DeepSeek撼動AI生態(tài)游戲規(guī)則 低成本創(chuàng)新引領(lǐng)變革(2)

無論是價格還是訓(xùn)練成本,DeepSeek都追求細(xì)分和創(chuàng)新,。例如,通過一種新的MLA架構(gòu)和數(shù)據(jù)蒸餾技術(shù),,降低了顯存占用并減少了訓(xùn)練數(shù)據(jù)量,。DeepSeek R1的強(qiáng)大推理能力得益于強(qiáng)化學(xué)習(xí)方法,無需任何監(jiān)督式微調(diào),。
DeepSeek的成功不僅在于技術(shù)創(chuàng)新,,還在于其開源理念。DeepSeek R1的預(yù)訓(xùn)練成本僅為557.6萬美元,,遠(yuǎn)低于GPT-4o的水平,。此外,DeepSeek API服務(wù)定價也遠(yuǎn)低于OpenAI,。這些變化讓市場開始質(zhì)疑,,是否真的需要那么多算力來訓(xùn)練高性能的大模型。
DeepSeek的崛起打破了原有的平衡,,對傳統(tǒng)AI巨頭構(gòu)成了挑戰(zhàn),。OpenAI迅速做出調(diào)整,發(fā)布了o3-mini等新模型,,并降低了API調(diào)用價格,。與此同時,DeepSeek也面臨一些爭議,,包括被指控未經(jīng)授權(quán)竊取數(shù)據(jù)以及遭受網(wǎng)絡(luò)攻擊,。不過,,許多企業(yè)如華為云、騰訊云,、阿里云等紛紛宣布支持DeepSeek大模型,。
這場由DeepSeek掀起的新風(fēng)暴仍在繼續(xù),未來AI行業(yè)的走向充滿變數(shù),。

官宣,!粵港澳大灣區(qū)首個太古里 廣州聚龍灣項(xiàng)目啟動

青島男籃主場過后迎“魔鬼賽程” 四連客挑戰(zhàn)嚴(yán)峻

短劇“頂流”演員被曝出軌塌房!戀情風(fēng)波引發(fā)關(guān)注

貝索斯發(fā)火箭把未婚妻送上太空 全女性團(tuán)隊(duì)創(chuàng)舉引發(fā)熱議

加拿大將停止向美國發(fā)運(yùn)鎳 反擊關(guān)稅威脅

美方單邊關(guān)稅損人不利己 背離多邊規(guī)則

捏造80后死亡率5.2% 多人被處罰 謠言引發(fā)廣泛關(guān)注

格林伍德世界級擺脫后破門 曼聯(lián)棄將閃耀法甲
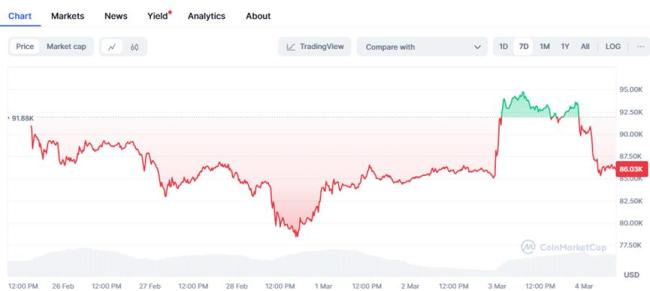
比特幣再跌8%,!特朗普儲備承諾也難抵消市場悲觀情緒 宏觀因素主導(dǎo)下跌
短劇“頂流”演員被曝出軌塌房,!戀情風(fēng)波引發(fā)關(guān)注

美軍首次公開“忍者”導(dǎo)彈打擊畫面 精確斬首行動再現(xiàn)
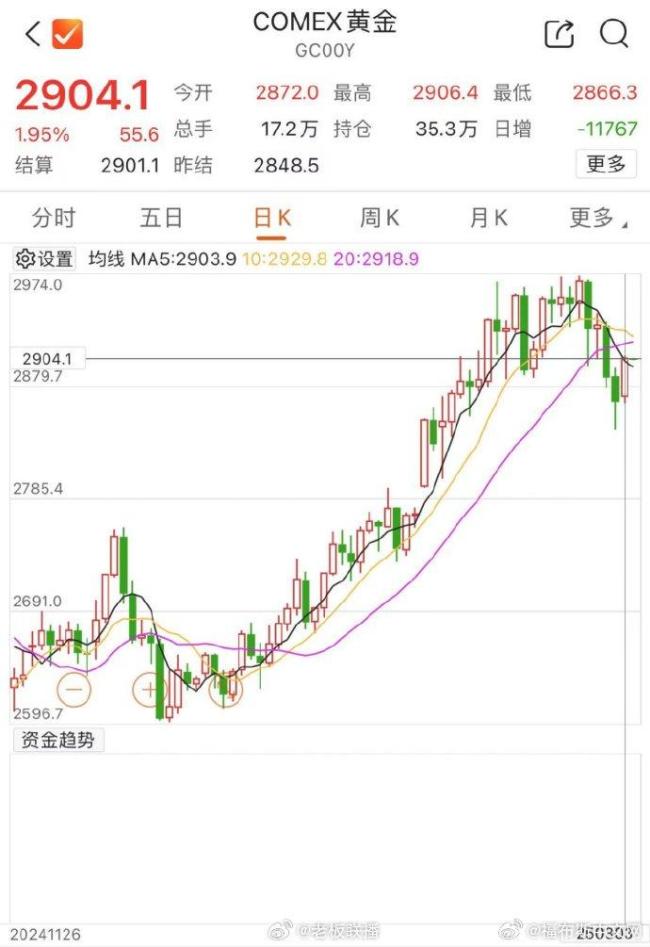
金價重回2900美元 貴金屬市場再度走強(qiáng)

