Nature連發(fā)三篇文章聚焦DeepSeek 低成本高性能引關(guān)注

最近,,來自中國杭州的初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大語言模型,,在全球科技界引起廣泛關(guān)注,。這兩款模型性能可與美國科技巨頭開發(fā)的主流工具相媲美,,但研發(fā)成本和所需算力卻大大降低,。

2025年1月20日,,DeepSeek發(fā)布了部分開源的“推理”模型DeepSeek-R1,,該模型能夠解決一些科學(xué)問題,,水平接近OpenAI于2024年底發(fā)布的GPT-o1,。幾天后的1月28日,DeepSeek又推出了Janus-Pro-7B,,這是一款根據(jù)文本提示生成圖像的模型,,其性能與OpenAI的DALL-E 3以及Stability AI的Stable Diffusion相當(dāng)。

國際頂尖學(xué)術(shù)期刊Nature在其官網(wǎng)連續(xù)發(fā)布了三篇關(guān)于DeepSeek的文章,。1月29日的文章提到,,科學(xué)家們紛紛涌入DeepSeek,從AI專家到數(shù)學(xué)家再到認(rèn)知神經(jīng)學(xué)家,,他們對DeepSeek-R1的高性能和低成本感到驚嘆,。次日的文章則強(qiáng)調(diào),DeepSeek-R1執(zhí)行推理任務(wù)的水平與OpenAI的GPT o1相當(dāng),,并且向研究人員開源,,相比之下,OpenAI推出的GPT o1及最新成果o3基本上都是黑匣子,。
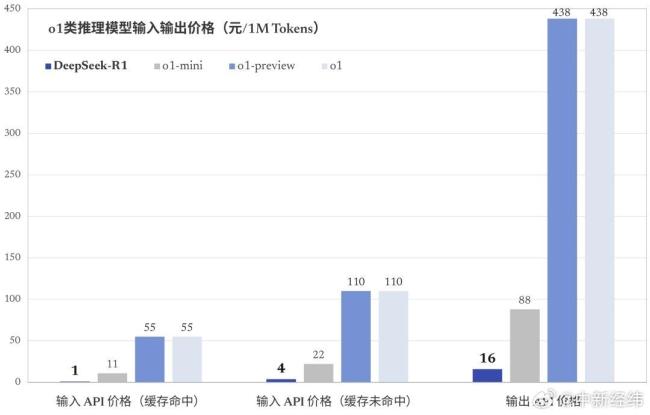
DeepSeek-R1的成本也令人印象深刻,。盡管DeepSeek尚未公布訓(xùn)練DeepSeek-R1的全部成本,但據(jù)估計(jì),,其算力租賃費(fèi)用約為600萬美元,,而Meta公司訓(xùn)練Llama 3.1 405B的算力是其11倍,,訓(xùn)練成本超過6000萬美元。此外,,使用DeepSeek-R1界面的用戶只需支付運(yùn)行ChatGPT o1費(fèi)用的不到三十分之一,。DeepSeek還創(chuàng)建了DeepSeek-R1的迷你“蒸餾”版本,以便算力有限的研究人員也能使用該模型,。
另一篇文章分析了中國如何創(chuàng)造出震驚世界的AI模型DeepSeek,,指出政策支持、大量資金以及眾多AI專業(yè)人才幫助中國企業(yè)建立了先進(jìn)的大語言模型,。國內(nèi)研究人員表示,,這家初創(chuàng)企業(yè)的成功在意料之中,符合政府成為全球人工智能領(lǐng)導(dǎo)者的雄心,。中國科學(xué)院計(jì)算技術(shù)研究所副所長陳云霽研究員指出,,鑒于中國在開發(fā)大語言模型上的巨額投資和大量博士人才,像DeepSeek這樣的公司在中國出現(xiàn)是不可避免的,。
事實(shí)上,,阿里巴巴也在1月29日發(fā)布了迄今為止最先進(jìn)的大語言模型Qwen2.5-Max,稱其性能優(yōu)于GPT-4o,、DeepSeek-V3以及Llama-3.1-405B,。上周,月之暗面聯(lián)合字節(jié)跳動發(fā)布了新的推理模型Kimi 1.5和Kimi 1.5 1.5-pro,,在某些基準(zhǔn)測試中的表現(xiàn)優(yōu)于GPT-o1,。

