AI大??ㄅ廖魇①滵eepSeek 強化學習展現(xiàn)巨大潛力

AI大牛卡帕西盛贊DeepSeek,!近日,,OpenAI聯(lián)合創(chuàng)始人,、前特斯拉AI總監(jiān)安德烈·卡帕西在YouTube上發(fā)布了一則3.5小時的免費課程,向普通觀眾全面介紹了大模型的相關知識,。他以最近爆火的DeepSeek-R1為例,詳細講解了強化學習技術路徑的巨大潛力,。
卡帕西指出,在大模型訓練體系中,,預訓練、監(jiān)督微調和強化學習是三個主要階段。他認為強化學習是其中最關鍵的一環(huán),盡管其本質是“試錯學習”,,但在選擇最佳解決方案和提示詞分布等方面仍有許多細節(jié)需要解決。這些問題目前僅限于各大AI實驗室內部,缺乏統(tǒng)一標準。
DeepSeek-R1的研究論文首次公開討論了強化學習在大語言模型中的應用,,并分享了這項技術如何使模型展現(xiàn)出推理能力,??ㄅ廖髡J為R1在強化學習過程中涌現(xiàn)出的思維能力是最令人難以置信的成效。未來,如果繼續(xù)在大模型領域對強化學習進行擴展,,有望讓大模型解鎖像AlphaGo那樣的“神之一手”,,創(chuàng)造出前所未有的思考方式,例如用全新語言進行思考。但前提是需要創(chuàng)造足夠大且多樣的問題集,,讓模型能夠自由探索解決方案,。
強化學習的基本工作方式是讓模型在可驗證的問題上不斷試錯,并根據(jù)答案正誤激勵正確行為,,最終引導模型提升能力,。當前主流的大語言模型訓練體系包括預訓練、監(jiān)督微調和強化學習,。預訓練和監(jiān)督微調已發(fā)展成熟,,而強化學習仍處于早期階段。DeepSeek-R1論文的重要意義在于它是第一篇公開討論強化學習在大語言模型應用的論文,,激發(fā)了AI界使用RL訓練大語言模型的興趣,,并提供了許多研究結果和技術細節(jié)。
DeepSeek在R1論文中展示了R1-Zero在AIME競賽數(shù)學問題上的準確性提升過程,。隨著強化學習步驟增加,,模型準確性持續(xù)上升。更令人驚喜的是,,模型在這一過程中形成了一套獨特的解題方法,,傾向于使用更多token來提高準確性。R1在強化學習過程中展現(xiàn)了所謂的“aha moment”,,即通過嘗試多種想法從不同角度解決問題,,顯著提升了準確率。這種解決方式類似于人類解決數(shù)學問題的模式,,但不是靠模仿或硬編碼,,而是自然涌現(xiàn)的。R1重新發(fā)現(xiàn)了人腦的思維過程,,自學了思維鏈(CoT),,這是RL應用于大語言模型時最令人難以置信的成效。

女子按摩肩頸后急性腦梗死進了ICU

《仁心俱樂部》,,笑著笑著就默淚了 醫(yī)生的笑與淚

意甲:尤文2-0完勝維羅納 圖拉姆破門 庫普梅納斯建功 尤文豪取5連勝

特朗普再言“忍不了”澤連斯基 爭執(zhí)未停歇

村民家中煤氣罐泄漏噴火 消防出手 廚房用火需謹慎

泰國政府研究建隔離墻 探討邊境管控新措施

沒等大陸動手,,馬斯克先收了“臺獨”分子的飯碗

澤連斯基10年間從意氣風發(fā)到憔悴 命運巨變

賴因德斯:能在來到米蘭一年半之后續(xù)約 我真的很自豪 感激與期待未來

中方談美國鼓動他國對華加稅 貿易戰(zhàn)無贏家

美再次對華加征10%關稅 中方堅決反對 強烈不滿美方威脅
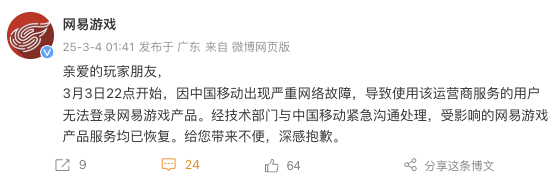
網(wǎng)易游戲發(fā)文致歉 網(wǎng)絡故障已解決