加拿大準(zhǔn)備好對美一系列報(bào)復(fù):關(guān)稅反擊在即

澤連斯基:要換掉我不容易的 所以必須與我談判 美烏關(guān)系面臨考驗(yàn)

男子因家庭矛盾發(fā)現(xiàn)自己是被抱養(yǎng)的

李東生:建議降低靈活就業(yè)者參保門檻 減輕繳費(fèi)負(fù)擔(dān)

庫克又下場帶貨 預(yù)告本周發(fā)Air新品 M4 MacBook Air即將登場
官宣!粵港澳大灣區(qū)首個太古里 廣州聚龍灣項(xiàng)目啟動

日本民間團(tuán)體要求徹查駐日美軍基地 質(zhì)疑污染標(biāo)準(zhǔn)

加沙面粉和蔬菜價格上漲超100倍 人道援助受阻
青島男籃主場過后迎“魔鬼賽程” 四連客挑戰(zhàn)嚴(yán)峻

特朗普25%關(guān)稅無談判空間,,加拿大外長“秒回?fù)簟保簣?bào)復(fù)清單就位 貿(mào)易戰(zhàn)一觸即發(fā)

澤連斯基說烏克蘭需要和平 安全保障是關(guān)鍵

美國同意出售F35戰(zhàn)斗機(jī) 印度開始“狂歡”

美國一參議員呼吁澤連斯基辭職 澤連斯基強(qiáng)硬回應(yīng)
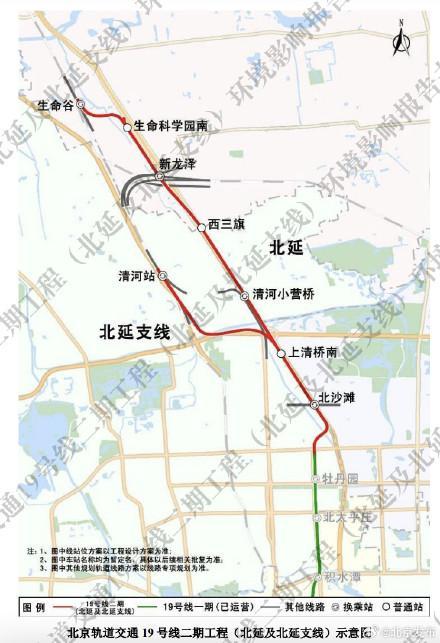
北京地鐵19號線有新動向 環(huán)評公示揭曉

牛彈琴:特朗普對歐發(fā)出最輕蔑一問

“驚蟄是雨天,,農(nóng)民一年閑”有啥征兆?

消息人士:中國正在研究反制措施 堅(jiān)決抵制美國再次加稅

馬斯克一家三代蹭特朗普總統(tǒng)專機(jī)“陸戰(zhàn)隊(duì)一號”前往海湖莊園!

Rokid創(chuàng)始人預(yù)言五年內(nèi)AR眼鏡將取代手機(jī)

僅剩8天,,彈劾案奏響終曲,,尹錫悅搖搖欲墜 結(jié)局即將揭曉

日民間團(tuán)體要求政府徹查駐日美軍基地,追責(zé)有機(jī)氟污染問題
特朗普澤連斯基矛盾再度升級 白宮爭吵后局勢惡化
業(yè)內(nèi):英偉達(dá)熊市趨勢可能才剛開始
相關(guān)新聞
開源DeepSeek如何撼動全球AI市場 性能價格雙突破
2025-02-01 23:17:08開源DeepSeek如何撼動全球AI市場DeepSeek繁榮了歐洲AI生態(tài) 推動成本降低與創(chuàng)新
2025-02-04 18:13:37DeepSeek繁榮了歐洲AI生態(tài)DeepSeek驅(qū)動RISC-V崛起 重構(gòu)全球AI算力生態(tài)
2025-03-02 22:34:09DeepSeek驅(qū)動RISC-V崛起DeepSeek開源第三日 行業(yè)影響幾何 加速AI計(jì)算生態(tài)構(gòu)建
2月26日,在開源周第三天,,DeepSeek宣布開放高效的FP8 GEMM庫DeepGEMM,。這三天的發(fā)布內(nèi)容都與算法相關(guān),偏向技術(shù)層面
2025-02-26 21:35:35DeepSeek開源第三日行業(yè)影響幾何周鴻祎談DeepSeek的最突出技術(shù)貢獻(xiàn) 開源共享引領(lǐng)AI新生態(tài)
2025-02-02 12:43:09周鴻祎談DeepSeek的最突出技術(shù)貢獻(xiàn)DeepSeek訓(xùn)練仍基于英偉達(dá)CUDA生態(tài) 國產(chǎn)AI芯片迎適配潮
在DeepSeek極低成本的推動下,,開源模型和閉源模型之間的差距顯著縮小,,掀起了一輪國產(chǎn)AI芯片廠商競相適配的風(fēng)潮
2025-02-15 18:37:10DeepSeek訓(xùn)練仍基于英偉達(dá)CUDA生態(tài)








