起底讓硅谷難安的DeepSeek 引發(fā)全球AI界風(fēng)暴(2)

艾倫人工智能研究所的研究科學(xué)家 Nathan Lambert 認(rèn)為,R1 的發(fā)布標(biāo)志著推理模型研究的一個(gè)重要轉(zhuǎn)折點(diǎn),。在此之前,,推理模型一直是工業(yè)研究的重要領(lǐng)域,但缺乏一篇開創(chuàng)性的論文,。Lambert 指出,,推理研究和進(jìn)展現(xiàn)在已經(jīng)鎖定,預(yù)計(jì) 2025 年將有巨大的進(jìn)展,,而且更多將是公開的,。
DeepSeek-R1 通過僅使用強(qiáng)化學(xué)習(xí)(RL)和無監(jiān)督微調(diào)(SFT),,展示了大模型也可以具備強(qiáng)大的推理能力。Hyperbolic 聯(lián)合創(chuàng)始人兼 CTO Yuchen Jin 將這一突破與 AlphaGo 進(jìn)行類比,,認(rèn)為 2025 年可能會(huì)成為 RL 的元年,。然而,R1-Zero 在可用性方面存在一些小問題,,表明訓(xùn)練出色的推理模型需要的不僅僅是大規(guī)模的 RL,。
在 R1-Zero 的基礎(chǔ)上,團(tuán)隊(duì)采用了一個(gè)四階段的訓(xùn)練方案,,包括對(duì)合成推理數(shù)據(jù)進(jìn)行監(jiān)督微調(diào),、大規(guī)模強(qiáng)化學(xué)習(xí)訓(xùn)練、拒絕采樣以及混合推理問題和一般偏好調(diào)整的強(qiáng)化學(xué)習(xí)訓(xùn)練,。這個(gè)過程不僅高效,,還保持了模型的可讀性和最終性能。DeepSeek 通過創(chuàng)新方法,,在有限計(jì)算資源下實(shí)現(xiàn)了這些突破,。微軟 AI 前沿研究實(shí)驗(yàn)室首席研究員 Dimitris Papailiopoulos 表示,R1 最令人驚訝的是其工程簡單性,,追求準(zhǔn)確答案而非詳細(xì)邏輯步驟顯著減少了計(jì)算時(shí)間,同時(shí)保持高效率,。
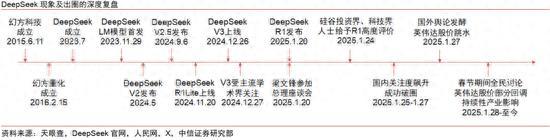
盡管備受關(guān)注,,DeepSeek仍然相對(duì)神秘。公司成立于2023年7月,,創(chuàng)始人梁文鋒畢業(yè)于浙江大學(xué)信息與電子工程專業(yè),,此前創(chuàng)立了管理約80億美元資產(chǎn)的對(duì)沖基金幻方量化。他的目標(biāo)是構(gòu)建通用人工智能(AGI),。在美國實(shí)施芯片出口管制之前,,梁文鋒就收購了大量英偉達(dá)A100芯片,為公司的技術(shù)突破奠定了基礎(chǔ),。
面對(duì)芯片限制,,DeepSeek 將挑戰(zhàn)轉(zhuǎn)化為創(chuàng)新機(jī)遇。前 DeepSeek 員工 Zihan Wang 表示,,在公司工作期間能夠獲得充足的計(jì)算資源并自由實(shí)驗(yàn),。這種創(chuàng)新精神體現(xiàn)在效率提升上。梁文鋒承認(rèn)中國公司在 AI 工程技術(shù)方面相對(duì)落后,,必須消耗兩倍的計(jì)算力才能達(dá)到相同結(jié)果,。但團(tuán)隊(duì)最終找到了減少內(nèi)存使用和加快計(jì)算速度的方法,沒有明顯犧牲準(zhǔn)確性,。
Deepseek帶來的中國資產(chǎn)重估能走多遠(yuǎn) AI平權(quán)改變?nèi)蚋窬?/a>

