蛇年AI大事記:DeepSeek是否封神 科技黑馬崛起

在龍年結(jié)束、蛇年開始之際,東方上演了一場震撼科技界的事件,。1月27日,,美國的人工智能主題股票遭遇拋售,英偉達(dá)股價(jià)暴跌16.97%,,市值一日內(nèi)蒸發(fā)近6000億美元,創(chuàng)下美國歷史上單日最大市值損失記錄。這一事件的幕后推手是中國一家初創(chuàng)公司DeepSeek開發(fā)的大模型DeepSeek-V3,。該模型發(fā)布后迅速登上美國蘋果App商店免費(fèi)下載排行榜榜首,引發(fā)科技圈和華爾街的關(guān)注,。
1月28日凌晨,,除夕夜前一晚,DeepSeek開源了其多模態(tài)模型Janus-Pro-7B,,并宣布在GenEval和DPG-Bench基準(zhǔn)測試中擊敗了OpenAI的DALL-E 3和Stable Diffusion,。隨后,美國多名官員回應(yīng)稱DeepSeek是“偷竊”,,并表示正在對其影響開展國家安全調(diào)查,。面對外部壓力,360集團(tuán)創(chuàng)始人周鴻祎在微博上表示,,如果DeepSeek需要,,360愿意提供網(wǎng)絡(luò)安全方面的全力支持。這場保衛(wèi)戰(zhàn)已經(jīng)打響,,中國“科技黑馬”掀起的AI風(fēng)暴可能將重塑全球科技業(yè)態(tài),。
軟銀宣布準(zhǔn)備投資5000億美元于AI基礎(chǔ)設(shè)施建設(shè)時(shí),DeepSeek發(fā)布了完全開源的R1模型,。該模型在數(shù)學(xué),、代碼,、自然語言推理等任務(wù)上的性能與OpenAI最新的o1大模型相當(dāng),對全球科技界尤其是美國各大模型構(gòu)成了巨大沖擊,。長期以來,,算力被認(rèn)為是AI的核心,但DeepSeek團(tuán)隊(duì)專注于算法創(chuàng)新,,減少了對計(jì)算資源的需求,。R1通過動態(tài)路由算法壓縮了80%的冗余計(jì)算,以較低成本實(shí)現(xiàn)了高性能,。DeepSeek官方公布的API定價(jià)顯示,,R1每百萬輸入tokens為1元至4元人民幣,每百萬輸出tokens為16元人民幣,,而OpenAI的ChatGPT-o1運(yùn)行成本約為R1的30倍,。
這家成立僅一年半的年輕公司以低成本做出了硅谷需要上億投入才能實(shí)現(xiàn)的大模型,R1迅速成為美國頂尖大學(xué)研究人員的首選,。AMD宣布已將DeepSeek-V3集成到Instinct MI300X GPU上,,優(yōu)化AI推理性能。一名Meta員工透露,,由于DeepSeek的低成本高性能,,他們公司的人工智能部門陷入恐慌。國內(nèi)大廠如阿里云也在春節(jié)期間加班發(fā)布了通義千問旗艦版模型Qwen2.5-Max,,聲稱在多項(xiàng)測試中全面超越GPT-4o,、DeepSeek-V3和Llama-3.1。
盡管DeepSeek在全球范圍內(nèi)引起了轟動,,但實(shí)際體驗(yàn)顯示它在某些方面仍需改進(jìn),。例如,在文生圖創(chuàng)作時(shí),,Janus Pro的表現(xiàn)令人失望,。江蘇省紅樓夢學(xué)會會長苗懷明教授認(rèn)為,DeepSeek可以寫一些較為套路化,、程序化的東西,,但在獨(dú)創(chuàng)性和深度文學(xué)作品創(chuàng)作方面尚有不足。此外,,DeepSeek依然依賴于美國的算力生態(tài),,訓(xùn)練過程中需要使用英偉達(dá)GPU。包括馬斯克在內(nèi)的多位業(yè)內(nèi)人士認(rèn)為,,DeepSeek的訓(xùn)練方式仍然依賴堆積算力,而非真正的突破,。
DeepSeek登頂中美應(yīng)用下載榜后,,因遭受大規(guī)模惡意攻擊短暫關(guān)閉注冊通道,。用戶暴增導(dǎo)致系統(tǒng)頻繁宕機(jī),每問幾個(gè)問題后就需要重新開啟對話窗口,。DeepSeek團(tuán)隊(duì)清醒地認(rèn)識到,,雖然取得了突破,但仍需保持冷靜,,看清差距,。創(chuàng)始人的回復(fù)表明,他們正努力探索可持續(xù)發(fā)展的新路,。

中國男籃與日本男籃比賽前瞻 關(guān)鍵一戰(zhàn)牽動人心

楊丞琳曬婚紗照 低調(diào)婚禮一周年

鄰居直播大衣哥唱歌漲粉三百多萬 大衣哥為躲網(wǎng)暴者爬梯子翻墻見兒子

工人胳膊卷入打孔機(jī) 消防救援 巧用撬棍成功解救
媒體批特朗普又一次“搶劫”臺灣 美國的真實(shí)意圖暴露

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈

美客機(jī)翻覆現(xiàn)場視頻曝光 惡劣天氣或成事故主因

河北邢臺一局長被曝酒后砸店傷人 官方回應(yīng)將調(diào)查核實(shí)

