DeepSeek新模型“火”到海外 引發(fā)硅谷恐慌

短短一個月內(nèi),,中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1,。這兩款模型成本低廉,性能與OpenAI相當,,引發(fā)了硅谷的震驚,,甚至導致Meta內(nèi)部出現(xiàn)恐慌情緒,,工程師們開始連夜嘗試復制DeepSeek的成果,。
Scale AI創(chuàng)始人Alexander Wang在接受采訪時表示,DeepSeek在他們的測試中表現(xiàn)最佳,,與中國科技界的快速發(fā)展有關(guān),。他認為,當美國休息時,,中國科技界在以更低的成本,、更快的速度和更強的實力追趕上來。
中國AI的進展引起了國外媒體的廣泛關(guān)注,,被視為對硅谷敲響了警鐘,。尤其在5000億美元的“星際之門”計劃公布之際,DeepSeek以極低的價格建立了一個突破性的AI模型,,且未使用尖端芯片,,這引發(fā)了人們對巨額資本投入有效性的質(zhì)疑。
一名匿名的Meta員工透露,,DeepSeek-V3在基準測試中超越了Llama 4,,讓Meta進入恐慌模式。工程師們正在爭分奪秒地分析DeepSeek的技術(shù),,試圖復制其成果,。管理層也為GenAI研發(fā)部門的巨額投入感到擔憂,因為一個高管的薪資就超過了訓練整個DeepSeek V3的成本,。
去年12月27日,,DeepSeek推出了開源模型DeepSeek-V3,在聊天機器人競技場排名第七,,在開源模型中排名第一,,并且是全球前十中性價比最高的模型。不到一個月后,,DeepSeek正式開源了R1推理模型,,允許所有人在遵循MIT License的情況下蒸餾R1訓練其他模型。1月24日,,DeepSeek-R1在聊天機器人競技場綜合榜單上排名第三,,與頂尖推理模型o1并列。在高難度提示詞,、代碼和數(shù)學等技術(shù)性極強的領(lǐng)域,,DeepSeek-R1表現(xiàn)出色,位列第一,。
著名投資公司A16z的創(chuàng)始人馬克·安德森稱,,Deepseek-R1是他見過最令人印象深刻的突破之一,而且還是開源的,,是一份給世界的禮物,。諾獎得主,、“AI教父”杰弗里·辛頓表示,中國的STEM教育比美國更好,,擁有更多受過良好教育的人才,,為AI的發(fā)展提供了堅實基礎(chǔ)。
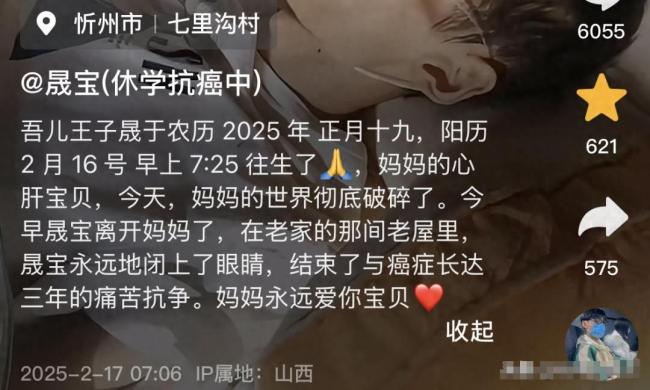
18歲抗癌博主去世:愿天堂沒有病痛

