DeepSeek推翻兩座大山 低成本訓(xùn)練引發(fā)行業(yè)巨變

DeepSeek的壓力最終傳遞到了黃仁勛身上。英偉達(dá)美股股價(jià)盤前暴跌近11%,,市值縮水超過3500億美元,。資本市場(chǎng)開始懷疑,當(dāng)相對(duì)較少的算力也能實(shí)現(xiàn)與OpenAI相媲美的模型性能時(shí),,高端算力芯片是否正面臨新的泡沫,。

這種擔(dān)憂情緒進(jìn)一步推高了DeepSeek的熱度。短短一周內(nèi),,DeepSeek應(yīng)用在美區(qū)和中國區(qū)App Store免費(fèi)榜上均位列第一,,這是首次有AI助手類產(chǎn)品超越ChatGPT登頂美區(qū)App Store。由于用戶激增,,DeepSeek在兩天內(nèi)接連出現(xiàn)服務(wù)宕機(jī)現(xiàn)象,,官方解釋稱這可能與服務(wù)維護(hù)和請(qǐng)求限制有關(guān)。

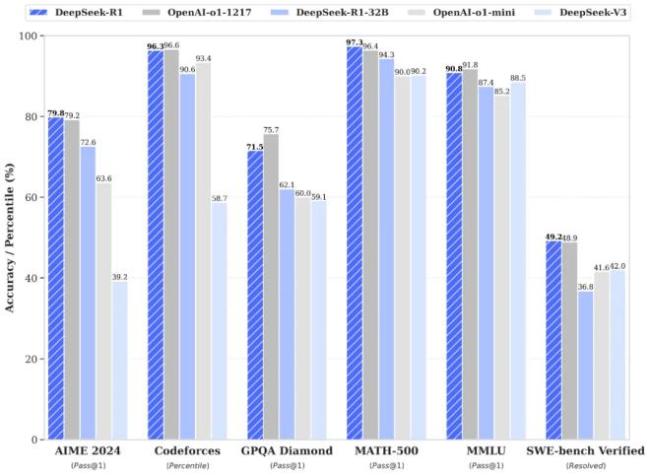
新模型DeepSeek R1是引發(fā)這場(chǎng)全球用戶大討論的直接原因,。R1不僅開源,,還免費(fèi)供全球用戶無限調(diào)用,打破了大廠間的資本比拼游戲,。相比OpenAI在模型上的閉源及付費(fèi)使用限制,,DeepSeek用不到OpenAI十分之一的資源就做出了性能堪比o1的R1。
Meta擔(dān)心即將發(fā)布的Llama 4在性能上可能無法趕上DeepSeek R1,。OpenAI CEO奧特曼也感受到了壓力,,通過發(fā)布首個(gè)智能體Operator搶熱度,并透露即將上線的o3-mini新消息,。
DeepSeek R1在數(shù)學(xué),、代碼、自然語言推理等任務(wù)上的性能可與OpenAI o1模型正式版媲美,。其創(chuàng)新訓(xùn)練方法如R1-Zero路線,直接將強(qiáng)化學(xué)習(xí)應(yīng)用于基礎(chǔ)模型,,無需依賴監(jiān)督微調(diào)和已標(biāo)注數(shù)據(jù),。這種方法提高了訓(xùn)練效率,減少了對(duì)人工干預(yù)的依賴,。
DeepSeek R1的成本遠(yuǎn)低于同類模型,。去年12月發(fā)布的DeepSeek-V3開源基礎(chǔ)模型,性能對(duì)標(biāo)GPT-4o,,但訓(xùn)練成本僅為約557.6萬美元,。相比之下,GPT-4o模型的訓(xùn)練成本約為1億美元,。DeepSeek R1每百萬輸入tokens的價(jià)格為1~4元人民幣,,每百萬輸出tokens為16元人民幣,,而OpenAI o1的運(yùn)行成本約為其30倍。
DeepSeek R1的成功引發(fā)了廣泛關(guān)注,,包括斯坦福大學(xué)計(jì)算機(jī)科學(xué)系客座教授吳恩達(dá)和微軟董事長兼CEO薩提亞·納德拉在內(nèi)的多位大佬都對(duì)其表示關(guān)注,。DeepSeek團(tuán)隊(duì)主要由年輕人才組成,專注于模型研究而不考慮商業(yè)變現(xiàn),。公司選擇了一條理想主義路徑,,只做基礎(chǔ)模型研究,不急于商業(yè)化,。
DeepSeek R1已成為開源社區(qū)Hugging Face上下載量最高的大模型之一,,下載量超過10萬次。Meta AI首席科學(xué)家楊立昆認(rèn)為,,這證明開源模型正在超越專有模型,。DeepSeek未來計(jì)劃繼續(xù)開源旗艦?zāi)P停苿?dòng)開源生態(tài)發(fā)展,。
DeepSeek的成功讓一些初創(chuàng)公司轉(zhuǎn)向其API,,因?yàn)槠鋬r(jià)格更具吸引力。字節(jié)跳動(dòng),、阿里通義以及智譜,、Kimi等團(tuán)隊(duì)也在積極研究DeepSeek。雷軍甚至挖來了DeepSeek的關(guān)鍵開發(fā)者羅福莉,,以增強(qiáng)小米的大模型團(tuán)隊(duì),。國內(nèi)大模型公司面臨壓力,如果不能快速跟進(jìn)R1級(jí)別的模型效果,,客戶可能會(huì)流失,。
分析師:A股無DeepSeek直接相關(guān)標(biāo)的 概念股表現(xiàn)分化

