AI魔改是創(chuàng)作自由還是侵權(quán)行為 版權(quán)爭議不斷(3)

網(wǎng)絡爬蟲技術(shù)的應用不是中立的。網(wǎng)站通常會采取諸如運用Robots協(xié)議,、設置驗證碼等措施來限制網(wǎng)絡爬蟲的訪問權(quán)限,。利用網(wǎng)絡爬蟲技術(shù)從互聯(lián)網(wǎng)上爬取海量內(nèi)容用于訓練生成式人工智能的行為是否構(gòu)成侵權(quán),不能一概而論,,需要具體考量以下因素:被爬取的內(nèi)容是否屬于開放數(shù)據(jù),,針對非開放數(shù)據(jù)的爬取行為才會構(gòu)成侵權(quán);使用的目的是否合法,,使用的目的如果是為了實質(zhì)性替代被爬蟲經(jīng)營者提供的部分產(chǎn)品內(nèi)容或服務則構(gòu)成侵權(quán),;爬取行為是否對權(quán)利人造成損害,有損害才有侵權(quán),。
專家一致認為,,當AI成為“創(chuàng)作者”,關(guān)于版權(quán)邊界的共識應該是:創(chuàng)新不能踐踏原創(chuàng)的土壤,,技術(shù)中立更不意味著責任真空,。唯有守住這條底線,,AI才能真正成為藝術(shù)進化的伙伴,而非埋葬創(chuàng)意的鏟子,。
(責任編輯:張小花 TT1000)
關(guān)閉

陳妍希工作室回應與帥哥聚餐 正常工作交流
陳妍希工作室回應與帥哥聚餐2025-04-26 16:51:29

乘客投訴高鐵車窗貼紙影響乘坐體驗 特色車廂引爭議
乘客投訴高鐵車窗貼紙影響乘坐體驗2025-04-26 16:50:55

牛彈琴:美國近期表態(tài)讓人哭笑不得 談判真假成謎
牛彈琴,美國近期表態(tài)讓人哭笑不得2025-04-26 16:49:37

加拿大養(yǎng)蜂企業(yè)開拓其他市場 應對美國關(guān)稅挑戰(zhàn)
加拿大養(yǎng)蜂企業(yè)開拓其他市場2025-04-26 16:36:44

文在寅批尹錫悅政府 譴責國家倒退
文在寅批尹錫悅政府2025-04-26 16:18:50

若開戰(zhàn)巴基斯坦會如何使用殲-10CE 空戰(zhàn)勝負手的關(guān)鍵
若開戰(zhàn)巴基斯坦會如何使用殲-10CE2025-04-26 12:08:14

克里米亞終姓俄,?烏能否改寫劇本 大國博弈下的領(lǐng)土之爭
克里米亞終姓俄,烏能否改寫劇本2025-04-26 13:31:56
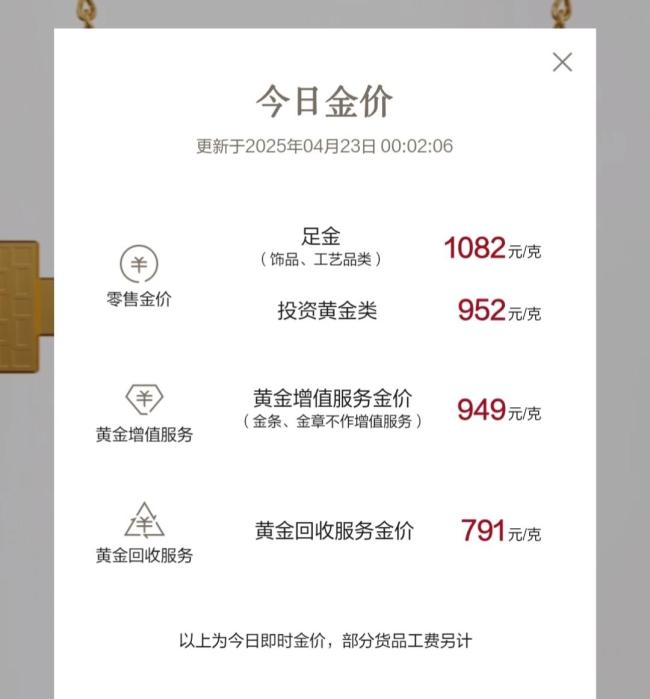
多個品牌足金飾品價微漲后下跌 金價波動引關(guān)注
多個品牌足金飾品價微漲后下跌2025-04-26 16:18:31

