過(guò)對(duì)于我們普通用戶(hù)來(lái)說(shuō),,DeepSeek似乎也有點(diǎn)偏門(mén)了,。
因?yàn)樗膹?qiáng)項(xiàng)主要是在推理,、數(shù)學(xué)、代碼方向,,而多模態(tài)和一些娛樂(lè)化的領(lǐng)域不是他們的長(zhǎng)處,。
而且眼下,盡管DeepSeek說(shuō)自己還是賺錢(qián)的,,但他們團(tuán)隊(duì)上上下下都有股極客味,,所以他們的商業(yè)化比起其他廠商就有點(diǎn)弱了。
但不管怎么說(shuō),,DeepSeek的成功也證明了,,在AI這個(gè)賽道還存在的更多的可能。
按以前的理解,,想玩轉(zhuǎn)AI后面沒(méi)有個(gè)金主爸爸砸錢(qián)買(mǎi)顯卡,壓根就玩不轉(zhuǎn),。
但現(xiàn)在看起來(lái),,掌握了算力并不一定就是掌握了一切。
我們不妨期待下未來(lái),,更多的優(yōu)化出現(xiàn),,讓更多的小公司、初創(chuàng)企業(yè)都能進(jìn)入AI領(lǐng)域,,差評(píng)君總感覺(jué),,那才是真正的AI浪潮才對(duì)。

算下2024年人均經(jīng)濟(jì)賬:可支配收入增加2000元 居民消費(fèi)能力提升

女孩玩煙花遭反沖炸毀衣服,,提醒:小孩玩煙花時(shí)一定要在身邊陪護(hù)
臺(tái)測(cè)試封殺小紅書(shū)遭網(wǎng)友嘲諷 美國(guó)夢(mèng)變驚魂記
臺(tái)測(cè)試封殺小紅書(shū)遭網(wǎng)友嘲諷 美國(guó)夢(mèng)變驚魂記

中國(guó)新突破震撼全球,,美國(guó)竟因此掀起反印風(fēng)潮!
女孩玩煙花遭反沖炸毀衣服,,提醒:小孩玩煙花時(shí)一定要在身邊陪護(hù)

《白月梵星》敖瑞鵬解鎖妖王角色 顏值與氣質(zhì)并存

尹錫悅被批捕后數(shù)百名鐵粉打砸法院 支持者闖入破壞

26歲漸凍癥女孩求助蔡磊,,蔡磊回復(fù)了:她的病情已不符合臨床入組條件

CBA最新積分榜:廣廈9連勝第一,穩(wěn)固榜首位置

周鴻祎用車(chē)?yán)遄咏o大家拜早年了:新的一年,,愿大家一起福氣多多,,幸運(yùn)滿(mǎn)滿(mǎn)

特朗普第二次就職儀式會(huì)有哪些不同 嚴(yán)寒改室內(nèi),團(tuán)結(jié)成主題

民調(diào)稱(chēng)美民眾對(duì)特朗普政策的支持更高 內(nèi)政優(yōu)先情緒上升
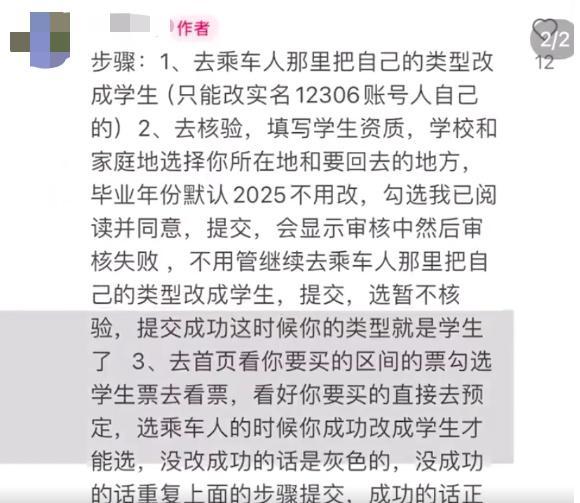
12306回應(yīng)有人裝成學(xué)生搶票 違規(guī)操作將受罰

77名支持巴勒斯坦示威者與倫敦警方發(fā)生沖突后被捕 最嚴(yán)重犯罪升級(jí)

伊朗又公開(kāi)一處軍事基地 地下500米深處存放攻擊艇

江蘇90后姑娘成央視蛇年春晚主持人 還是《新聞聯(lián)播》首位90后主播
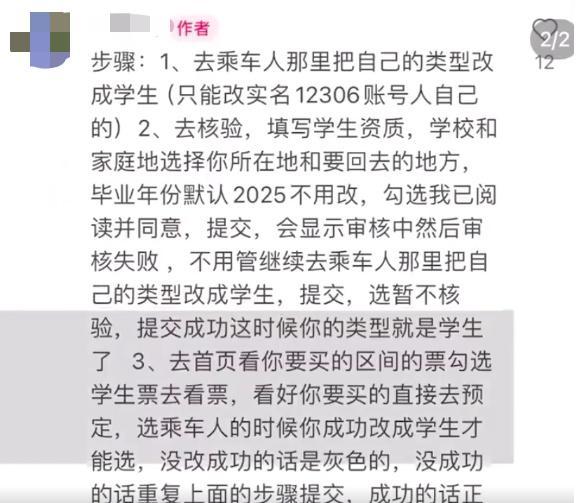
12306溫馨提示:“乘客偽裝學(xué)生身份搶學(xué)生票,,進(jìn)站補(bǔ)成人票”不符合規(guī)定 違規(guī)購(gòu)票將受罰