國產(chǎn)大模型DeepSeek為什么更像人 文化批判與理論隱喻更強(qiáng)

于冬稱給蛟龍行動打一星的都是黑水 呼吁公平評分

萊昂納德:要對比賽保持專注 展現(xiàn)職業(yè)態(tài)度

合肥高架橋現(xiàn)野豬與車并駕 城市快節(jié)奏的意外訪客
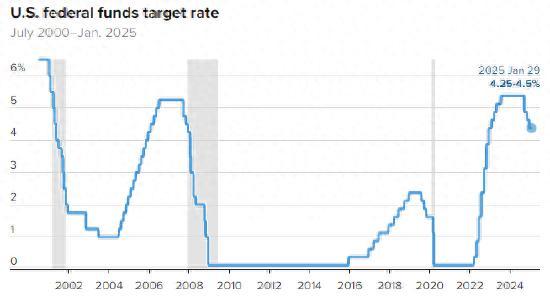
鮑威爾:美聯(lián)儲無需急于降息 維持利率不變符合預(yù)期
華爾街怎么看DeepSeek AI行業(yè)迎來顛覆時(shí)刻
DeepSeek實(shí)力受外媒認(rèn)可 震驚硅谷引發(fā)熱議

斯洛伐克總理:我們的敵人是澤連斯基 澤連斯基被批制造能源問題

索尼蓋了一座“Sony Park”,我在里面發(fā)現(xiàn)了索尼的“精神內(nèi)核” 不務(wù)正業(yè)的精神傳承
DeepSeek團(tuán)隊(duì)都來自國內(nèi)頂尖高校 年輕高潛成亮點(diǎn)

