AI大??ㄅ廖魇①滵eepSeek 強(qiáng)化學(xué)習(xí)展現(xiàn)巨大潛力(2)

雖然OpenAI的一些模型也使用了RL技術(shù),,性能與DeepSeek-R1相當(dāng),但卡帕西表示他大約80%-90%的查詢依然由GPT-4o完成,,只有遇到非常困難的代碼和數(shù)學(xué)問(wèn)題時(shí)才會(huì)使用思考模型,。
強(qiáng)化學(xué)習(xí)是一種強(qiáng)大的學(xué)習(xí)方式,這一點(diǎn)已在圍棋領(lǐng)域得到驗(yàn)證,。DeepMind開(kāi)發(fā)的AlphaGo通過(guò)自博弈和強(qiáng)化學(xué)習(xí)突破了人類棋手的實(shí)力上限,。AlphaGo通過(guò)廣泛嘗試制勝策略,甚至超越了頂級(jí)玩家李世石,。理論上,,強(qiáng)化學(xué)習(xí)可以持續(xù)運(yùn)行,但由于成本原因,,DeepMind團(tuán)隊(duì)選擇在某些時(shí)候停止,。通過(guò)DeepSeek-R1,我們開(kāi)始看到強(qiáng)化學(xué)習(xí)在大語(yǔ)言模型推理問(wèn)題上的巨大潛力,。
未來(lái),,如果我們繼續(xù)在大語(yǔ)言模型領(lǐng)域擴(kuò)展強(qiáng)化學(xué)習(xí),可能解鎖那些讓人類難以理解的解決方案,。這可能包括發(fā)現(xiàn)新的類比,、思考策略,甚至是發(fā)明一種更適合思考的語(yǔ)言,。實(shí)現(xiàn)這些的前提是為模型創(chuàng)造足夠大的問(wèn)題集,讓其不斷優(yōu)化和完善解決問(wèn)題的策略,。
卡帕西還預(yù)言了未來(lái)幾大AI趨勢(shì),,包括多模態(tài)AI和測(cè)試時(shí)訓(xùn)練,。由于音頻、圖片,、視頻等內(nèi)容都可以被token化,,采用大語(yǔ)言模型的訓(xùn)練邏輯將提升模型在相關(guān)領(lǐng)域的表現(xiàn)。此外,,測(cè)試時(shí)訓(xùn)練將成為AI研究的前沿方向,,允許模型根據(jù)新數(shù)據(jù)微調(diào)參數(shù),更好地應(yīng)對(duì)特定問(wèn)題,。
強(qiáng)化學(xué)習(xí)作為上一個(gè)世代AI能力突破的重要方向,,由DeepSeek在生成式AI時(shí)代再度發(fā)揚(yáng)光大。盡管有一些質(zhì)疑聲音,,但許多專注于技術(shù)本身的AI開(kāi)發(fā)者認(rèn)為,,DeepSeek的開(kāi)源突破對(duì)整個(gè)AI界的發(fā)展是有利的,他們期待DeepSeek帶來(lái)更多驚喜,。AI大??ㄅ廖魇①滵eepSeek!

女子按摩肩頸后急性腦梗死進(jìn)了ICU

《仁心俱樂(lè)部》,,笑著笑著就默淚了 醫(yī)生的笑與淚

意甲:尤文2-0完勝維羅納 圖拉姆破門 庫(kù)普梅納斯建功 尤文豪取5連勝

特朗普再言“忍不了”澤連斯基 爭(zhēng)執(zhí)未停歇

村民家中煤氣罐泄漏噴火 消防出手 廚房用火需謹(jǐn)慎

泰國(guó)政府研究建隔離墻 探討邊境管控新措施

沒(méi)等大陸動(dòng)手,,馬斯克先收了“臺(tái)獨(dú)”分子的飯碗

澤連斯基10年間從意氣風(fēng)發(fā)到憔悴 命運(yùn)巨變

賴因德斯:能在來(lái)到米蘭一年半之后續(xù)約 我真的很自豪 感激與期待未來(lái)

