海外輿論如何看DeepSeek 震動(dòng)硅谷引發(fā)熱議

1月27日,,中國(guó)深度求索公司開發(fā)的DeepSeek在蘋果美國(guó)地區(qū)應(yīng)用商店免費(fèi)APP下載排行榜上超越了ChatGPT。最近發(fā)布的開源模型DeepSeek-R1引起了全球范圍內(nèi)的廣泛關(guān)注,。
輿論認(rèn)為,,這一低成本,、開源的人工智能模型震動(dòng)了硅谷,,讓競(jìng)爭(zhēng)對(duì)手感到擔(dān)憂,,也讓科學(xué)家們興奮不已,。多方評(píng)論指出,,中國(guó)AI技術(shù)的快速發(fā)展,,讓美國(guó)的打壓政策顯得尷尬。1月20日,,深度求索發(fā)布了最新開源模型DeepSeek-R1,,此后熱度不斷上升,在國(guó)內(nèi)外引發(fā)了廣泛討論,。頂級(jí)風(fēng)投A16Z創(chuàng)始人馬克·安德森評(píng)價(jià)稱,,DeepSeek-R1是他見過的最驚人,、最令人印象深刻的突破之一,并稱贊其為給世界的一份意義深遠(yuǎn)的禮物,。
在硅谷,,幾乎每個(gè)人都在談?wù)揇eepSeek。有報(bào)道稱,,硅谷工程師正在瘋狂地分析DeepSeek,,甚至有人將其稱為中國(guó)的“ChatGPT時(shí)刻”。DeepSeek的特點(diǎn)是低成本,、高性能和開源,。該模型的推理計(jì)算效率極高,可以與一些頂尖的AI模型相媲美,,與硅谷前沿發(fā)展保持同步,。
DeepSeek-R1在技術(shù)上實(shí)現(xiàn)了重要突破,用純深度學(xué)習(xí)的方法讓AI自發(fā)涌現(xiàn)出推理能力,,在數(shù)學(xué),、代碼、自然語(yǔ)言推理等任務(wù)上的性能比肩OpenAI的o1模型正式版,。據(jù)DeepSeek介紹,,R1的預(yù)訓(xùn)練費(fèi)用只有557.6萬美元,遠(yuǎn)低于OpenAI GPT-4o模型的訓(xùn)練成本,。
加利福尼亞大學(xué)伯克利分校教授亞歷克斯·迪馬基表示,,DeepSeek的技術(shù)路線揭示了一個(gè)事實(shí):達(dá)到頂尖性能未必需要巨額投入,這對(duì)硅谷的燒錢競(jìng)賽無異于釜底抽薪,。開源也是DeepSeek備受關(guān)注的原因之一,,這意味著其他企業(yè)和研究人員可以共享基礎(chǔ)代碼,構(gòu)建和發(fā)布自己的產(chǎn)品,。
英偉達(dá)資深科學(xué)家吉姆·范稱贊DeepSeek是“非美國(guó)公司踐行OpenAI初心”的典范,,通過開放技術(shù)細(xì)節(jié)和訓(xùn)練方法,為全球研究者賦能,。德國(guó)馬克斯·普朗克光科學(xué)研究所的馬里奧·克倫也認(rèn)為,,DeepSeek-R1的開源性非常出色,,相比之下,,o1和其他模型都是閉源模型“黑匣子”。
被譽(yù)為“深度學(xué)習(xí)三巨頭”之一的法國(guó)計(jì)算機(jī)科學(xué)家楊立昆評(píng)論道,,與其說中國(guó)AI正在追趕美國(guó),,不如說“開源模型正在超越閉源”。
“元”公司首席執(zhí)行官扎克伯格在一檔播客節(jié)目中坦言,,DeepSeek技術(shù)非常先進(jìn),,擔(dān)心這個(gè)開源模型會(huì)被全世界廣泛使用,,影響到美國(guó)科技行業(yè)的領(lǐng)先地位。他表示,,這是一場(chǎng)差距很小的競(jìng)爭(zhēng),。
一些美國(guó)專家也指出,如果最好的開源技術(shù)來自中國(guó),,美國(guó)開發(fā)人員將在這些技術(shù)之上構(gòu)建他們的系統(tǒng),,從長(zhǎng)遠(yuǎn)來看,這可能會(huì)讓中國(guó)成為研發(fā)AI的中心,。近年來,,除了DeepSeek之外,阿里巴巴,、快手,、字節(jié)跳動(dòng)以及騰訊等公司也推出了各自的AI模型。
英國(guó)科技網(wǎng)站“生命科學(xué)”撰稿人本·特納指出,,美國(guó)限制向中企出口先進(jìn)AI計(jì)算芯片,,迫使DeepSeek-R1的研發(fā)者采用更智能、更有效的算法來彌補(bǔ)計(jì)算能力的不足,。據(jù)報(bào)道,,ChatGPT需要一萬臺(tái)英偉達(dá)的圖像處理器處理訓(xùn)練數(shù)據(jù),而DeepSeek僅用2000臺(tái)圖像處理器就取得了類似結(jié)果,。
在華盛頓州工作的技術(shù)專家阿爾文·王·格雷林認(rèn)為,,DeepSeek的進(jìn)展顯示出美國(guó)的領(lǐng)先優(yōu)勢(shì)正在縮小,各國(guó)應(yīng)該采取合作方式建設(shè)先進(jìn)AI,,而不是進(jìn)行“軍備競(jìng)賽”,。盡管DeepSeek勢(shì)頭驚人,但其技術(shù)目前仍落后于OpenAI和谷歌,,未來可能將面臨更多的壓力和挑戰(zhàn),。

