深度開源助推AI大模型普惠“破圈” 開源潮熱度空前

過去的一周,,DeepSeek帶動的人工智能大模型“開源潮”熱度空前。2月24日,,國內AI企業(yè)深度求索(DeepSeek)啟動“開源周”,,計劃在一周內每天開源一個代碼庫,以完全透明的方式與全球開發(fā)者分享他們的研究進展,。3月1日,,DeepSeek發(fā)布《DeepSeek-V3/R1推理系統(tǒng)概覽》技術文章,首次公布模型推理系統(tǒng)優(yōu)化細節(jié),,“開源周”就此收官。
五天時間里,,DeepSeek開源了五個核心代碼庫,,基本覆蓋了AI大模型開發(fā)的關鍵環(huán)節(jié),,如硬件性能高效利用、數(shù)據(jù)處理提速等,,有助于降低技術門檻和成本,。DeepSeek方面表示,,希望分享的每一行代碼都能加速行業(yè)發(fā)展進程。開源不僅指開放源代碼,,還應包括開放資源,。中國工程院院士王堅認為,在人工智能時代,,開源是對社會和全世界的貢獻。
以2月24日DeepSeek向公眾開源的FlashMLA代碼庫為例,,它針對Hopper GPU架構開發(fā),,解決了大模型處理不同長度文本的問題,。田豐解釋說,,F(xiàn)lashMLA像可伸縮的快遞箱子,,通過精準分配GPU資源處理可變長度文本序列,實現(xiàn)高效解碼,。除了FlashMLA,,DeepSeek“開源周”還開放了DeepEP、DeepGEMM等關鍵技術,。田豐認為,開源意味著企業(yè)免費提供研發(fā)成果給全球開發(fā)者,,開發(fā)者在不同環(huán)境試用或迭代過程中會完善模型,,推動技術快速迭代更新,。
DeepSeek自成立以來一直堅持開源策略。今年年初,,開源模型DeepSeek-R1推出后引發(fā)“接入潮”。如今,,DeepSeek通過“開源周”進一步擴大開源程度,,將有力助推AI大模型在模型,、算力,、應用三個層面實現(xiàn)普惠“破圈”。在模型方面,,DeepSeek打破了少數(shù)國際巨頭對頂尖大模型的技術壟斷,;在算力方面,,通過軟件優(yōu)化彌補硬件差距,讓全球開發(fā)者可以用個人級算力進行科研創(chuàng)新,;在應用方面,預計近期可能涌現(xiàn)出上百個行業(yè)應用大模型,,覆蓋農業(yè)、工業(yè),、服務業(yè)等領域,。
長江證券發(fā)布的研報認為,此次DeepSeek開源代碼庫或將圍繞降本增效這一核心,,改變此前堆算力,、堆數(shù)據(jù)的AI開發(fā)邏輯,加速技術普惠化,。同時,,繼續(xù)開源策略也將進一步加速AI技術平權,并在其基礎上催生大量垂類應用,,進一步帶動算力需求爆發(fā),。
截至2月24日,DeepSeek-R1在國際知名開源社區(qū)Hugging Face上已獲得上萬點贊,,成為最受歡迎的開源大模型之一,。多個團隊成功復現(xiàn)了DeepSeek的核心模型,如Hugging Face的Open-R1,、香港科技大學的simpleRL-reason等,。田豐提到,已有不少人在家部署了DeepSeek系列模型并積極創(chuàng)新,,訓練行業(yè)模型,。他認為,圍繞DeepSeek的開源社區(qū)生態(tài)已經逐漸建立起來,,其擴張速度取決于社區(qū)內開發(fā)者的數(shù)量,。
值得注意的是,自今年1月DeepSeek火爆出圈以來,,越來越多的AI廠商開始擁抱開源,。例如,字節(jié)跳動,、昆侖萬維,、百度文心一言等均推出了開源模型。清華大學計算機科學與技術系長聘副教授劉知遠表示,AI以及整個計算機科學的底層推動邏輯始終是建立在開源精神之上的,,未來開源會更深入,、更廣泛地應用。
然而,,從全球來看,,這種趨勢尚未統(tǒng)一。例如,,OpenAI依然堅持閉源路線,,Google則采取混合策略。閉源模式有利于形成技術壁壘,,為企業(yè)提供穩(wěn)定的收入來源,。但單點技術的開源不會削弱其核心優(yōu)勢,反而可能豐富整個行業(yè)的生態(tài),。真正的競爭力在于如何整合,、優(yōu)化并將技術應用于大規(guī)模、復雜的實際場景中,。
大模型“開源潮”涌起,,AI企業(yè)未來的發(fā)力點在于提高開源模型的推理能力、計算性能,,降低部署門檻,。此外,在開源底層基礎模型之外,,芯片,、數(shù)據(jù)、應用等層面的軟硬件協(xié)同創(chuàng)新也很關鍵,。國產GPU,、存儲系統(tǒng)如何與AI技術深度適配,數(shù)據(jù)處理模塊如何更高效地支持模型運行等,,在模型之上還有大量生態(tài)需要補足,。這是開源生態(tài)構建的重要內容,也是眾多企業(yè)應該抓住的機會,。