中方談美國(guó)鼓動(dòng)他國(guó)對(duì)華加稅 貿(mào)易戰(zhàn)無(wú)贏家

美再次對(duì)華加征10%關(guān)稅 中方堅(jiān)決反對(duì) 強(qiáng)烈不滿美方威脅
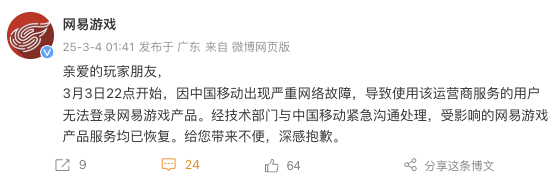
網(wǎng)易游戲發(fā)文致歉 網(wǎng)絡(luò)故障已解決

阿諾拉奧斯卡最佳原創(chuàng)劇本 五項(xiàng)大獎(jiǎng)閃耀頒獎(jiǎng)夜

特朗普:對(duì)澤連斯基不會(huì)再忍了 美烏關(guān)系緊張升級(jí)

大V:烏克蘭將面臨三大嚴(yán)峻情況 盟友或成幕后推手
女子按摩肩頸后急性腦梗死進(jìn)了ICU

巴菲特罕見(jiàn)發(fā)聲 關(guān)稅或引發(fā)通脹

陳曉離婚后狀態(tài) 首次公開(kāi)露面精神飽滿

外媒稱特朗普上任后歐盟和中國(guó)走近 大國(guó)博弈新篇章

外賣員雪天路邊睡著 誤會(huì)解開(kāi)身體無(wú)恙
《仁心俱樂(lè)部》,,笑著笑著就默淚了 醫(yī)生的笑與淚

外交部駁斥魯比奧涉華言論 回?fù)衾鋺?zhàn)思維

專家:美加征汽車關(guān)稅想“一石三鳥(niǎo)” 盟友反彈強(qiáng)烈
意甲:尤文2-0完勝維羅納 圖拉姆破門 庫(kù)普梅納斯建功 尤文豪取5連勝

中國(guó)空軍赴哈瓦那看望古巴飛行員老爺爺 溫暖的雙向奔赴

澤連斯基發(fā)視頻感謝美國(guó) 白宮會(huì)晤風(fēng)波后示好

是否會(huì)向?yàn)蹩颂m派遣維和部隊(duì)?中方回應(yīng) 支持和平解決危機(jī)

闞清子被曝懷孕后現(xiàn)身機(jī)場(chǎng) 孕后狀態(tài)成焦點(diǎn)

金價(jià)大跳水入手即虧 金飾價(jià)格斷崖式下調(diào)