愛德華茲:我是文班亞馬的忠實粉絲 NBA新門面閃耀全明星

央視直播乒乓球亞洲杯2月19日至23日賽程 國乒12人出戰(zhàn)力爭雙冠

野豬頻頻“撒野”遇到了怎么辦 應對策略與法律邊界

12.4億美元買“酒”,!巴菲特,,釋放了什么信號? 加碼消費股布局

被穎兒在《六姊妹》里的何家藝圈粉啦,!穎兒新劇不是戀愛腦是搞錢腦

血液病學專家吳謹緒教授離世 醫(yī)界巨星隕落
央視直播乒乓球亞洲杯2月19日至23日賽程 國乒12人出戰(zhàn)力爭雙冠
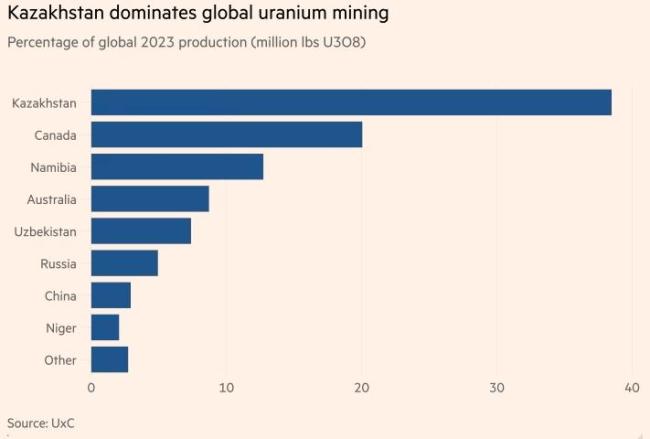
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了
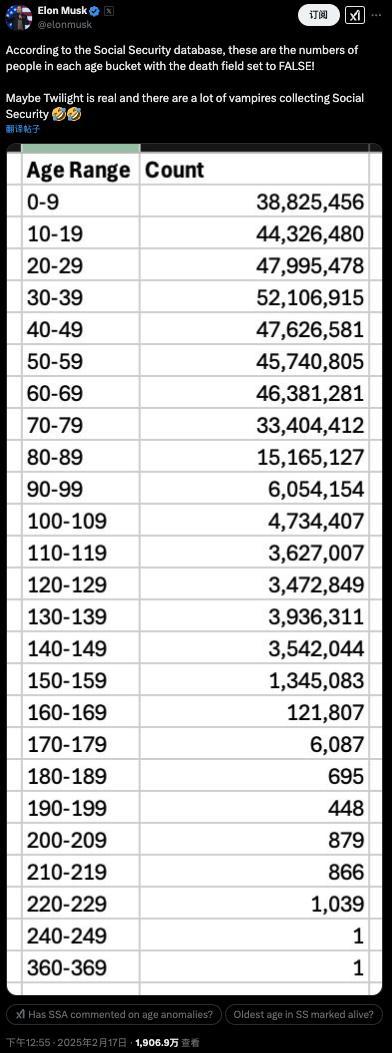
馬斯克查賬“美國社?!保Q發(fā)現(xiàn)360歲老人,?

為了增加軍費,,英國公共服務(wù)部門被曝準備削減11%的預算,歐洲派兵計劃陷入僵局

小車溜車小伙飛奔幫忙拽車 網(wǎng)友:這一幕真的很帥
18歲抗癌博主去世:愿天堂沒有病痛

俄代表:歐盟英國“完全不守信用” 質(zhì)疑其未來協(xié)議參與資格

臺北市議員:特朗普想要臺積電的命 擔憂核心技術(shù)外流

泰22歲女模特疑遭男子強迫吸毒致死 涉事中國顧客試圖私了

歐洲的安全,,還是美國的利益?美俄談判前夕,,歐洲被邊緣化引發(fā)擔憂
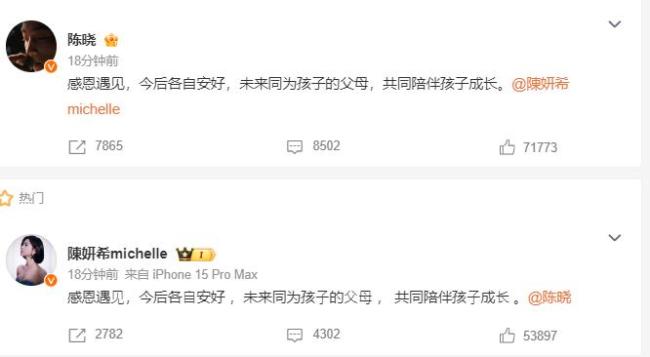
陳曉陳妍希頭紗吻已成過去 九年婚姻終落幕