OpenAI計劃今年完成成為盈利性公司的轉變,!

張家界回應因韓劇臺詞又在韓國爆火 韓流效應帶動旅游熱潮

三月初四,遵循3事不做,,2地不去,1樣要吃 傳統(tǒng)習俗迎春耕

大V談俄羅斯4萬噸準航母曝光 中俄印態(tài)度各異
60歲大媽種牙誤將2.2厘米扳手吸入氣道 驚心動魄“氣管拆彈”

馬斯克宣布將辭去美政府效率部職務 削減萬億赤字目標在即

緬甸領導人敏昂萊慰問中國救援醫(yī)療隊:感謝第一時間來緬提供幫助 查看搜救情況
勒龐被禁止參選5年,,特朗普回應:這事很大
特朗普不舍馬斯克任期將結束 稱贊其才華希望多留

臺防務部門:山東艦進入臺灣所謂“應變區(qū)” 啟動應變機制嚴密監(jiān)控

專家直播解讀解放軍臺島周邊演訓 堅定捍衛(wèi)國家主權
中國版“頭號玩家”,,全球首通后被邀請至瑞士

FAA結束對星艦第七次試飛失敗調查 推進劑泄漏致空中解體
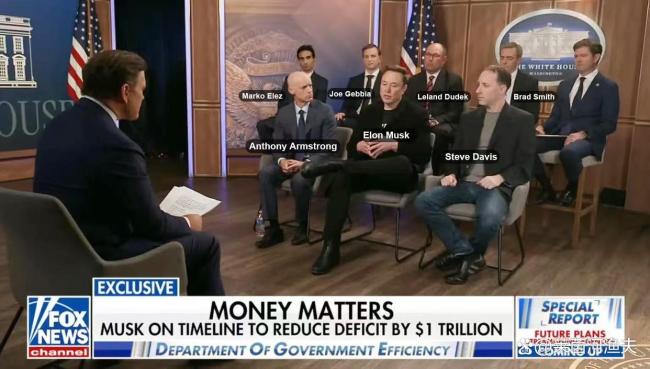
馬斯克的DOGE展開新一輪技術革新 硅谷邏輯重塑華盛頓

日本知名餐飲連鎖接連發(fā)現(xiàn)老鼠蟑螂 全國門店暫停營業(yè)