多方祝福喬丹62生日快樂,!艾弗森稱其GOAT:我一直想像你一樣 艾弗森INS深情祝福

大衣哥"被網(wǎng)暴4年:有人敲門要50萬:不堪其擾訴諸法律

美為何提議從中國向?yàn)跖汕簿S和人員 美國的奇葩主意

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題
俄美今日開談?wù)勈裁矗繛楹芜x在沙特,?烏歐又在“焦慮”什么,? 烏克蘭問題成焦點(diǎn)
鄰居直播大衣哥唱歌漲粉三百多萬 大衣哥為躲網(wǎng)暴者爬梯子翻墻見兒子
中國男籃與日本男籃比賽前瞻 關(guān)鍵一戰(zhàn)牽動人心

醫(yī)療主題基金迎戰(zhàn)略機(jī)遇期 AI技術(shù)驅(qū)動增長
陳曉陳妍希官宣離婚 感恩遇見各自安好

人工智能會取代你的工作嗎 職業(yè)未來變數(shù)與應(yīng)對策略
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭議

美方:烏克蘭能“上桌”談判 歐洲被排除引發(fā)爭議

朗普新任期將滿月:政策落地遇阻,全球市場格局生變

美國東部8州遭洪災(zāi)影響上億人,?肯塔基緊急狀態(tài),,真有這么嚴(yán)重嗎 致命風(fēng)暴致8人死亡
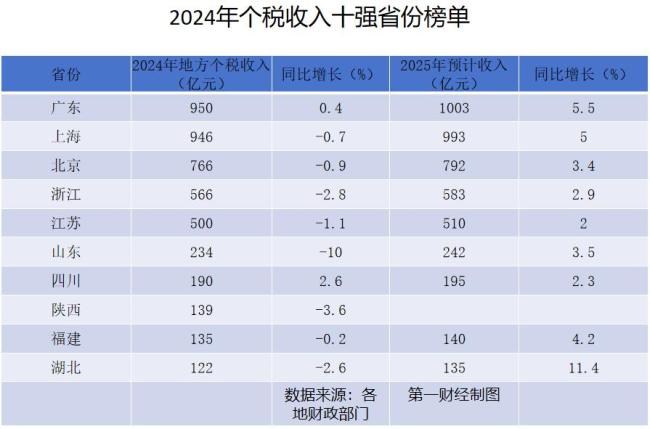
個(gè)稅收入十強(qiáng)省份公布 廣東重奪榜首

外媒:以色列內(nèi)閣投票確認(rèn)扎米爾為下任以軍總參謀長 即將于3月5日就職
下賽季全明星周末或?qū)⒁雴翁糍?巨星積極響應(yīng)

0日將允許戶籍欄登記可填“臺灣” 外交部敦促 恪守一個(gè)中國原則
楊丞琳曬婚紗照 低調(diào)婚禮一周年

宇樹科技創(chuàng)始人王興興曾差點(diǎn)沒考上高中 從內(nèi)向少年到科技領(lǐng)軍人物

曾被雷軍千萬年薪挖角!親屬稱羅福莉與丈夫研究領(lǐng)域相同

1月廈門維修進(jìn)境飛機(jī)增兩成 航空維修產(chǎn)業(yè)迎“開門紅”
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

特朗普批波音:總統(tǒng)專機(jī)怎么還沒造好 項(xiàng)目拖延引不滿

正月二十二是啥節(jié)日,?牢記4大傳統(tǒng),、2個(gè)忌諱 祈福迎好運(yùn)

鹿晗關(guān)注了Sana的ins 粉絲熱議不斷

小S發(fā)徐家三姐妹童年照懷念大S 溫馨回憶引共鳴
相關(guān)新聞
DeepSeek展望蛇年A股 AI熱潮引發(fā)股市新變局
2025-01-29 02:05:24DeepSeek展望蛇年A股蛇年春晚背后的AI高科技 創(chuàng)新視覺體驗(yàn)驚艷全球
2025-01-30 01:18:38蛇年春晚背后的AI高科技2024年中國航天大事記!這些精彩瞬間令人難忘
當(dāng)火箭的尾焰劃破夜空星辰與大海的夢想再次照亮了我們的征途2024年中國航天交出一張張碩果累累的成績單這一年我們見證了太多發(fā)射的震撼瞬間這一年中國航天不斷取得新的突破這一年我們在浩瀚
2024-12-29 09:05:282024年中國航天大事記,!這些精彩瞬間令人難忘胡錫進(jìn):重溫這一年的大事記
2024-12-26 07:33:46胡錫進(jìn):重溫這一年的大事記胡錫進(jìn):重溫了這一年的大事記
2024-12-25 21:16:50胡錫進(jìn)重溫了這一年的大事記正月十八是“天賜發(fā)財(cái)日” 5件大事記得做
2025-02-14 13:25:05正月十八是天賜發(fā)財(cái)日








