364元就能開發(fā)DeepSeek模型?假的 AI領(lǐng)域新警鐘

364元就能開發(fā)DeepSeek模型,!近日,,一則關(guān)于AI的新聞在全球范圍內(nèi)引起了廣泛關(guān)注。斯坦福大學(xué)和華盛頓大學(xué)的研究人員發(fā)表了一篇論文,,展示了他們以不到50美元(約364元)的云計(jì)算費(fèi)用訓(xùn)練出的一款名為S1的推理模型。該模型在數(shù)學(xué)和編碼能力測(cè)試中表現(xiàn)優(yōu)異,與OpenAI的o1和DeepSeek的R1不相上下,。
然而,這并不意味著AI領(lǐng)域出現(xiàn)了重大突破,。實(shí)際上,,S1模型并不是從零開始訓(xùn)練的,而是基于阿里通義千問Qwen2.5-32B開源模型進(jìn)行開發(fā),,在16塊H100 GPU上進(jìn)行了26分鐘的監(jiān)督微調(diào),,最終形成了新模型S1-32B。此外,,研究人員還通過蒸餾技術(shù)從谷歌的AI推理模型Gemini 2.0中提取了推理能力,。
有大模型廠商的研發(fā)人員指出,S1模型本質(zhì)上是在前人研究的基礎(chǔ)上復(fù)制了推理能力,,并沒有實(shí)現(xiàn)真正的創(chuàng)新,。盡管如此,S1模型的出現(xiàn)還是給頭部大模型廠商帶來了警示,。如果頭部廠商投入大量資源訓(xùn)練出來的模型可以被他人用極少的資源復(fù)制并達(dá)到相似效果,,那么這些廠商的競(jìng)爭(zhēng)優(yōu)勢(shì)將面臨挑戰(zhàn),。

中國(guó)移動(dòng)MWC2025掠影:以東方智慧拓?cái)?shù)智時(shí)代新空間 科技與傳統(tǒng)交織的盛會(huì)

網(wǎng)友稱陳曉眼里又有光了 狀態(tài)回暖驚艷眾人

孩子脊柱側(cè)彎了還以為是體態(tài)不好 家長(zhǎng)需警惕的健康隱患

俄羅斯回應(yīng)日本制裁 對(duì)等反制措施出臺(tái)

研究發(fā)現(xiàn):睡覺側(cè)躺的人,比平躺睡覺的人新陳代謝更好,?促進(jìn)大腦廢物清除

馬奎爾小腿拉傷恐傷缺半個(gè)月 國(guó)家隊(duì)夢(mèng)斷 曼聯(lián)傷病不斷10人缺席 紅魔再遭重創(chuàng)

狀態(tài)不錯(cuò),!庫(kù)里vs黃蜂21 10集錦:頂投三分一箭穿心引客場(chǎng)歡呼 勇士勝黃蜂升西部第六

牛彈琴:特朗普對(duì)歐發(fā)出最輕蔑一問

貝索斯發(fā)火箭把未婚妻送上太空 全女性團(tuán)隊(duì)創(chuàng)舉引發(fā)熱議

白宮稱除非澤連斯基當(dāng)眾道歉否則免談 拒絕道歉推動(dòng)對(duì)話

小米15系列磁吸外接攝像頭解析 重新定義手機(jī)攝影邊界

僅剩8天,彈劾案奏響終曲,,尹錫悅搖搖欲墜 結(jié)局即將揭曉

日民間團(tuán)體要求政府徹查駐日美軍基地,,追責(zé)有機(jī)氟污染問題

克宮回應(yīng)美烏總統(tǒng)爭(zhēng)吵:普京已知悉這一“前所未有的事件” 全球公眾關(guān)注白宮風(fēng)波

大鵬編劇、導(dǎo)演并主演的電影《長(zhǎng)安的荔枝》發(fā)布定檔預(yù)告 豪華陣容引期待
中國(guó)移動(dòng)MWC2025掠影:以東方智慧拓?cái)?shù)智時(shí)代新空間 科技與傳統(tǒng)交織的盛會(huì)

澤連斯基:要換掉我不容易的 所以必須與我談判 美烏關(guān)系面臨考驗(yàn)