日本侵華照片讓馬庫斯震驚氣憤 家族見證歷史傷痛

陳曉陳妍希上次同框已是近2年前 官宣離婚引發(fā)關(guān)注

伊朗:反對外國勢力干涉敘利亞 支持敘人民自決權(quán)

美國翻臉后,,歐洲從“夸夸其談的少年”走向獨立成熟要做三件事 應對三大危機

多名官員被解雇后起訴美政府 裁員爭議升級

美國頂尖高校宣布暫停招聘 財政壓力下的斷臂求生

尹錫悅被彈劾或板上釘釘 政壇風云再起

特朗普批波音總統(tǒng)專機還沒造好 項目拖延引不滿

澤連斯基將到訪沙特 不參與美俄會談
謝霆鋒演唱會門票被黃牛炒至17萬 一票難求引發(fā)熱議

馬斯克發(fā)布智能搜索引擎 開啟全民智能問答新時代
愛德華茲:我是文班亞馬的忠實粉絲 NBA新門面閃耀全明星

直播間賣仿品11名被告人受懲 售假產(chǎn)業(yè)鏈曝光
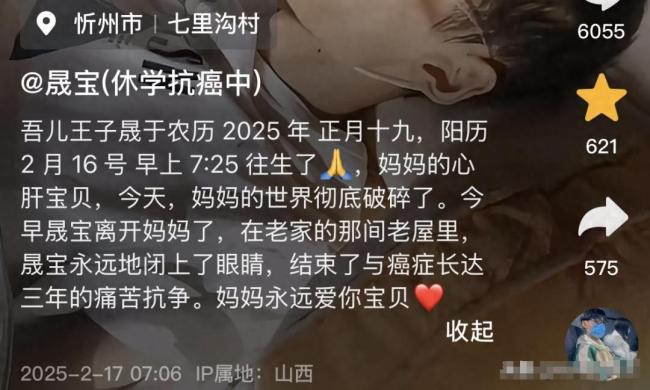
18歲抗癌博主晟寶去世 三年抗爭終落幕

美國新版“空軍一號”再度延期交付 供應鏈問題拖累進度

內(nèi)塔尼亞胡:特朗普“接管加沙”計劃并不令人意外 事先已知并討論過

“東數(shù)西算”發(fā)揮了怎樣的關(guān)鍵作用 助力影視渲染革新
相關(guān)新聞
DeepSeek新模型火到海外 開源大模型正超越閉源
2025-01-27 18:38:01DeepSeek新模型火到海外DeepSeek發(fā)布新模型 Janus-Pro超越DALL-E 3
2025-01-28 09:17:49DeepSeek發(fā)布新模型阿里新模型聲稱超越DeepSeek 展現(xiàn)領(lǐng)先性能
阿里云通義千問超大規(guī)模的MoE模型Qwen2.5-Max于1月29日凌晨正式上線,。該模型是阿里云通義團隊對MoE模型的最新成果,,預訓練數(shù)據(jù)超過20萬億tokens
2025-01-30 13:16:20阿里新模型聲稱超越DeepSeek364元就能開發(fā)DeepSeek模型?假的 AI領(lǐng)域新警鐘
2025-02-08 09:05:58364元就能開發(fā)DeepSeek模型DeepSeek再發(fā)布新模型 Janus-Pro顯著提升多模態(tài)能力
2025-01-29 07:32:49DeepSeek再發(fā)布新模型DeepSeek文生圖新模型優(yōu)于OpenAI 技術(shù)突破引發(fā)關(guān)注
2025-01-29 04:29:50DeepSeek文生圖新模型優(yōu)于OpenAI