以民眾持續(xù)抗議要求政府維持停火 呼吁釋放被扣押人員

申公豹的結(jié)巴能矯正嗎 口吃并非無法改善

賴志光任廣東惠州公安局局長(zhǎng) 新任副市長(zhǎng)兼公安局長(zhǎng)

滬指半日漲0.29% 四大行再創(chuàng)新高 銀行股逆勢(shì)走強(qiáng)

美國(guó)翻臉后,,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)

章昊直播時(shí)模仿徐冬冬姿勢(shì)

美客機(jī)翻覆現(xiàn)場(chǎng)視頻曝光 惡劣天氣或成事故主因

美方:烏克蘭能“上桌”談判 歐洲被排除引發(fā)爭(zhēng)議

曾被雷軍千萬年薪挖角!親屬稱羅福莉與丈夫研究領(lǐng)域相同

卡塞米羅:必須繼續(xù)欣賞C羅或者梅西和內(nèi)馬爾 他們?cè)诹硪粋€(gè)世界 足球傳奇永不落幕
安徽一車墜河4人遇難 事故仍在調(diào)查處理中

伊朗:反對(duì)外國(guó)勢(shì)力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)
申公豹的結(jié)巴能矯正嗎 口吃并非無法改善

美為何提議從中國(guó)向?yàn)跖汕簿S和人員 美國(guó)的奇葩主意

宇樹科技創(chuàng)始人王興興曾差點(diǎn)沒考上高中 從內(nèi)向少年到科技領(lǐng)軍人物
以民眾持續(xù)抗議要求政府維持?;?呼吁釋放被扣押人員