臺(tái)積電計(jì)劃在美追加1000億美元投資 擴(kuò)產(chǎn)芯片制造產(chǎn)能 加速全球半導(dǎo)體格局重塑

雷軍回應(yīng)雙Ultra海外首秀 展現(xiàn)湖北創(chuàng)新力
網(wǎng)友稱陳曉眼里又有光了 狀態(tài)回暖驚艷眾人

伊朗總統(tǒng)支持與美對(duì)話遭哈梅內(nèi)伊反對(duì) “那就不談” 最高領(lǐng)袖定方向

電視劇《一本正經(jīng)》有何看點(diǎn) 東北喜劇探案新風(fēng)味

加拿大擬對(duì)美商品征收25%關(guān)稅 反擊措施已備

女子7號(hào)查出懷孕8號(hào)直接就生了 離譜經(jīng)歷引熱議
方大同從沒放棄治療,!新專輯制作人曬聊天記錄稱他去世前一周,仍在接受治療 音樂至生命最后一刻
特朗普澤連斯基矛盾再度升級(jí) 白宮爭(zhēng)吵后局勢(shì)惡化
孩子脊柱側(cè)彎了還以為是體態(tài)不好 家長(zhǎng)需警惕的健康隱患
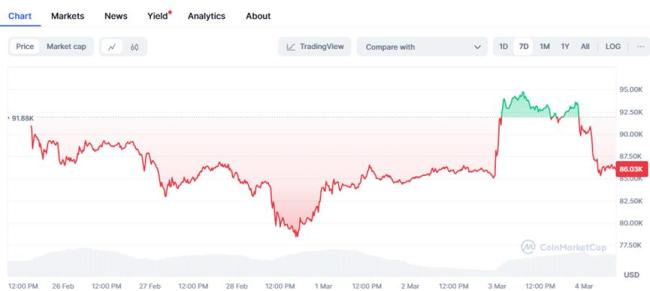
比特幣再跌8%,!特朗普儲(chǔ)備承諾也難抵消市場(chǎng)悲觀情緒 宏觀因素主導(dǎo)下跌

美國(guó)一參議員呼吁澤連斯基辭職 澤連斯基強(qiáng)硬回應(yīng)

特朗普和澤連斯基 誰是真正的“膽小鬼”,? 外交博弈的極限挑戰(zhàn)
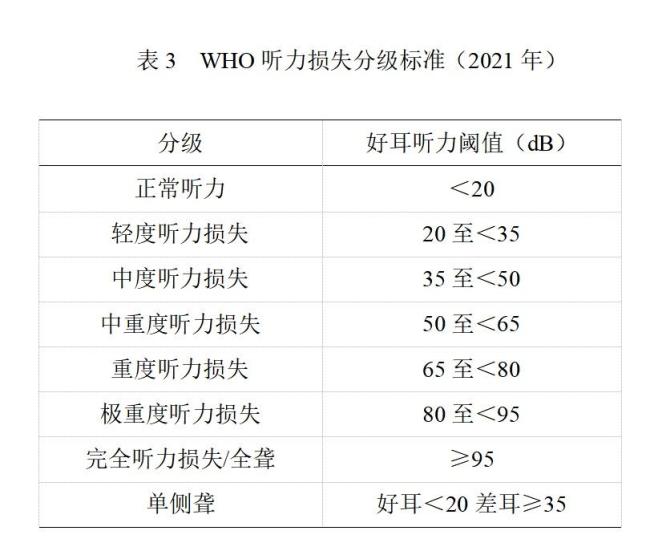
超三成體檢人群面臨聽力損失 耳機(jī)使用需謹(jǐn)慎

美國(guó)欲全面禁止對(duì)華出口AI芯片:英偉達(dá)股價(jià)狂跌 一夜蒸發(fā)1.9萬億元

我國(guó)為未來癌癥治療提供全新策略 揭示細(xì)菌抗腫瘤原理

驚蟄去霉運(yùn) 記得:1不說,吃2樣,,做3事 春回大地萬物新

澤連斯基說烏克蘭需要和平 安全保障是關(guān)鍵
相關(guān)新聞
DeepSeek掀起新浪潮,,多個(gè)模型同日宣布開源!
2025-02-19 11:02:20多個(gè)模型同日宣布開源DeepSeek發(fā)布新模型 Janus-Pro超越DALL-E 3
2025-01-28 09:17:49DeepSeek發(fā)布新模型馬斯克談DeepSeek xAI即將發(fā)布更強(qiáng)模型
2025-02-09 22:13:58馬斯克談DeepSeek高盛:DeepSeek被高估了 低成本模型引發(fā)投資反思
2025-02-06 22:11:05高盛英偉達(dá)回應(yīng)DeepSeek模型 符合出口管制規(guī)定
AI芯片巨頭英偉達(dá)公司發(fā)表聲明,,稱DeepSeek發(fā)布的新模型是一項(xiàng)出色的AI進(jìn)步,,符合美國(guó)技術(shù)出口管制規(guī)定
2025-01-29 05:00:03英偉達(dá)回應(yīng)DeepSeek模型DeepSeek引發(fā)科技股重估 低成本AI模型沖擊市場(chǎng)
2025-01-27 18:32:27DeepSeek引發(fā)科技股重估