DeepSeek又有重大突破 開源大模型性能卓越

DeepSeek發(fā)布了新一代開源大模型DeepSeek-R1。該模型在數(shù)學(xué),、代碼,、自然語(yǔ)言推理等任務(wù)上的性能與美國(guó)OpenAI公司的最新o1大模型相當(dāng),。根據(jù)數(shù)據(jù),DeepSeek-R1在算法類代碼場(chǎng)景(Codeforces)和知識(shí)類測(cè)試(GPQA,、MMLU)中的得分略低于OpenAI o1,,但在工程類代碼場(chǎng)景(SWE-Bench Verified),、美國(guó)數(shù)學(xué)競(jìng)賽(AIME 2024, MATH)項(xiàng)目上表現(xiàn)更優(yōu),。
與之前發(fā)布的DeepSeek-V3相比,DeepSeek-R1在AIME 2024和Codeforces中的得分提升了近一倍,,其他方面也有所提升,。深度求索更新了用戶協(xié)議,明確模型開源許可將使用標(biāo)準(zhǔn)的MIT許可,,并允許用戶利用模型輸出訓(xùn)練其他模型,。數(shù)據(jù)顯示,在基于DeepSeek-R1進(jìn)行“蒸餾”的6個(gè)小模型中,,32B和70B模型在多項(xiàng)能力上對(duì)標(biāo)了OpenAI的o1-mini,。
深度求索表示,DeepSeek-R1后訓(xùn)練階段大量使用了強(qiáng)化學(xué)習(xí)技術(shù),,在極少人工標(biāo)注數(shù)據(jù)的情況下顯著提升了模型推理能力,,幾乎跳過(guò)了監(jiān)督微調(diào)步驟。這使得DeepSeek-R1能夠自我優(yōu)化,,生成更符合人類偏好的內(nèi)容,。盡管強(qiáng)化學(xué)習(xí)需要大量反饋且計(jì)算成本高,但其優(yōu)勢(shì)在于不依賴高質(zhì)量的人工標(biāo)注數(shù)據(jù),。
值得注意的是,,深度求索還開發(fā)了一個(gè)完全通過(guò)大規(guī)模強(qiáng)化學(xué)習(xí)替代監(jiān)督微調(diào)的大模型DeepSeek-R1-Zero,但因存在一些問(wèn)題未對(duì)外公開,。工作人員發(fā)現(xiàn),,在自我學(xué)習(xí)過(guò)程中,DeepSeek-R1-Zero出現(xiàn)了復(fù)雜行為,,如自我反思,、評(píng)估先前步驟、自發(fā)尋找替代方案的情況,,甚至有一次“尤里卡時(shí)刻”,。這種現(xiàn)象表明模型學(xué)會(huì)了用擬人化的語(yǔ)氣進(jìn)行自我反思,并主動(dòng)為問(wèn)題分配更多時(shí)間重新思考,。
盡管DeepSeek-R1-Zero展示出強(qiáng)大的推理能力,,但也出現(xiàn)了一些語(yǔ)言混亂及可讀性問(wèn)題。為此,,深度求索引入數(shù)千條高質(zhì)量冷啟動(dòng)數(shù)據(jù)和多段強(qiáng)化學(xué)習(xí)來(lái)解決這些問(wèn)題,,最終推出了正式版的DeepSeek-R1,。目前,DeepSeek-R1 API服務(wù)定價(jià)為每百萬(wàn)輸入tokens 1元(緩存命中)/4元(緩存未命中),,每百萬(wàn)輸出tokens 16元,。

美國(guó)西雅圖機(jī)場(chǎng)兩飛機(jī)碰撞 乘客經(jīng)歷意外顛簸

泰國(guó)總理身穿羽絨服抵達(dá)哈爾濱 展現(xiàn)清新少女感

小S主動(dòng)告知節(jié)目需要請(qǐng)假半年 處理家事暫別熒屏

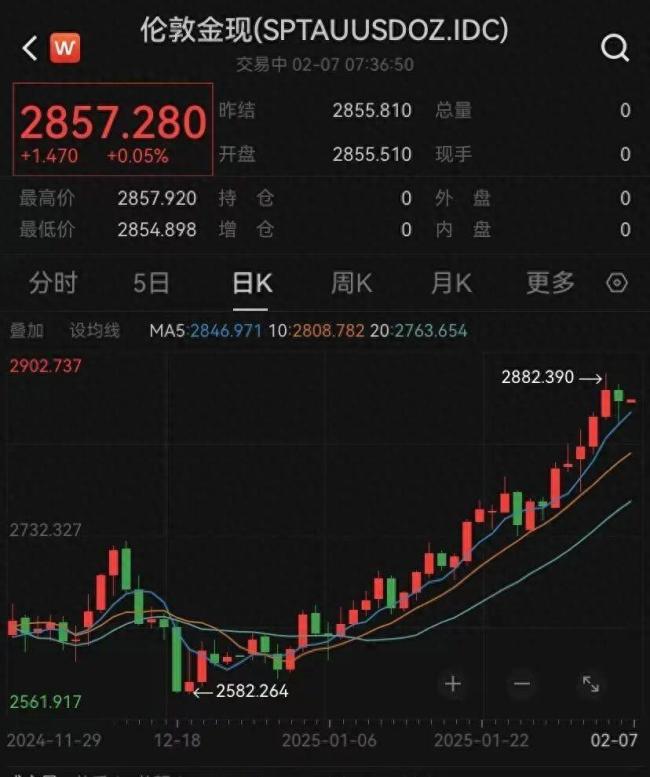
國(guó)際金價(jià)承壓下跌 美元走強(qiáng)施壓
美國(guó)西雅圖機(jī)場(chǎng)兩飛機(jī)碰撞 乘客經(jīng)歷意外顛簸

