外界熱議DeepSeek低調(diào)“上新” V4與R2猜想再起

中國人工智能初創(chuàng)公司深度求索(DeepSeek)24日深夜低調(diào)上線了DeepSeek-V3的新版本DeepSeek-V3-0324,,參數(shù)量為6850億,。新版本在代碼,、數(shù)學,、推理等多個方面的能力顯著提升,,甚至代碼能力追平美國Anthropic公司大模型Claude 3.7,。外界對DeepSeek-V3-0324的關注不僅在于其性能提升,,還猜測這是否意味著更新一代的V4與R2大模型即將發(fā)布,。
關于DeepSeek-V3新版本的能力提升,,DeepSeek表示,,新版本代碼能力顯著提升,接近Claude 3.7水平,。例如,,有用戶在實測中發(fā)現(xiàn),V3-0324能一次性生成800行無錯誤的網(wǎng)頁代碼,,并實現(xiàn)動態(tài)響應式布局和交互效果,。此外,新版本的數(shù)學與邏輯推理能力也有所增強,,如經(jīng)典的“4升水壺問題”和數(shù)學競賽題,,部分表現(xiàn)接近專業(yè)推理模型。V3-0324采用MIT許可證,,允許自由修改,、分發(fā)及商業(yè)化應用,進一步降低了開發(fā)者的使用門檻,。
清華大學新聞學院,、人工智能學院教授沈陽認為,DeepSeek-V3-0324不僅是V3系列的一次迭代,,更是中國AI技術崛起的又一力證,。其在性能、效率和開源策略上的綜合優(yōu)勢使其在全球大語言模型領域占據(jù)重要地位,。未來,,DeepSeek可能通過推理能力提升和多模態(tài)擴展來鞏固技術領先優(yōu)勢,同時在中美競爭和社區(qū)生態(tài)中尋找平衡,。沈陽指出,,DeepSeek-V3-0324的發(fā)布看似是一次“小更新”,但其性能跳躍表明該團隊可能在為后續(xù)重大版本鋪路。
路透社今年2月底引述知情人士的說法稱,,DeepSeek原計劃在今年5月初發(fā)布R2,,但現(xiàn)在希望盡早推出,具體時間尚未透露,。此外,,DeepSeek希望新模型在代碼生成和多語言推理方面的表現(xiàn)進一步提升,。不過,,這些傳言并未得到DeepSeek公司的證實與回應。
沈陽表示,,DeepSeek-V3-0324的推出進一步凸顯中國AI企業(yè)在技術與成本上的競爭力,。美國對華GPU出口限制可能促使中國企業(yè)加速國產(chǎn)硬件適配,同時其開源模式或引發(fā)西方廠商的連鎖動作,,例如推出更強閉源模型,。他認為,2025年可能是中美AI競爭的分水嶺,。
在OpenAI公司的GPT大模型要把通用大模型和推理大模型融合在一起的背景下,,外界關注包括DeepSeek在內(nèi)的中國頭部大模型是否會最終出現(xiàn)這種合并的趨勢。沈陽認為這種可能性存在,,因為對于用戶來說,,更關心的是大模型能否給出更為智能、合理的參考答案,。

海關消殺截獲2000余只德國小蠊 嚴防有害病菌傳播

澳門世界杯首場平局:單曉娜2比2伯格斯特隆

被沙灘上這張心形婚紗照感動,!百名游客幫輪椅女孩圓夢站立婚紗照
如何跟大國相處 美國還得補課

美國對中國威脅最大的核潛艇力量信譽一落千丈,到底發(fā)生了什么,?

