開(kāi)源DeepSeek如何撼動(dòng)全球AI市場(chǎng) 性能價(jià)格雙突破(2)

DeepSeek選擇了一條與OpenAI截然不同的技術(shù)路線(xiàn),完全摒棄了傳統(tǒng)的監(jiān)督微調(diào)環(huán)節(jié),,依賴(lài)強(qiáng)化學(xué)習(xí)進(jìn)行訓(xùn)練。DeepSeek創(chuàng)始人梁文鋒強(qiáng)調(diào)原創(chuàng)的重要性,,他認(rèn)為只有通過(guò)原創(chuàng)才能擺脫追隨者的地位。OpenAI首席執(zhí)行官山姆·阿爾特曼承認(rèn)DeepSeek是一個(gè)非常好的模型,,并表示將推出更好的模型,。
科技巨頭如微軟、AWS和英偉達(dá)紛紛接入DeepSeek-R1模型服務(wù),。微軟將其添加到Azure AI Foundry,AWS也在其平臺(tái)上部署了DeepSeek-R1,。英偉達(dá)宣布DeepSeek-R1作為NVIDIA NIM微服務(wù)預(yù)覽版發(fā)布,。AMD也宣布DeepSeek-V3模型已集成至AMD Instinct GPU上。
DeepSeek的出現(xiàn)引發(fā)了對(duì)AI未來(lái)發(fā)展的討論,。吳恩達(dá)提醒,,擴(kuò)大規(guī)模并非實(shí)現(xiàn)AI進(jìn)步的唯一途徑,算法創(chuàng)新同樣重要,。隨著訓(xùn)練成本降低和技術(shù)成熟,,大語(yǔ)言模型將愈發(fā)成為一種普通產(chǎn)品。Hugging Face聯(lián)合創(chuàng)始人托馬斯?沃爾夫認(rèn)為,,許多這類(lèi)模型將會(huì)免費(fèi)且可自由獲取,。巧合的是,同日,,OpenAI推出了全新推理模型o3-mini,,并首次向免費(fèi)用戶(hù)開(kāi)放。Sam Altman罕見(jiàn)承認(rèn)OpenAI過(guò)去在開(kāi)源方面站在“歷史錯(cuò)誤的一邊”,,并表示需要想出一個(gè)不同的開(kāi)源策略,。

前馬競(jìng)青訓(xùn)教練:巴里奧斯被罰下是因?yàn)榉稿e(cuò),但我們應(yīng)保護(hù)他 支持年輕模范球員

又被劉曉慶圈粉了,!

記者買(mǎi)7件100%羊絨衫 實(shí)際1根羊絨都沒(méi)有
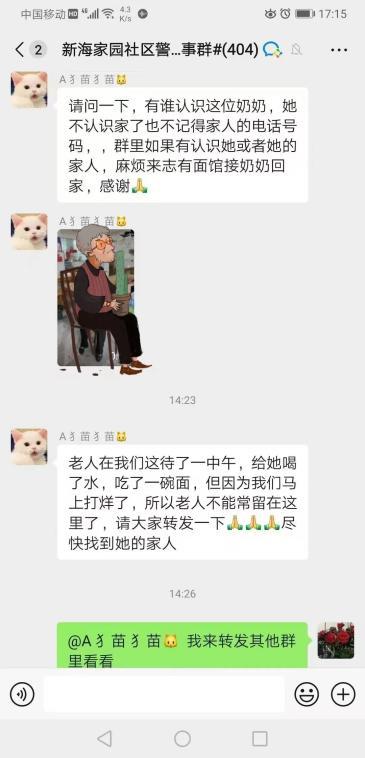
老人迷路后走進(jìn)面館 老板娘暖心送熱水面條 溫情舉動(dòng)獲贊

95歲爺爺拄著拐杖給孫女送菜
又被劉曉慶圈粉了,!

烏克蘭代表團(tuán)抵達(dá)沙特 為澤連斯基訪(fǎng)問(wèn)做準(zhǔn)備

緬甸政府軍與德昂軍進(jìn)行會(huì)談期間,瑙丘地區(qū)戰(zhàn)事激烈,,會(huì)談期間戰(zhàn)火未息

記者應(yīng)該怎么用DeepSeek 真幫手還是挖坑俠?

DeepSeek后又一杭州企業(yè)被美國(guó)盯上 杭州科創(chuàng)企業(yè)再遭美國(guó)打壓,!