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈

波蘭外長(zhǎng):在黃油和槍炮間很難選擇 歐洲需加強(qiáng)國(guó)防開支

外媒:以色列內(nèi)閣投票確認(rèn)扎米爾為下任以軍總參謀長(zhǎng) 即將于3月5日就職

澤連斯基將到訪沙特 不參與美俄會(huì)談

22日起哪吒2港澳地區(qū)全面上映 兩地首映儀式相繼舉行
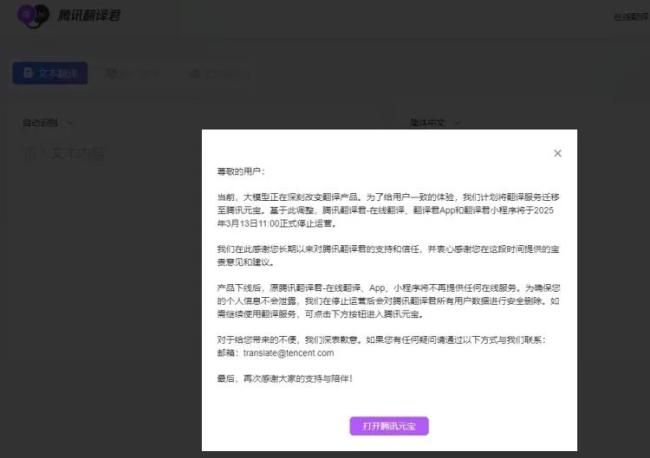
突然宣布:騰訊一產(chǎn)品即將停止運(yùn)營(yíng) 服務(wù)遷移至騰訊元寶
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭(zhēng)議

特朗普批波音:總統(tǒng)專機(jī)怎么還沒造好 項(xiàng)目拖延引不滿
18歲男孩非法穿越鰲太線獲救 救援行動(dòng)再啟

合作導(dǎo)演稱餃子上下班照常騎自行車 低調(diào)健康生活典范

陳曉陳妍希將共同撫養(yǎng)孩子 和平分手引熱議
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大
賴志光任廣東惠州公安局局長(zhǎng) 新任副市長(zhǎng)兼公安局長(zhǎng)

特朗普批波音總統(tǒng)專機(jī)還沒造好 項(xiàng)目拖延引不滿

暴雪《守望先鋒》國(guó)服明日回歸!中國(guó)主題四大天王皮膚來了 國(guó)服專屬福利揭曉
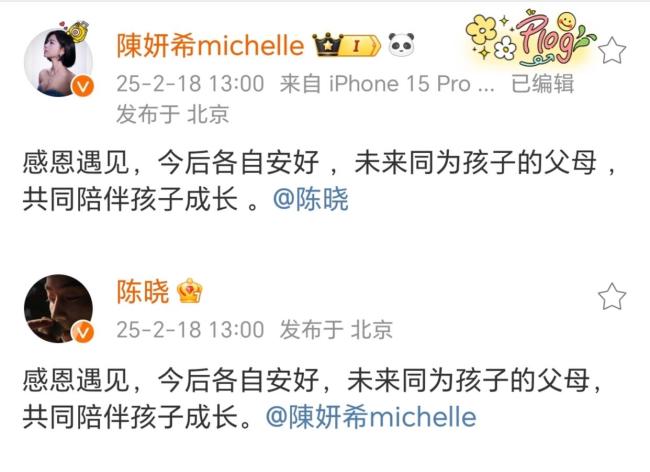
陳曉陳妍希 今后各自安好 感恩遇見共伴成長(zhǎng)

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題
媒體批特朗普又一次“搶劫”臺(tái)灣 美國(guó)的真實(shí)意圖暴露

網(wǎng)曝河北邢臺(tái)一局長(zhǎng)酒后砸店傷人 當(dāng)?shù)丶o(jì)委介入調(diào)查
相關(guān)新聞
DeepSeek成精 輿論永動(dòng)機(jī)的雙面收割
2025-02-01 12:03:21DeepSeek成精DeepSeek新模型“火”到海外 引發(fā)硅谷恐慌
短短一個(gè)月內(nèi),,中國(guó)AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-26 15:51:02DeepSeek新模型火到海外DeepSeek創(chuàng)始人17歲上浙大 國(guó)產(chǎn)AI崛起震撼海外
2025-01-28 09:41:03DeepSeek創(chuàng)始人17歲上浙大DeepSeek遭受海外攻擊未來或?qū)⒊掷m(xù) 網(wǎng)絡(luò)惡意行為升級(jí)
2025-01-30 10:27:25DeepSeek遭受海外攻擊未來或?qū)⒊掷m(xù)DeepSeek新模型火到海外 開源大模型正超越閉源
2025-01-27 18:38:01DeepSeek新模型火到海外專家分析,,DeepSeek遭受海外攻擊未來將持續(xù) 網(wǎng)絡(luò)惡意攻擊不斷升級(jí)
2025-01-31 09:38:08專家分析