金價(jià)上漲小克重產(chǎn)品成主流

國(guó)航海航東航等均現(xiàn)加價(jià)選座,專家稱已違反價(jià)格法,!

霍啟剛觀看冰壺比賽助力亞冬會(huì) 香港代表團(tuán)團(tuán)長(zhǎng)率先抵達(dá)
專家:烏擔(dān)心自己成大國(guó)交易犧牲品 美國(guó)似乎更重視與俄羅斯溝通

伊能靜秦昊哈利聚餐 溫馨家庭時(shí)光

好萊塢明星訪烏克蘭天價(jià)酬金曝光 USAID巨額支出引發(fā)爭(zhēng)議
請(qǐng)警惕,!DeepSeek最新官方聲明!謹(jǐn)防仿冒賬號(hào)詐騙

菲律賓副總統(tǒng)回應(yīng)被彈劾:未考慮辭職,,將與律師討論法律程序

學(xué)者:外交部涉中柬關(guān)系辟謠很及時(shí) 駁斥無(wú)端造謠攻擊
有人正將大量黃金從倫敦運(yùn)往紐約 華爾街搶購(gòu)熱潮引發(fā)關(guān)注

特朗普廢除“出生公民權(quán)”行政令,,被叫停!司法部提出上訴

美國(guó)的“深層國(guó)家”是什么來(lái)頭,?

丹麥斥巨資買保暖襪抵抗美國(guó) 應(yīng)對(duì)極寒威脅

烏軍掀起反攻高潮?一天8次進(jìn)攻俄軍 付出慘痛代價(jià)
小S主動(dòng)告知節(jié)目需要請(qǐng)假半年 處理家事暫別熒屏

國(guó)乒女雙包攬冠亞軍 決賽會(huì)師鎖定勝局

林孝埈超燃時(shí)刻:1000米外道帥氣超車

專家:石破茂首要任務(wù)避免遭美討厭 建立個(gè)人信任關(guān)系

特朗普接管加沙言論震驚顧問(wèn) 引發(fā)國(guó)際廣泛關(guān)注

全世界大資金現(xiàn)在只能三選一:押中國(guó),、押美國(guó),,買黃金 德銀研報(bào)引發(fā)市場(chǎng)熱議

狗子跟女子搶樹枝躲過(guò)“掃堂腿″

亞奧理事會(huì)總干事為哈爾濱點(diǎn)贊 籌備工作獲高度評(píng)價(jià)

CIA對(duì)華情報(bào)人員被郵件曝光名字

王楚欽正手一箭穿心,網(wǎng)友:簡(jiǎn)直太牛了

內(nèi)塔尼亞胡送特朗普黃金尋呼機(jī) 象征以色列技術(shù)優(yōu)勢(shì)

美國(guó)最新彈道導(dǎo)彈核潛艇為何難產(chǎn) 美軍高端武器制造面臨挑戰(zhàn)

Intel將與日本合作開發(fā)“萬(wàn)級(jí)”量子計(jì)算機(jī),!2030年代初問(wèn)世 大幅提升運(yùn)算能力
泰國(guó)總理身穿羽絨服抵達(dá)哈爾濱 展現(xiàn)清新少女感

特朗普用打高爾夫類比客機(jī)和軍機(jī)相撞 高夫爾球在半空中都不會(huì)互撞,!

詹姆斯狂轟42分17板8助 湖人賽季三殺勇士
相關(guān)新聞
我國(guó)找礦又有重大突破 鋰等戰(zhàn)略性礦產(chǎn)資源大增
2025-01-18 08:58:22我國(guó)找礦又有重大突破實(shí)測(cè)DeepSeek做奧數(shù)題寫作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測(cè)DeepSeek做奧數(shù)題寫作文DeepSeek 引發(fā)全球熱議的神秘力量
2025-02-02 11:56:34DeepSeek足壇反腐又有新進(jìn)展 又有兩人獲刑,!
2024-08-20 15:19:13足壇反腐又有新進(jìn)展DeepSeek徹底爆發(fā) 性能卓越成本低
2025-01-26 15:56:02DeepSeek徹底爆發(fā)三六零:公司未向 DeepSeek 提供服務(wù)
2025-02-05 22:21:52三六零