中國在南海東部海域發(fā)現(xiàn)億噸級油田 展現(xiàn)深層勘探潛力
OpenAI計劃今年完成成為盈利性公司的轉變,!
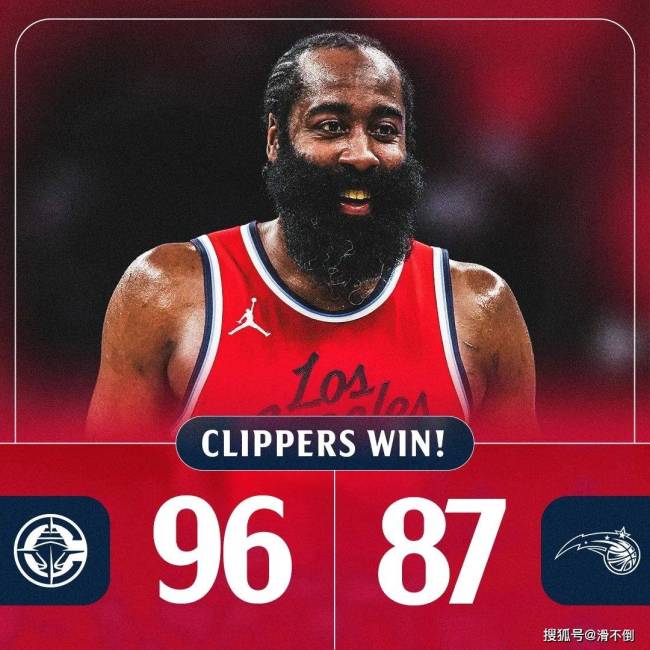
哈登單場7搶斷全收錄,!創(chuàng)快船生涯新高:大胡子也變身鐵閘 助力逆轉勝魔術

中國出手,!決定向緬甸提供1億元捐款!

誰在運作美對華技術遏制政策 商務部人事變動揭示真相

曼城官方:哈蘭德左腳踝受傷,,預計賽季內復出

緬甸地震的危害究竟有多大 次生災害更令人擔憂
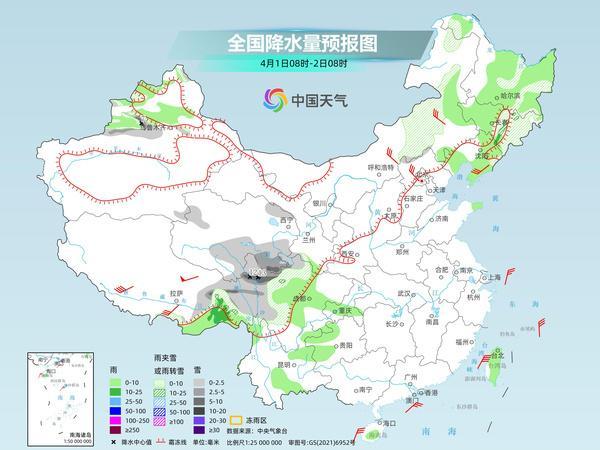
江南華南陰雨暫歇有望放晴 南方多地迅速回暖
張家界回應因韓劇臺詞又在韓國爆火 韓流效應帶動旅游熱潮

現(xiàn)場:4名美軍士兵駕駛70噸重的裝甲車演習時陷入沼澤,,3人遇難1人失蹤!
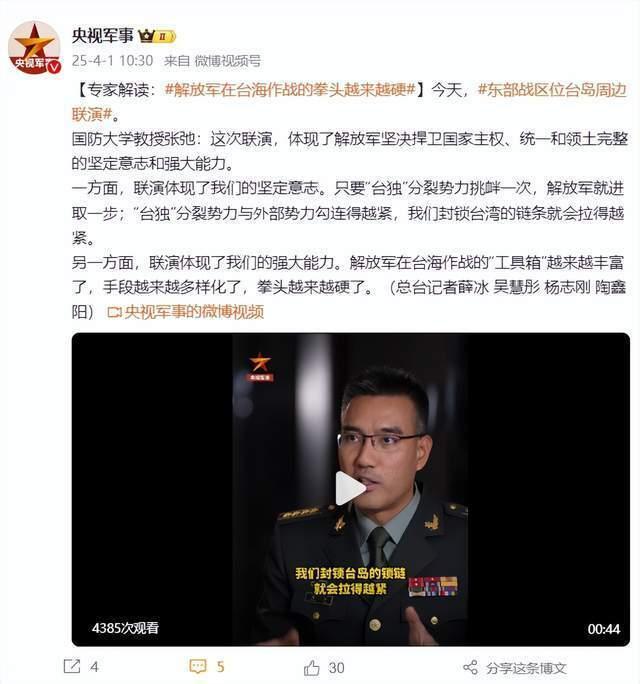
解放軍在臺海作戰(zhàn)的拳頭越來越硬 聯(lián)演彰顯堅定意志與強大能力

