華爾街研究:DeepSeek是AI末日嗎 市場恐慌被指過度

春節(jié)期間,DeepSeek新一代開源模型以低成本和高性能引發(fā)熱議,,在全球投資界引起廣泛關(guān)注,。市場上甚至有說法稱DeepSeek僅用500萬美元就復(fù)制了OpenAI,認為這將給整個AI基礎(chǔ)設(shè)施產(chǎn)業(yè)帶來重大影響,。
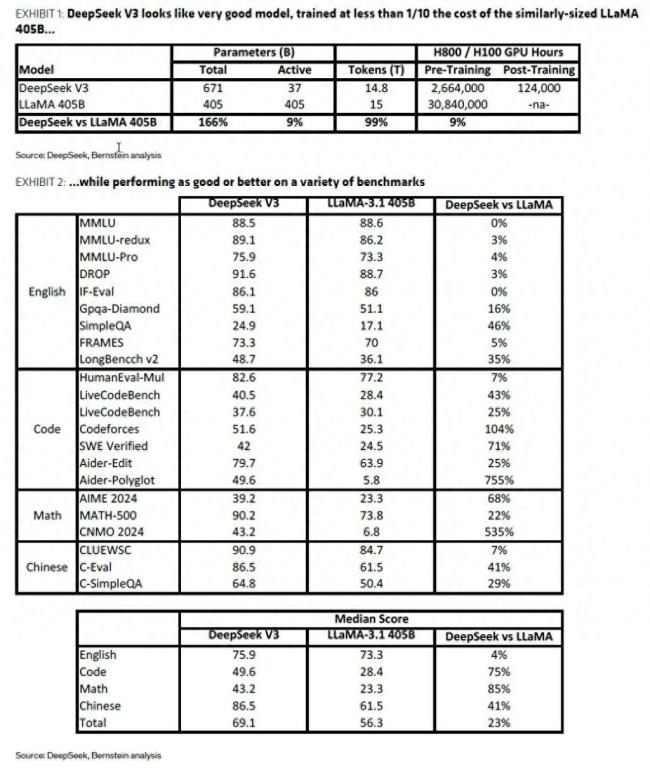
對此,,華爾街知名投行伯恩斯坦在詳細研究DeepSeek的技術(shù)文檔后發(fā)布報告稱,這種市場恐慌情緒明顯過度,?!?00萬美元復(fù)制OpenAI”的說法是市場誤讀。實際上,,這500萬美元僅僅是基于每GPU小時2美元的租賃價格估算的V3模型訓(xùn)練成本,,并未包括前期研發(fā)投入、數(shù)據(jù)成本以及其他相關(guān)費用,。
伯恩斯坦認為,,雖然DeepSeek的效率提升顯著,但從技術(shù)角度看并非奇跡,。即便DeepSeek確實實現(xiàn)了10倍的效率提升,,這也僅相當(dāng)于當(dāng)前AI模型每年的成本增長幅度。目前AI計算需求遠未觸及天花板,,新增算力很可能會被不斷增長的使用需求吸收,,因此對AI板塊保持樂觀。
關(guān)于DeepSeek發(fā)布的兩大模型V3和R1,,伯恩斯坦進行了詳細分析,。V3模型采用專家混合架構(gòu),用2048塊NVIDIA H800 GPU,、約270萬GPU小時達到了可與主流大模型媲美的性能,。V3模型結(jié)合了多頭潛在注意力技術(shù)和FP8混合精度訓(xùn)練,使得其在訓(xùn)練時僅需同等規(guī)模開源模型約9%的算力,,便能達到甚至超越其性能,。例如,V3預(yù)訓(xùn)練僅需約270萬GPU小時,而同樣規(guī)模的開源LLaMA模型則需要約3000萬GPU小時,。
MoE架構(gòu)每次只激活部分參數(shù),,減少計算量;MHLA技術(shù)降低內(nèi)存占用,,提升效率,;FP8混合精度訓(xùn)練在保證性能的同時,進一步提升計算效率,。伯恩斯坦認為,,與業(yè)界3-7倍的常見效率提升相比,V3模型的效率提升并非顛覆性突破,。
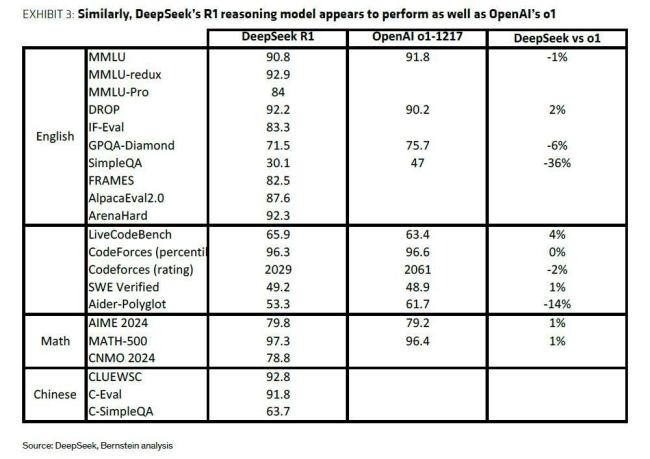
DeepSeek的R1模型通過強化學(xué)習(xí)等創(chuàng)新技術(shù),,顯著提升了推理能力,使其能夠與OpenAI的o1模型相媲美,。此外,,DeepSeek還采用了“模型蒸餾”策略,利用R1模型作為“教師”,,生成數(shù)據(jù)來微調(diào)更小的模型,,這些小模型在性能上可以與OpenAI的o1-mini等競爭模型相媲美。這種策略不僅降低了成本,,也為AI技術(shù)的普及提供了新的思路,。
伯恩斯坦認為,即便DeepSeek確實實現(xiàn)了10倍的效率提升,,這也僅相當(dāng)于當(dāng)前AI模型每年的成本增長幅度,。在“模型規(guī)模定律”不斷推動成本上升的背景下,像MoE,、模型蒸餾,、混合精度計算等創(chuàng)新對AI發(fā)展至關(guān)重要。根據(jù)杰文斯悖論,,效率提升通常會帶來更大的需求,,而非削減開支。該行認為,,目前AI計算需求遠未觸及天花板,,新增算力很可能會被不斷增長的使用需求吸收?;谝陨戏治?,伯恩斯坦對AI板塊保持樂觀。