巴薩重回西甲榜首 萊萬(wàn)點(diǎn)射助力登頂
記者買(mǎi)7件100%羊絨衫 實(shí)際1根羊絨都沒(méi)有

專(zhuān)家:澤連斯基欲鏟除波羅申科 為選舉清除障礙

巴爾德:對(duì)伊尼戈的犯規(guī)明顯是點(diǎn)球 裁判爭(zhēng)議再現(xiàn)

遼籃兩將離開(kāi)國(guó)家隊(duì)絕非壞事 楊鳴終于等來(lái)他想要的:調(diào)整與機(jī)遇并存
迪麗熱巴旗袍造型好清新 綠意盎然顯氣質(zhì)

男性1.5米就能參軍,,色盲也能報(bào)名,臺(tái)軍新征兵標(biāo)準(zhǔn)有多離譜

吉利汽車(chē)1月零售量同比增長(zhǎng)28.2% 新能源車(chē)助力顯著

未來(lái)馳援國(guó)足 國(guó)青,?17歲華裔新星世界波斬澳超首球,!本人愿歸化 潛力無(wú)限待綻放
前馬競(jìng)青訓(xùn)教練:巴里奧斯被罰下是因?yàn)榉稿e(cuò),,但我們應(yīng)保護(hù)他 支持年輕模范球員

烏方不承認(rèn)美俄談判達(dá)成協(xié)議,強(qiáng)調(diào)自身主權(quán)立場(chǎng)

庫(kù)爾斯克決戰(zhàn)在即,,烏軍掌握頓巴斯低空優(yōu)勢(shì),,欲斷俄軍前線(xiàn)補(bǔ)給 機(jī)械化突擊行動(dòng)升級(jí)

外電:歐洲人“只是自己命運(yùn)的旁觀者” 無(wú)力參與談判決策

馬斯克曝光美國(guó)公務(wù)員薪資細(xì)節(jié) 引爆“數(shù)據(jù)核彈”

美國(guó)為何盯上烏克蘭稀土資源 地緣博弈與資源攫取

臺(tái)名嘴:特朗普面對(duì)中國(guó)無(wú)計(jì)可施

奶奶給孫女縫結(jié)界獸套裝回頭率爆表 巧手奶奶還原度滿(mǎn)分

加拿大出事客機(jī)艙內(nèi)畫(huà)面曝光 乘客倒掛逃生
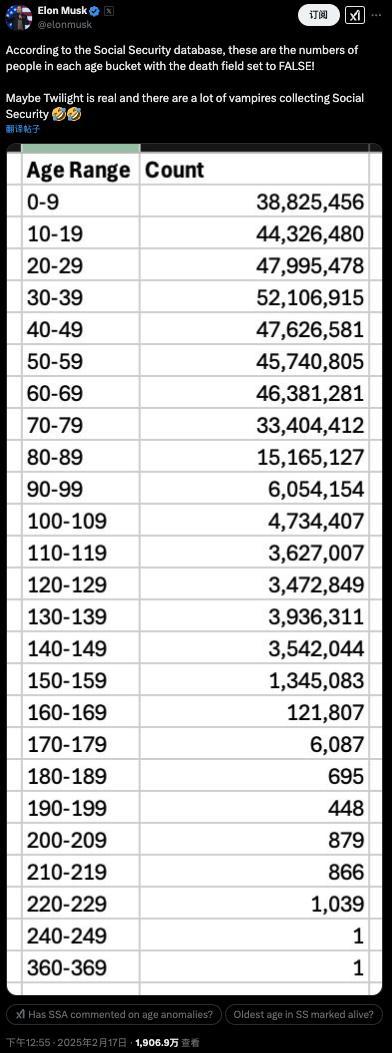
馬斯克查賬美國(guó)社保稱(chēng)發(fā)現(xiàn)360歲老人 馬斯克曝光美國(guó)社保系統(tǒng)驚人漏洞

馬斯克為何敢整治美政府部門(mén) AI引領(lǐng)政府效率革命

美國(guó)客機(jī)機(jī)身翻覆已造成15人受傷 惡劣天氣成事故主因

美國(guó)務(wù)卿改口徑 短暫刪除“不支持臺(tái)獨(dú)”引發(fā)爭(zhēng)議

交易員拋售歐洲債券買(mǎi)入國(guó)防股 歐洲增加安全支出利好軍工股

“一年雨水看雨水”今年雨水多不多?春雨貴如油

“重大轉(zhuǎn)變”,!俄羅斯與北約演習(xí),!外媒:白宮首次明確表態(tài),烏將獲準(zhǔn)坐在桌旁 烏克蘭參與和平談判
相關(guān)新聞
DeepSeek撼動(dòng)AI生態(tài)游戲規(guī)則 低成本創(chuàng)新引領(lǐng)變革
2025-02-10 14:32:11DeepSeek撼動(dòng)AI生態(tài)游戲規(guī)則DeepSeek引發(fā)多國(guó)政府審查 AI開(kāi)源技術(shù)變革
2025-02-06 09:08:44DeepSeek引發(fā)多國(guó)政府審查業(yè)內(nèi):DeepSeek是最好的開(kāi)源實(shí)驗(yàn)室 風(fēng)靡全球引領(lǐng)創(chuàng)新
2025-02-01 09:11:53業(yè)內(nèi)幻方DeepSeek如何“震驚”硅谷 性?xún)r(jià)比與開(kāi)源的勝利
2025-01-27 10:02:46幻方DeepSeek如何震驚硅谷谷歌前CEO評(píng)DeepSeek 呼吁美國(guó)加大開(kāi)源AI努力
2025-01-29 13:59:20谷歌前CEO評(píng)DeepSeek周鴻祎:DeepSeek何以讓Meta恐慌 開(kāi)源新模式挑戰(zhàn)美國(guó)AI基礎(chǔ)
2025-02-03 10:43:42周鴻祎