阿諾拉奧斯卡最佳原創(chuàng)劇本 五項大獎閃耀頒獎夜

特朗普:對澤連斯基不會再忍了 美烏關系緊張升級

大V:烏克蘭將面臨三大嚴峻情況 盟友或成幕后推手
女子按摩肩頸后急性腦梗死進了ICU

巴菲特罕見發(fā)聲 關稅或引發(fā)通脹

陳曉離婚后狀態(tài) 首次公開露面精神飽滿

外媒稱特朗普上任后歐盟和中國走近 大國博弈新篇章

外賣員雪天路邊睡著 誤會解開身體無恙
《仁心俱樂部》,笑著笑著就默淚了 醫(yī)生的笑與淚

外交部駁斥魯比奧涉華言論 回擊冷戰(zhàn)思維

專家:美加征汽車關稅想“一石三鳥” 盟友反彈強烈
意甲:尤文2-0完勝維羅納 圖拉姆破門 庫普梅納斯建功 尤文豪取5連勝

中國空軍赴哈瓦那看望古巴飛行員老爺爺 溫暖的雙向奔赴

澤連斯基發(fā)視頻感謝美國 白宮會晤風波后示好

是否會向烏克蘭派遣維和部隊,?中方回應 支持和平解決危機

闞清子被曝懷孕后現(xiàn)身機場 孕后狀態(tài)成焦點

金價大跳水入手即虧 金飾價格斷崖式下調

特朗普確認對加墨征收關稅 美股重挫 市場恐慌情緒升高

巴格拉姆空軍基地被中國接管,?阿富汗駁斥美方 情緒化言論遭批

美烏談崩 北約或成最大輸家 美國兩黨內斗外溢

歐洲提出的俄烏和平方案能實現(xiàn)嗎 歐洲挺身而出爭奪主導權
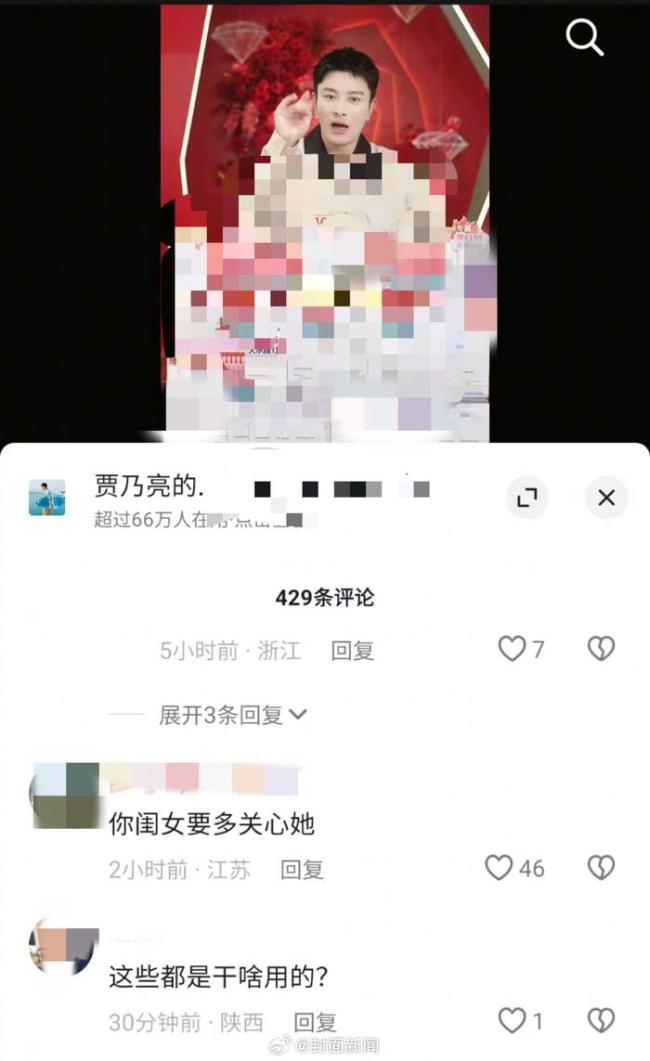
網(wǎng)友留言賈乃亮多關心甜馨 重視女兒心理健康
一男子全家六人患腸癌:兄妹7人5人確診腸癌
相關新聞
廣東省委書記盛贊DeepSeek 邊緣AI迎來新機遇
2025-02-05 21:50:33廣東省委書記盛贊DeepSeekDeepSeek爆火的啟示 AI算命成新寵
最近,,社交平臺上涌現(xiàn)出大量關于AI算命的討論,。以DeepSeek為代表的AI算命在年輕人中掀起了一股熱潮,成為他們在應對婚戀,、職場等壓力時的“救命稻草”
2025-02-16 19:52:04DeepSeek爆火的啟示分析:DeepSeek開啟AI的iPhone4時刻 智能手機AI大戰(zhàn)升級
2025-02-25 21:09:04分析DeepSeek爆火:AI正在“殺死”公司 改變全球AI競賽格局
我們需要更多的DeepSeek。過去幾年里,,中國大模型從業(yè)者們經(jīng)常被問及中國距離追上ChatGPT還有多遠,。2025年初,這個問題有了新的答案
2025-02-21 17:49:36DeepSeek爆火DeepSeek時代的“生存指南” 正視AI的力量
2025-02-22 00:15:12DeepSeek時代的生存指南DeepSeek啟動“開源周” 推動AI技術革新
2025-02-24 18:17:43DeepSeek啟動開源周