哥倫比亞總統(tǒng)為何對美態(tài)度很強硬 硬碰硬的較量

各地慶新春活動精彩不斷 傳統(tǒng)文化與現(xiàn)代創(chuàng)意交融
黃曉明包場《射雕英雄傳》 致敬金庸武俠世界

DeepSeek教學(xué)“如何投資A股勝率高” 結(jié)合市場特點與策略
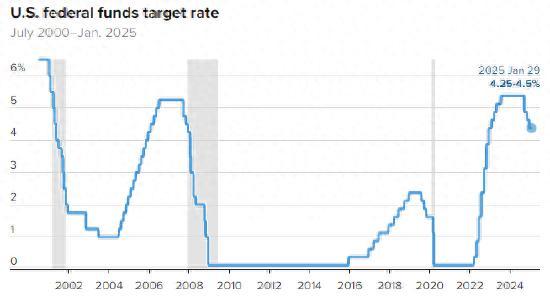
鮑威爾:美聯(lián)儲無需急于降息 維持利率不變符合預(yù)期

阿里新模型聲稱超越DeepSeek 展現(xiàn)領(lǐng)先性能
各地慶新春活動精彩不斷 傳統(tǒng)文化與現(xiàn)代創(chuàng)意交融

中國AI資產(chǎn)的重估時機是否已至 Qwen2.5-Max引領(lǐng)突破
黃曉明包場《射雕英雄傳》 致敬金庸武俠世界
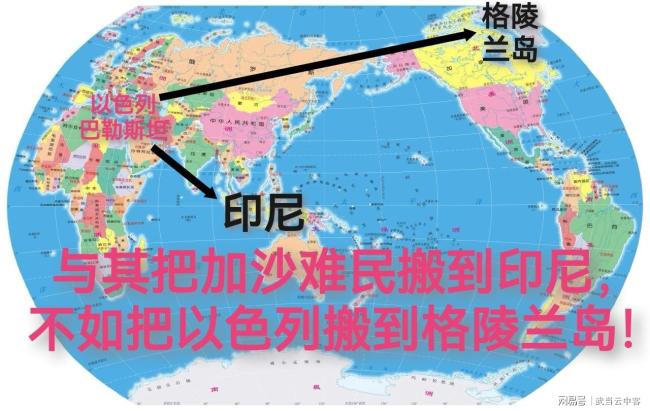
伊朗外長提議把以色列人帶到格陵蘭島 以求中東和平

市民自發(fā)來到欒留偉烈士雕像前祭拜 英年早逝感動眾人

美國正式通知聯(lián)合國退出《巴黎協(xié)定》 退約2026年生效

導(dǎo)演談《哪吒2》做5年背后壓力 五年磨一劍
馬斯克瘋狂質(zhì)疑DeepSeek 挑戰(zhàn)美國AI主導(dǎo)地位,?