特朗普確認(rèn)對(duì)加墨征收關(guān)稅 美股重挫 市場(chǎng)恐慌情緒升高

巴格拉姆空軍基地被中國(guó)接管?阿富汗駁斥美方 情緒化言論遭批

美烏談崩 北約或成最大輸家 美國(guó)兩黨內(nèi)斗外溢

歐洲提出的俄烏和平方案能實(shí)現(xiàn)嗎 歐洲挺身而出爭(zhēng)奪主導(dǎo)權(quán)
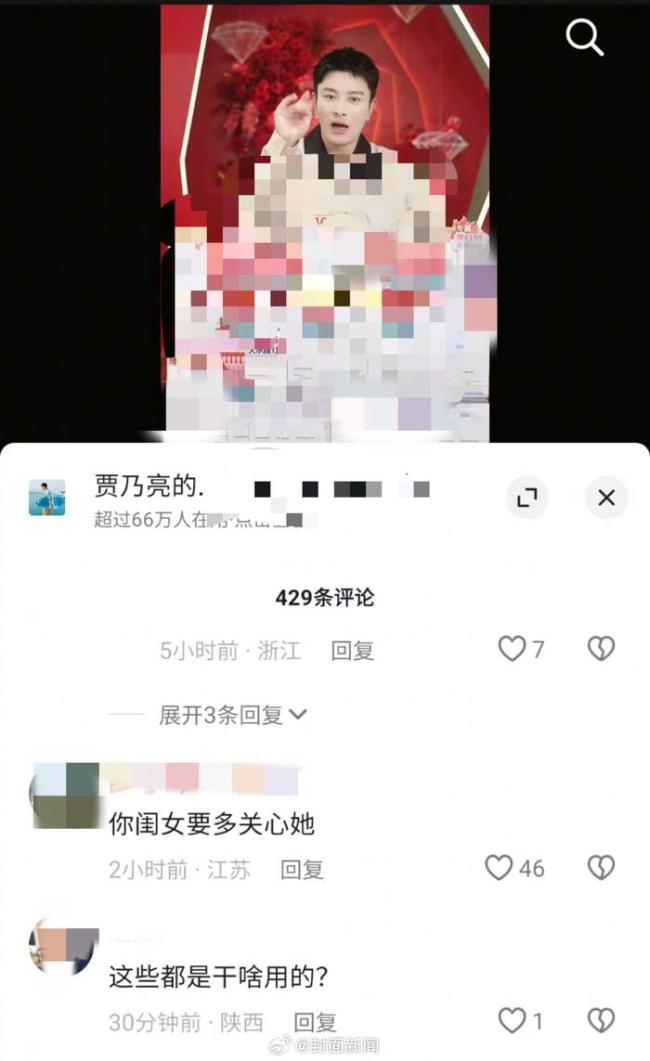
網(wǎng)友留言賈乃亮多關(guān)心甜馨 重視女兒心理健康
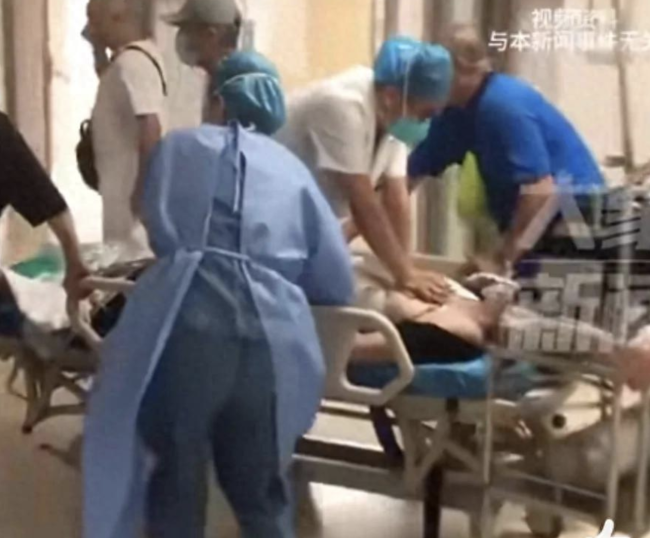
一男子全家六人患腸癌:兄妹7人5人確診腸癌
相關(guān)新聞
廣東省委書(shū)記盛贊DeepSeek 邊緣AI迎來(lái)新機(jī)遇
2025-02-05 21:50:33廣東省委書(shū)記盛贊DeepSeekDeepSeek爆火的啟示 AI算命成新寵
2025-02-16 19:52:04DeepSeek爆火的啟示分析:DeepSeek開(kāi)啟AI的iPhone4時(shí)刻 智能手機(jī)AI大戰(zhàn)升級(jí)
2025-02-25 21:09:04分析DeepSeek爆火:AI正在“殺死”公司 改變?nèi)駻I競(jìng)賽格局
2025-02-21 17:49:36DeepSeek爆火DeepSeek時(shí)代的“生存指南” 正視AI的力量
2025-02-22 00:15:12DeepSeek時(shí)代的生存指南DeepSeek啟動(dòng)“開(kāi)源周” 推動(dòng)AI技術(shù)革新
2025-02-24 18:17:43DeepSeek啟動(dòng)開(kāi)源周