杜潤旺已婚 社媒簡介更新引發(fā)關(guān)注

掘金險(xiǎn)勝76人 約基奇關(guān)鍵球定勝局

機(jī)器人穿花棉襖在春晚扭秧歌 科技與傳統(tǒng)的創(chuàng)意融合

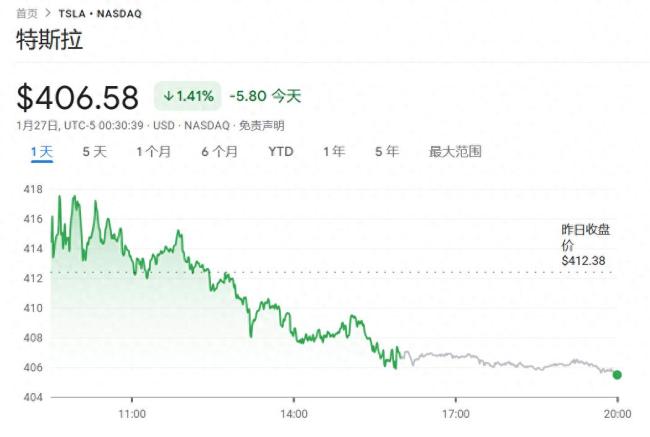
DeepSeek真讓海外科技股陷入困境了嗎 市場動蕩引擔(dān)憂

圣基茨和尼維斯海岸附近發(fā)現(xiàn)19具遺體 空難悲劇震動全球

塔圖姆連續(xù)三分 率隊(duì)逆轉(zhuǎn)取勝

文班亞馬連續(xù)三分 單場30+14+6帽閃耀賽場
于冬稱給蛟龍行動打一星的都是黑水 呼吁公平評分

南部戰(zhàn)區(qū)拜年海報(bào)祝大家新春快樂 祥蛇獻(xiàn)瑞迎春到
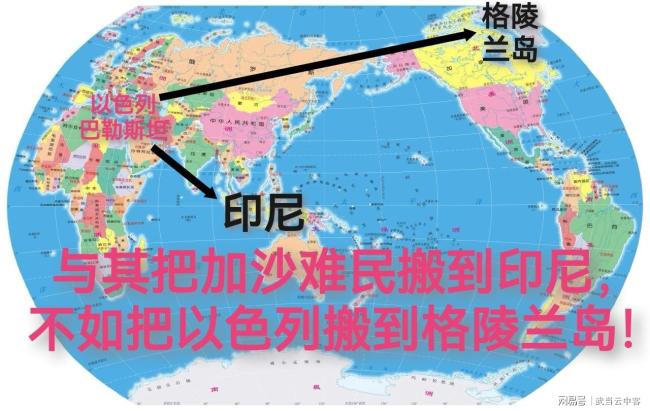
伊朗外長提議把以色列人帶到格陵蘭島 以求中東和平

特朗普能在100天內(nèi)解決俄烏問題嗎 談判前景復(fù)雜

美媒:里根機(jī)場空域擁堵 事故凸顯空域共享難題

美國正式通知聯(lián)合國退出《巴黎協(xié)定》 退約2026年生效
國產(chǎn)大模型DeepSeek為什么更像人 文化批判與理論隱喻更強(qiáng)

DeepSeek教學(xué)“如何投資A股勝率高” 結(jié)合市場特點(diǎn)與策略

文班亞馬30分帶隊(duì)勝雄鹿 馬刺大勝展現(xiàn)實(shí)力

專家談低價(jià)模型對算力芯片的影響 挑戰(zhàn)傳統(tǒng)主導(dǎo)地位

費(fèi)城墜毀飛機(jī)為醫(yī)療用途載有患兒 特朗普感謝救援人員
萊昂納德:要對比賽保持專注 展現(xiàn)職業(yè)態(tài)度

歐文空砍28分6板3助 獨(dú)行俠惜敗活塞

專家解讀海底雷達(dá)探測空中目標(biāo) 中國創(chuàng)新引發(fā)關(guān)注

大年初四北京下雪 氣溫低迷風(fēng)力增強(qiáng)

市民自發(fā)來到欒留偉烈士雕像前祭拜 英年早逝感動眾人

外國網(wǎng)友學(xué)做中國菜有模有樣 創(chuàng)意烹飪樂翻天
把自己氣笑了,!庫里連續(xù)打鐵勇士落后20分 萌神替補(bǔ)席一臉苦笑 庫里創(chuàng)恥辱紀(jì)錄
相關(guān)新聞
Nature:世界科學(xué)家涌向DeepSeek 廉價(jià)強(qiáng)大模型引關(guān)注
2025-01-31 11:45:58Nature實(shí)測DeepSeek做奧數(shù)題寫作文 DeepSeek火爆全球
2025-01-27 20:13:31實(shí)測DeepSeek做奧數(shù)題寫作文DeepSeek徹底爆發(fā) 性能卓越成本低
2025-01-26 15:56:02DeepSeek徹底爆發(fā)中國科學(xué)家當(dāng)選Nature年度十大人物 CAR-T療法突破
2024-12-11 23:05:06中國科學(xué)家當(dāng)選Nature年度十大人物DeepSeek沖擊華爾街 引發(fā)投資界重估
過去一周,,DeepSeek R1,、字節(jié)跳動的豆包1.5 Pro以及月之暗面的Kimi k1.5模型相繼推出,引起了全球投資者的高度關(guān)注
2025-02-01 13:18:44DeepSeek沖擊華爾街OpenAI宣稱DeepSeek違規(guī) 引發(fā)行業(yè)震動
2025-01-30 08:56:02OpenAI宣稱DeepSeek違規(guī)