臺媒稱7艘解放軍艦艇在臺海周邊活動 持續(xù)戰(zhàn)備警巡

大V:特朗普“百日訪華”計劃破產 沙特成首訪選擇

俄戰(zhàn)機投3噸級炸彈轟炸烏軍 無掩護的士兵基本無法存活

美國和伊朗開戰(zhàn)的可能性有多大 局勢升級引關注

外媒:特朗普稱預計普京將在俄烏?;饏f(xié)議中“履行他的職責” 展現(xiàn)信心與期待

大學生因電動車燃爆致全身90%燒傷 室友、商家及房東被訴
芯片代工巨頭格芯聯(lián)電傳出合并消息 或將重塑行業(yè)格局
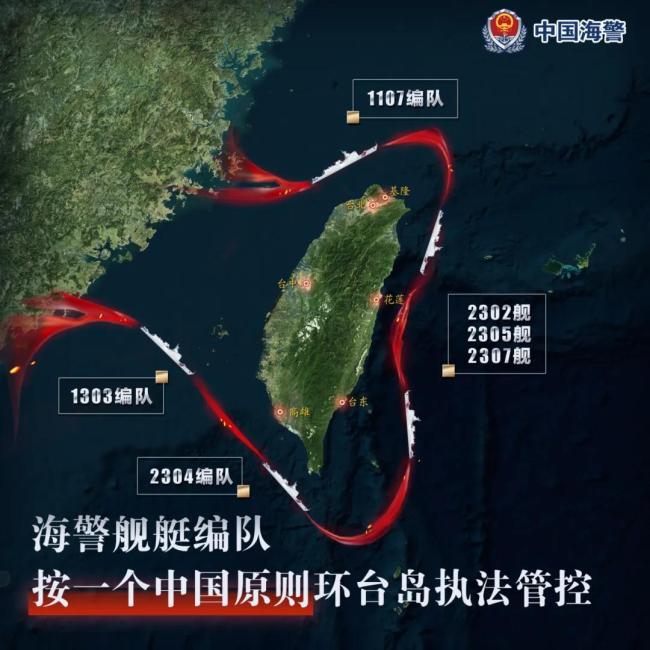
多支海警艦艇編隊位臺島周邊演練 依法管控實際行動
三月初四,,遵循3事不做,,2地不去,1樣要吃 傳統(tǒng)習俗迎春耕
相關新聞
創(chuàng)始人說DeepSeek站在了巨人的肩上 開源助力AI破圈
2025-02-05 08:55:48創(chuàng)始人說DeepSeek站在了巨人的肩上經濟日報:大模型身瘦路更寬 輕量級AI普惠化
2025-01-26 10:43:25經濟日報騰訊:全面擁抱DeepSeek大模型 推動AI技術普惠化
2025-03-05 07:48:31騰訊中國大模型密集開源影響幾何 推動AI生態(tài)加速發(fā)展
2025-03-26 13:11:17中國大模型密集開源影響幾何春節(jié)檔AI唱主角 國產大模型密集更新 開源模型展現(xiàn)強勁勢頭
2025-01-29 19:34:36春節(jié)檔AI唱主角國產大模型密集更新通義千問開源Qwen2.5 刷新業(yè)界紀錄,,登頂開源大模型王座
2024-09-19 17:24:50通義千問開源Qwen