民進(jìn)黨臺(tái)南大罷免說(shuō)明會(huì)喊停被批 假仙行為遭揭露

庫(kù)爾斯克閉環(huán),,俄軍想要包烏軍餃子?
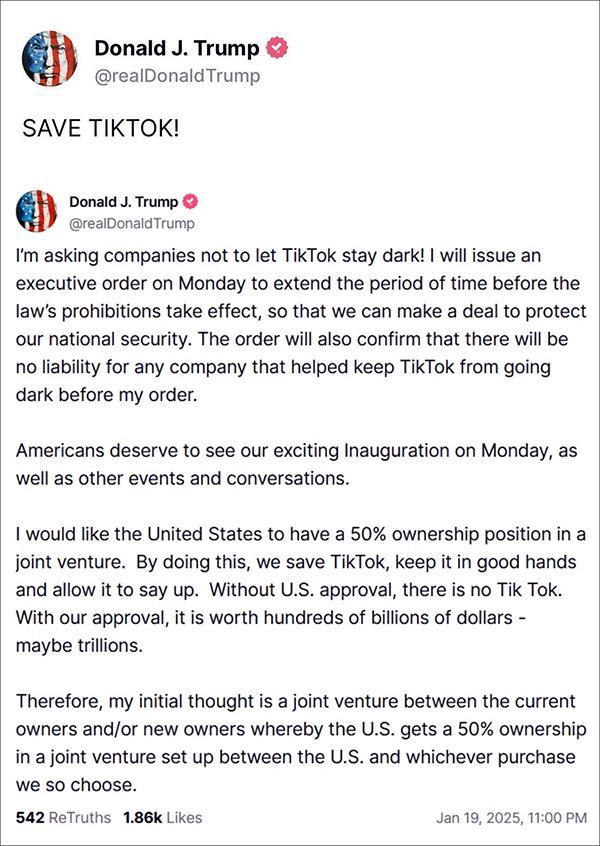
特朗普:救救TikTok,周一我就簽新命令恢復(fù) 爭(zhēng)取時(shí)間達(dá)成協(xié)議

特朗普再次對(duì)華示好 上任百日內(nèi)訪華 拜登陷入尷尬 中美關(guān)系迎來(lái)新契機(jī)
陳喬恩為網(wǎng)紅小狗艾特發(fā)聲 呼吁嚴(yán)懲虐動(dòng)物行為

北約要親自下場(chǎng),?爆炸性消息傳出,,普京被激怒,,難怪特朗普喊話(huà)和談 北約波蘭動(dòng)作頻頻

尹錫悅結(jié)局已定?美日迅速拋棄 首位被捕總統(tǒng)恐難逃鐵窗
特朗普宣布發(fā)行加密貨幣 市值飆升引爭(zhēng)議

TikTok稱(chēng)將尋找在美可用的長(zhǎng)期方案 服務(wù)已恢復(fù)
年輕人開(kāi)始整頓年味 新年飲品新潮流

現(xiàn)在是入手黃金的好時(shí)機(jī)嗎 金價(jià)創(chuàng)歷史新高引發(fā)關(guān)注
特朗普妻子發(fā)行虛擬幣MELANIA 家族成員或?qū)⒏M(jìn)

尹錫悅將拍嫌犯大頭照 換上囚服接受調(diào)查
算下2024年人均經(jīng)濟(jì)賬:可支配收入增加2000元 居民消費(fèi)能力提升

一圖梳理美國(guó)總統(tǒng)就職典禮儀式感 見(jiàn)證權(quán)力交接的傳統(tǒng)慶典

Tiktok用戶(hù)驚魂14小時(shí) 美國(guó)用戶(hù)涌入小某書(shū)

小紅書(shū)博主整頓外國(guó)人審美 挑戰(zhàn)媚外現(xiàn)象
相關(guān)新聞
美國(guó)的一場(chǎng)颶風(fēng) 可能要把顯卡干漲價(jià)了
2024-10-09 10:02:29美國(guó)的一場(chǎng)颶風(fēng)全紅嬋說(shuō)這屆金牌沒(méi)那么重了 心態(tài)更成熟
2024-08-07 10:46:29全紅嬋說(shuō)這屆金牌沒(méi)那么重了女生在森林公園上班工作是巡山:很滿(mǎn)意,,班味沒(méi)那么重
00后女孩謙謙在云南普洱太陽(yáng)河森林公園工作,,她在網(wǎng)上發(fā)布了與白眉長(zhǎng)臂猿的日常互動(dòng),,引發(fā)眾多網(wǎng)友點(diǎn)贊,。
2024-07-12 10:39:07女生在森林公園上班工作是巡山顯卡說(shuō)漲價(jià)就漲價(jià)!英偉達(dá)全球GPU市場(chǎng)占比90%:AMD,、英特爾沒(méi)存在感 壟斷地位愈發(fā)穩(wěn)固
英偉達(dá)在GPU市場(chǎng)的主導(dǎo)地位持續(xù)增強(qiáng),,人們期望AMD和Intel能展現(xiàn)出更強(qiáng)的競(jìng)爭(zhēng)力
2024-12-13 15:38:56英偉達(dá)全球GPU市場(chǎng)占比90%英特爾預(yù)告 12 月 3 日公布“顯卡大消息”,預(yù)計(jì)發(fā)布銳炫 B 系列獨(dú)立顯卡 公版顯卡即將亮相
2024-12-02 10:07:02英特爾預(yù)告 12 月 3 日公布“顯卡大消息”智能音箱,白給都沒(méi)人要了,?
2024-12-24 13:53:29智能音箱白給都沒(méi)人要了