專家稱關稅戰(zhàn)讓美國的盟友都不再相信它

神十九乘組即時反饋太空之家舒適度 問卷視頻記錄體驗

40多年保護讓朱鹮從7只到過萬只 生態(tài)守護見證奇跡

中國鍛壓協(xié)會發(fā)布關于加征關稅聲明 堅決反對貿(mào)易保護主義

小鵬銷售承諾贈品門店要去網(wǎng)購,?車主:被當傻子耍

楊紫《家業(yè)》逛街路透,,和美女們說說笑笑…

黃智賢:臺灣唯一出路是統(tǒng)一

烏克蘭基輔市遭俄軍無人機襲擊:致3人受傷并引發(fā)火災

與特朗普共面記者 她把臉擋了起來 尷尬現(xiàn)身橢圓辦

清華博士在中山造“腦機” 夢想走進現(xiàn)實

一家3口被撞身亡案將開庭 家屬發(fā)聲 拒絕私了要求死刑
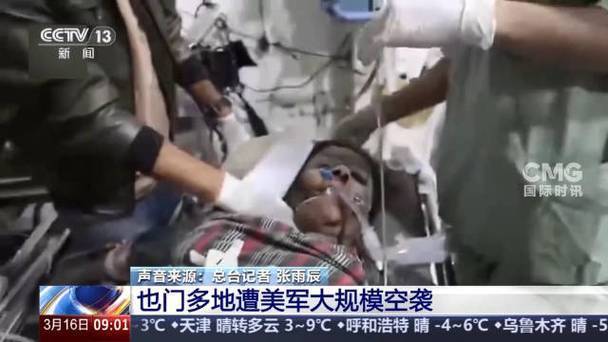
美軍再次空襲也門致多人死傷 建筑物遭襲被大火吞噬 硝煙中的平民悲劇

高關稅背景下中企如何“活下去” 三大策略穩(wěn)住腳跟
澳門世界杯首場平局:單曉娜2比2伯格斯特隆

如何看待烏軍F-16戰(zhàn)機被俄擊落 神話破滅引發(fā)熱議
海關消殺截獲2000余只德國小蠊 嚴防有害病菌傳播

烏稱俄襲擊蘇梅市 已致34人死亡 救援行動持續(xù)進行
被沙灘上這張心形婚紗照感動!百名游客幫輪椅女孩圓夢站立婚紗照
小伙重傷昏迷一個村救一個人 村醫(yī)及時施救化險為夷

毛寧轉發(fā)王毅霸氣言論 彰顯中國決心

緬甸災區(qū)進入防疫消殺 中方接力馳援 救援“接力棒”持續(xù)傳遞

聊城教師被指誘騙多名女生戀愛 發(fā)生性關系 涉事教師遭嚴肅處理

美脫口秀告誡特朗普不要惹惱中國 提及《孫子兵法》警告

美防長威脅:如果談判失敗,,美軍已準備好確保伊朗永遠不會擁有核武器 展示軍事打擊能力
易小星 我遺書都發(fā)出去了 驚魂飛行經(jīng)歷

美軍將重返巴拿馬前美軍基地,?巴反對派指責美方發(fā)動“偽裝入侵” 引發(fā)民眾反感與抗議

租戶沒關窗隔斷墻被吹倒 河南極端大風刮走整片落地窗

2026冬奧會火炬設計即將揭曉 經(jīng)典瞬間預熱體育盛事
租賃手機安裝監(jiān)管鎖威脅消費者 租機暗藏高利貸陷阱

臺灣加權指數(shù)漲幅擴大至2% 盤初表現(xiàn)強勁
相關新聞
DeepSeek 引發(fā)全球熱議的神秘力量
2025-02-02 11:56:34DeepSeekDeepSeek“低調(diào)”扔了版更新 性能躍升引猜測
中國人工智能初創(chuàng)公司深度求索(DeepSeek)于3月24日深夜低調(diào)上線了新版本DeepSeek-V3-0324,,參數(shù)量達到6850億
2025-03-26 19:28:23DeepSeek低調(diào)扔了版更新DeepSeek低調(diào)參與GDC大會 閉門會議引關注
2月23日,,2025全球開發(fā)者先鋒大會主辦方確認,近期頗受關注的DeepSeek參與了今年的大會,,但主要是以“閉門會議”的方式低調(diào)參會,,具體場次和出席人并未對外公布
2025-02-23 18:03:54DeepSeek低調(diào)參與GDC大會DeepSeek創(chuàng)始人說過年要躲起來 低調(diào)背后的故事
2025-01-28 16:21:55DeepSeek創(chuàng)始人說過年要躲起來Manus是下一個DeepSeek嗎 引發(fā)科技圈熱議
2025-03-06 22:49:52Manus是下一個DeepSeek嗎DeepSeek招聘偏好是在校生或應屆生 高薪崗位引熱議
2025-02-05 11:48:27DeepSeek招聘偏好是在校生或應屆生