媒體:中國動(dòng)畫展現(xiàn)文化自信 《哪吒2》全球熱映
18歲抗癌博主去世:愿天堂沒有病痛
18歲抗癌博主去世:愿天堂沒有病痛

尹錫悅被彈劾或板上釘釘 政壇風(fēng)云再起

歐洲的安全,,還是美國的利益,?美俄談判前夕,歐洲被邊緣化引發(fā)擔(dān)憂

為了增加軍費(fèi),,英國公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計(jì)劃陷入僵局
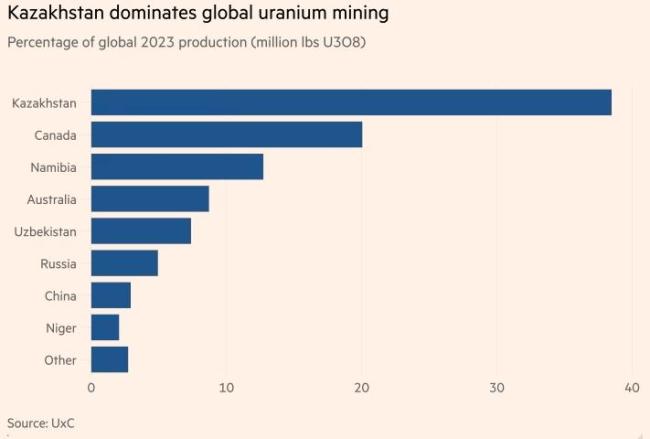
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了

伊朗:反對(duì)外國勢力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

美國頂尖高校宣布暫停招聘 財(cái)政壓力下的斷臂求生

美國翻臉后,,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)

澤連斯基將到訪沙特 不參與美俄會(huì)談

多名官員被解雇后起訴美政府 裁員爭議升級(jí)

央視直播乒乓球亞洲杯2月19日至23日賽程 國乒12人出戰(zhàn)力爭雙冠

被穎兒在《六姊妹》里的何家藝圈粉啦,!穎兒新劇不是戀愛腦是搞錢腦

“東數(shù)西算”發(fā)揮了怎樣的關(guān)鍵作用 助力影視渲染革新

內(nèi)塔尼亞胡:特朗普“接管加沙”計(jì)劃并不令人意外 事先已知并討論過
謝霆鋒演唱會(huì)門票被黃牛炒至17萬 一票難求引發(fā)熱議
媒體:中國動(dòng)畫展現(xiàn)文化自信 《哪吒2》全球熱映

臺(tái)北市議員:特朗普想要臺(tái)積電的命 擔(dān)憂核心技術(shù)外流
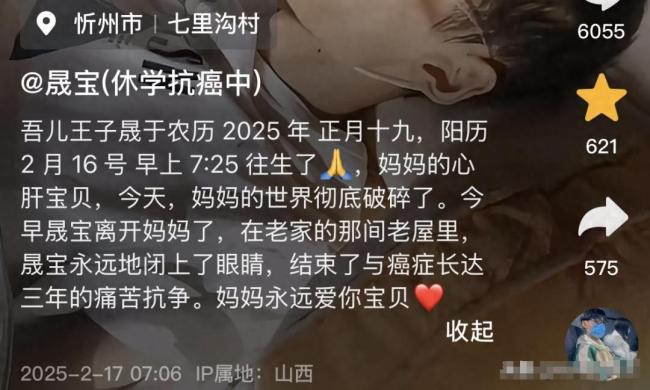
18歲抗癌博主晟寶去世 三年抗?fàn)幗K落幕
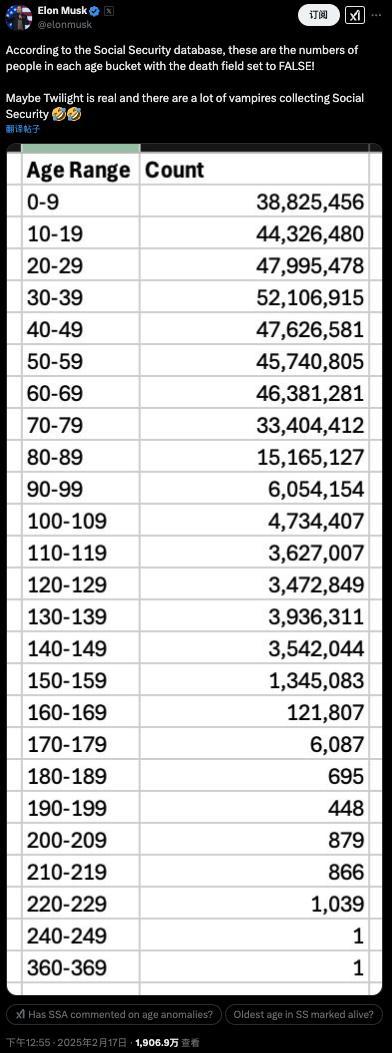
馬斯克查賬“美國社保”,,稱發(fā)現(xiàn)360歲老人,?