英歌舞成網(wǎng)紅?潮汕人的血性有話說 舞臺之下,靈魂何在

專家談低價模型對算力芯片的影響 挑戰(zhàn)傳統(tǒng)主導(dǎo)地位

外國網(wǎng)友學(xué)做中國菜有模有樣 創(chuàng)意烹飪樂翻天
DeepSeek實力受外媒認可 震驚硅谷引發(fā)熱議

機器人穿花棉襖在春晚扭秧歌 科技與傳統(tǒng)的創(chuàng)意融合

斯洛伐克總理:我們的敵人是澤連斯基 澤連斯基被批制造能源問題

趙雅芝海南春晚再開唱 優(yōu)雅永不過時

專家解讀海底雷達探測空中目標 中國創(chuàng)新引發(fā)關(guān)注

庾澄慶恩利父子拜年視頻 溫馨互動羨煞旁人

DeepSeek真讓海外科技股陷入困境了嗎 市場動蕩引擔(dān)憂

特朗普上任后2次要求美聯(lián)儲降息被拒 權(quán)力受限現(xiàn)實打臉

亮相總臺春晚的英歌舞竟與蛇有關(guān) 舞動新春活力

高鐵一公里耗一萬度電,?假 實際每公里僅21度左右

南部戰(zhàn)區(qū)拜年海報祝大家新春快樂 祥蛇獻瑞迎春到
哥倫比亞總統(tǒng)為何對美態(tài)度很強硬 硬碰硬的較量

DeepSeek遭受海外攻擊未來將持續(xù) 網(wǎng)絡(luò)惡意攻擊升級

扭秧歌的宇樹機器人是怎樣走到今天的 從春晚到全球矚目

向佐標準手勢已入侵全球 北美風(fēng)潮興起

特朗普能在100天內(nèi)解決俄烏問題嗎 談判前景復(fù)雜

大年初一城市票房上海奪冠 春節(jié)檔創(chuàng)紀錄盛況
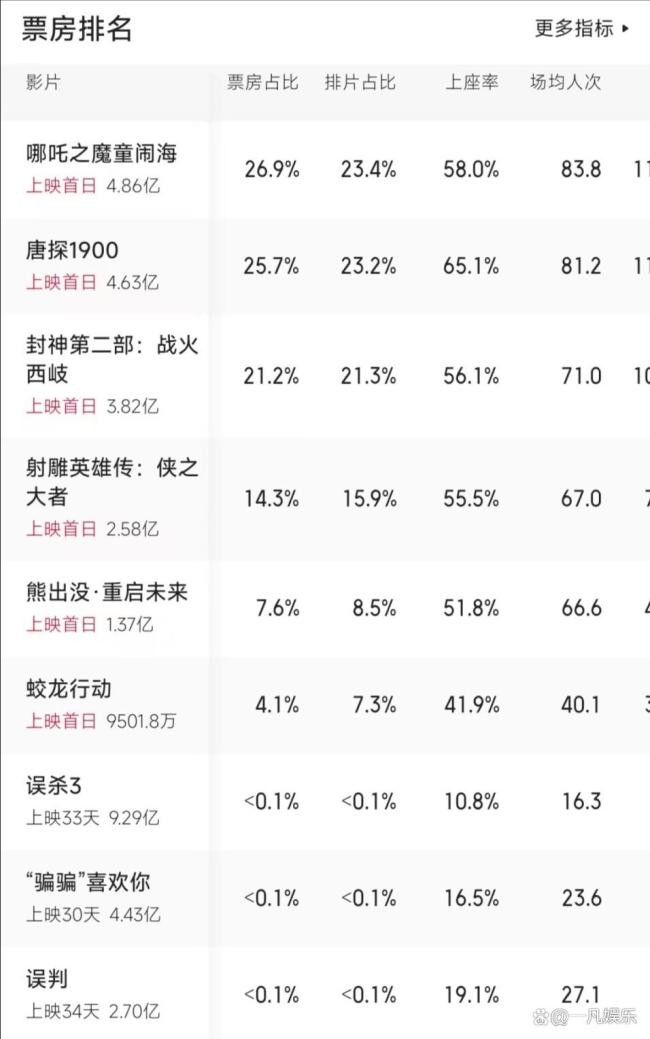
春節(jié)檔票房排名大洗牌:國漫之光強勢領(lǐng)跑,,《蛟龍行動》讓人意外
相關(guān)新聞
實習(xí)生,月薪14w 了 華爾街新寵兒
好消息往往來自別人家公司,。去年年初,,一家名為Jane Street的量化交易機構(gòu)給實習(xí)生開出了1.6萬美元(約合人民幣11萬元)的月薪。那時,,這家公司在華爾街還未聲名鵲起
2024-11-07 09:43:11實習(xí)生月薪14w了華爾街緣何開始上調(diào)美股預(yù)期
2024-11-19 13:42:30華爾街緣何開始上調(diào)美股預(yù)期美元升至兩年高位 華爾街一致看漲
2024-11-13 13:50:53美元升至兩年高位華爾街為美國大選通宵工作 金融市場嚴陣以待
2024-11-05 12:19:00華爾街為美國大選通宵工作華爾街目光鎖定美國大選 市場波動預(yù)期升溫
2024-11-04 10:33:00華爾街目光鎖定美國大選華爾街資金涌入中國資產(chǎn) 外資熱情高漲創(chuàng)紀錄
2024-09-30 15:08:00華爾街資金涌入中國資產(chǎn)