泰總理高燒入院畫面曝光 丈夫發(fā)文 總理病情受關(guān)注
泰總理高燒入院畫面曝光丈夫發(fā)文2025-04-26 16:47:56
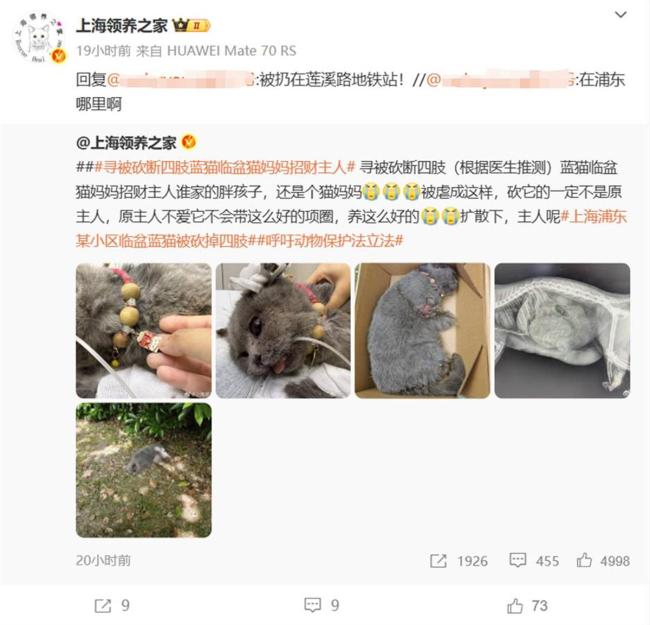
警方回應懷孕小貓被砍斷四肢 事件正調(diào)查中
警方回應懷孕小貓被砍斷四肢2025-04-26 16:36:26

天主教教皇方濟各葬禮 樸素告別引發(fā)全球關(guān)注
天主教教皇方濟各葬禮2025-04-26 16:45:15

特朗普稱印巴會自行找到解決辦法 緊張局勢待緩解
特朗普稱印巴會自行找到解決辦法2025-04-26 16:26:18

廣廈男籃傷病對沖擊季后賽有何影響 主力鋒線傷退雪上加霜
廣廈男籃傷病對沖擊季后賽有何影響2025-04-26 16:45:39

韓國瑜將參加 五萬人潮反綠大集結(jié)
藍營4·26上凱道抗議韓國瑜將參加2025-04-26 12:06:23

印巴真會爆發(fā)全面戰(zhàn)爭嗎 緊張局勢引發(fā)全球關(guān)注
印巴真會爆發(fā)全面戰(zhàn)爭嗎2025-04-26 15:52:53
美財長稱美元仍將是世界儲備貨幣 盡管開局不利
美財長稱美元仍將是世界儲備貨幣2025-04-26 12:06:49

美服裝98%靠進口 未來價格恐上漲65% 關(guān)稅沖擊加劇開支壓力
美服裝98%靠進口未來價格恐上漲65%2025-04-26 12:09:48

耿爽怒斥美方肆無忌憚愈演愈烈 違反國際義務
耿爽怒斥美方肆無忌憚愈演愈烈2025-04-26 08:55:59

特朗普梵蒂岡之行的真正目的 權(quán)力暗戰(zhàn)與地緣博弈
特朗普梵蒂岡之行的真正目的2025-04-26 16:48:14

特朗普政府內(nèi)部陷入“大亂斗” 三重危機圍剿白宮
特朗普政府內(nèi)部陷入大亂斗2025-04-26 09:16:55
乘客投訴高鐵車窗貼紙影響乘坐體驗 特色車廂引爭議
乘客投訴高鐵車窗貼紙影響乘坐體驗2025-04-26 16:50:55