馬斯克發(fā)布智能搜索引擎 開啟全民智能問答新時(shí)代

小車溜車小伙飛奔幫忙拽車 網(wǎng)友:這一幕真的很帥
Deepseek帶來的中國資產(chǎn)重估能走多遠(yuǎn) AI平權(quán)改變?nèi)蚋窬?/a>

愛德華茲:我是文班亞馬的忠實(shí)粉絲 NBA新門面閃耀全明星

俄代表:歐盟英國“完全不守信用” 質(zhì)疑其未來協(xié)議參與資格

美國新版“空軍一號(hào)”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度

日本侵華照片讓馬庫斯震驚氣憤 家族見證歷史傷痛

12.4億美元買“酒”!巴菲特,,釋放了什么信號(hào),? 加碼消費(fèi)股布局
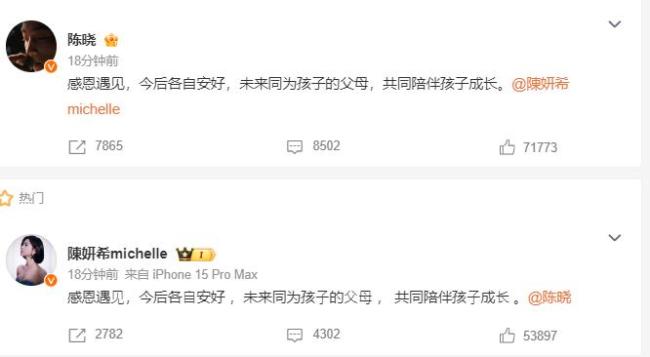
陳曉陳妍希頭紗吻已成過去 九年婚姻終落幕

特朗普批波音總統(tǒng)專機(jī)還沒造好 項(xiàng)目拖延引不滿

直播間賣仿品11名被告人受懲 售假產(chǎn)業(yè)鏈曝光

陳曉陳妍希上次同框已是近2年前 官宣離婚引發(fā)關(guān)注

血液病學(xué)專家吳謹(jǐn)緒教授離世 醫(yī)界巨星隕落
相關(guān)新聞
DeepSeek大模型強(qiáng)在哪 引發(fā)硅谷恐慌
短短一個(gè)月內(nèi),中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-27 08:21:32DeepSeek大模型強(qiáng)在哪DeepSeek美股泡沫得以延續(xù) 挑戰(zhàn)硅谷霸權(quán)
2025-02-04 19:33:47DeepSeek美股泡沫得以延續(xù)媒體揭秘國產(chǎn)大模型DeepSeek 硅谷震撼變革
中國國產(chǎn)大模型Deepseek在硅谷引起了轟動(dòng),。從斯坦福到麻省理工,Deepseek R1幾乎一夜之間成為美國頂尖大學(xué)研究人員的首選模型
2025-01-27 15:33:19媒體揭秘國產(chǎn)大模型DeepSeekDeepSeek如何“震驚”硅谷 性能成本震撼巨頭
2025-01-27 10:28:18DeepSeek如何震驚硅谷DeepSeek讓Meta深陷恐慌 中國AI逆襲硅谷
短短一個(gè)月內(nèi),,中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型——DeepSeek-V3和DeepSeek-R1
2025-01-26 10:34:01DeepSeek讓Meta深陷恐慌幻方DeepSeek如何“震驚”硅谷 性價(jià)比與開源的勝利
過去一周,中國的人工智能大模型成為硅谷乃至全球科技界的熱議話題,。引發(fā)這場討論的是中國人工智能初創(chuàng)公司深度求索(DeepSeek)
2025-01-27 10:02:46幻方DeepSeek如何震驚硅谷