《出走的決心》原型蘇敏離婚 38年終獲自由

李云霄鄭業(yè)成戲腔合唱白蛇傳 傳統(tǒng)與現(xiàn)代的完美交融

伊能靜為婆婆慶祝生日 溫馨家庭情
特朗普總統(tǒng)又反悔了?但這次是好事,,中美貿(mào)易戰(zhàn)2.0可能不打了 金融市場(chǎng)迎來利好

戴偉浚:我沒事很快復(fù)出,,積極康復(fù)中

民進(jìn)黨為何不遺余力地推進(jìn)大罷免 手段卑劣引發(fā)爭(zhēng)議
比特幣和黃金又將重回歷史新高,誰才是有力的戰(zhàn)略儲(chǔ)備,? 美元走弱與政策推動(dòng)共助漲勢(shì)

好惡心,!寧波知名商場(chǎng)被集體吐槽! 地下車庫臟亂差引發(fā)熱議
媒體評(píng)柜姐說劉亦菲微胖被辭退 職業(yè)操守引爭(zhēng)議

專家談歐盟計(jì)劃在格陵蘭島駐軍 地緣政治新焦點(diǎn)
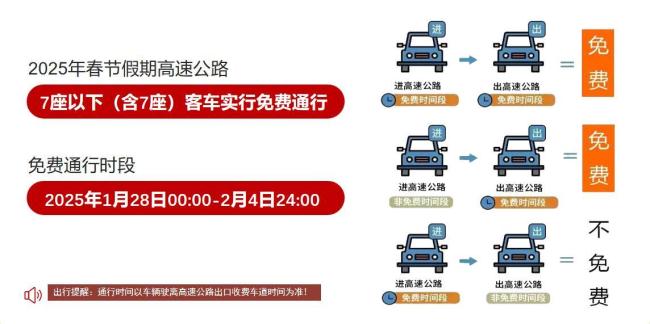
2025年浙江省高速公路春節(jié)出行服務(wù)指南來了,!跨區(qū)域長途出行創(chuàng)歷史新高

美印第安納州總檢察長起訴當(dāng)?shù)鼐L 拒配合移民執(zhí)法

南天湖的雪火爆全網(wǎng) 網(wǎng)友稱其為玩雪天花板

俄稱在烏陣地發(fā)現(xiàn)幾具被鎖士兵遺體 有遭受酷刑痕跡

扎克伯格:AI方面我們需要政府幫助 探討科技未來與競(jìng)爭(zhēng)態(tài)勢(shì)

業(yè)內(nèi):車企海外建廠并非唯一答案 多元化出海模式探索

跟著電影游內(nèi)蒙古正藍(lán)旗 探索草原與文化之美

上城士楊冪開年封面 春意盎然展新姿

菲律賓在南海能掀得起浪嗎 小人使壞徒勞無功

高速公路出滬客流量已回落 春運(yùn)出行高峰平穩(wěn)度過

實(shí)戰(zhàn)畫面揭示2000磅炸彈真實(shí)威力 十層高樓4秒鐘化為廢墟
《出走的決心》原型蘇敏離婚 38年終獲自由

學(xué)者:魯比奧把火燒向澤連斯基,,暫時(shí)凍結(jié)對(duì)烏克蘭的援助
李云霄鄭業(yè)成戲腔合唱白蛇傳 傳統(tǒng)與現(xiàn)代的完美交融
分析師:A股無DeepSeek直接相關(guān)標(biāo)的 概念股表現(xiàn)分化

專家談烏軍失守大諾沃西爾卡 俄軍三面包圍成功

馬斯克的政府效率部誕生一周干了啥 首周削減4.2億美元預(yù)算

遼籃現(xiàn)身遼視春晚 4連冠承諾擲地有聲

尹錫悅會(huì)被判處死刑嗎 涉嫌“內(nèi)亂頭目”罪名成立?

《異人之下2》豆瓣開分8.2分 口碑與熱度雙豐收

專家:2025年行情拉開序幕 政策延續(xù)提振市場(chǎng)信心

第9艘055大驅(qū)將首航 解放軍海軍東海南海實(shí)戰(zhàn)演訓(xùn) 強(qiáng)化臨戰(zhàn)演練

美國無人機(jī)為啥這么貴 高昂成本引發(fā)質(zhì)疑

特朗普的“星際之門”計(jì)劃會(huì)失敗嗎 馬斯克公開質(zhì)疑
相關(guān)新聞
黃金頭頂?shù)膬勺笊?美元國債雙壓金價(jià)
2024-12-30 21:41:02黃金頭頂?shù)膬勺笊?/span>實(shí)測(cè)DeepSeek做奧數(shù)題寫作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測(cè)DeepSeek做奧數(shù)題寫作文DeepSeek徹底爆發(fā) 性能卓越成本低
2025-01-26 15:56:02DeepSeek徹底爆發(fā)DeepSeek核心成員是應(yīng)屆生 小團(tuán)隊(duì)大成就
2025-01-27 19:06:08DeepSeek核心成員是應(yīng)屆生DeepSeek又有重大突破 開源大模型性能卓越
2025-01-21 22:05:22DeepSeek又有重大突破DeepSeek大模型強(qiáng)在哪 引發(fā)硅谷恐慌
短短一個(gè)月內(nèi),中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-27 08:21:32DeepSeek大模型強(qiáng)在哪