小學生養(yǎng)蠶 附近桑樹被薅禿 家長“薅禿”樹木引熱議
小學生養(yǎng)蠶附近桑樹被薅禿2025-04-26 16:46:34

國民黨臺北市黨部主委無保請回遭撤 假聯(lián)署案再掀波瀾
國民黨臺北市黨部主委無保請回遭撤2025-04-26 16:45:45

百億補貼商家承擔50%?京東外賣回應 惡意造謠澄清
百億補貼商家承擔50%,京東外賣回應2025-04-26 16:49:19

航母山東艦下水8周年 馳騁深藍
航母山東艦下水8周年2025-04-26 16:44:48

太原溺水“美人魚”家屬發(fā)聲 表演者仍在重癥監(jiān)護觀察
太原溺水美人魚家屬發(fā)聲2025-04-26 16:49:01

評論員:澤連斯基只剩死磕一條路 俄軍奇襲分割烏軍
評論員,澤連斯基只剩死磕一條路2025-04-26 09:19:37

霸氣航母和嗩吶bgm絕配 致敬逐夢深藍
霸氣航母和嗩吶bgm絕配2025-04-26 16:49:28

俄稱擊落烏無人機 烏摧毀俄武器裝備 前線戰(zhàn)斗持續(xù)升級
俄稱擊落烏無人機烏摧毀俄武器裝備2025-04-26 08:55:26

東風著陸場各項準備就緒 迎接神舟十九號回家
東風著陸場各項準備就緒2025-04-26 16:16:33

文在寅被起訴背后哪些細節(jié)值得關(guān)注 政黨惡斗與大位爭奪
文在寅被起訴背后哪些細節(jié)值得關(guān)注2025-04-26 10:04:34

消費品以舊換新將乘勢而上加力擴圍 促消費活動加碼
消費品以舊換新將乘勢而上加力擴圍2025-04-26 16:38:08

香港排隊等候時吸煙將罰3000港元 控煙新規(guī)即將實施
香港排隊等候時吸煙將罰3000港元2025-04-26 16:47:02
陳妍希工作室回應與帥哥聚餐 正常工作交流
陳妍希工作室回應與帥哥聚餐2025-04-26 16:51:29
牛彈琴:美國近期表態(tài)讓人哭笑不得 談判真假成謎
牛彈琴,美國近期表態(tài)讓人哭笑不得2025-04-26 16:49:37
相關(guān)新聞
張凱麗:AI還是要為人所用,,反對魔改經(jīng)典影視劇
2025-03-08 18:41:24張凱麗AI魔改國產(chǎn)老劇是創(chuàng)意還是惡搞 引發(fā)版權(quán)與倫理爭議
2024-12-11 12:09:40AI魔改國產(chǎn)老劇是創(chuàng)意還是惡搞AI“魔改”影視劇引發(fā)爭議 經(jīng)典IP遭褻瀆
2024-12-11 18:18:20AI魔改影視劇引發(fā)爭議廣電總局出手管理AI“魔改”視頻 規(guī)范創(chuàng)作邊界
2024-12-10 07:35:32廣電總局出手管理AI魔改視頻曹操舉機關(guān)槍?AI“魔改”邊界在哪 創(chuàng)意與惡搞之爭
2024-12-09 22:31:02曹操舉機關(guān)槍AI魔改邊界在哪廣電總局出手管理AI魔改視頻 規(guī)范二次創(chuàng)作邊界
2024-12-10 07:30:28廣電總局出手管理AI魔改視頻