OpenAI深夜發(fā)布首個文生視頻模型Sora,,現(xiàn)實將被徹底顛覆

2月16日凌晨,OpenAI再次扔出一枚深水炸彈,發(fā)布了首個文生視頻模型Sora。據(jù)介紹,Sora可以直接輸出長達60秒的視頻,,并且包含高度細致的背景、復雜的多角度鏡頭,,以及富有情感的多個角色,。
目前官網(wǎng)上已經更新了48個視頻demo,在這些demo中,,Sora不僅能準確呈現(xiàn)細節(jié),,還能理解物體在物理世界中的存在,并生成具有豐富情感的角色,。該模型還可以根據(jù)提示,、靜止圖像甚至填補現(xiàn)有視頻中的缺失幀來生成視頻。
例如一個Prompt(大語言模型中的提示詞)的描述是:在東京街頭,,一位時髦的女士穿梭在充滿溫暖霓虹燈光和動感城市標志的街道上,。
在Sora生成的視頻里,女士身著黑色皮衣,、紅色裙子在霓虹街頭行走,,不僅主體連貫穩(wěn)定,還有多鏡頭,,包括從大街景慢慢切入到對女士的臉部表情的特寫,,以及潮濕的街道地面反射霓虹燈的光影效果。
另一個Prompt則是,,一只貓試圖叫醒熟睡的主人,,要求吃早餐,主人試圖忽略這只貓,,但貓嘗試了新招,,最終主人從枕頭下拿出藏起來的零食,讓貓自己再多待一會兒,。在這個AI生成視頻里,,貓甚至都學會了踩奶,,對主人鼻頭的觸碰甚至都是輕輕的,接近物理世界里貓的真實反應,。
OpenAI表示,,他們正在教AI理解和模擬運動中的物理世界,目標是訓練模型來幫助人們解決需要現(xiàn)實世界交互的問題,。
隨后OpenAI解釋了Sora的工作原理,,Sora是一個擴散模型,它從類似于靜態(tài)噪聲的視頻開始,,通過多個步驟逐漸去除噪聲,,視頻也從最初的隨機像素轉化為清晰的圖像場景。Sora使用了Transformer架構,,有極強的擴展性,。
視頻和圖像是被稱為“補丁”的較小數(shù)據(jù)單位集合,每個“補丁”都類似于GPT中的一個標記(Token),,通過統(tǒng)一的數(shù)據(jù)表達方式,,可以在更廣泛的視覺數(shù)據(jù)上訓練和擴散變化,包括不同的時間,、分辨率和縱橫比,。
Sora是基于過去對DALL·E和GPT的研究基礎構建,利用DALL·E 3的重述提示詞技術,,為視覺模型訓練數(shù)據(jù)生成高描述性的標注,,因此模型能更好的遵循文本指令。
一位YouTube博主Paddy Galloway發(fā)表了對Sora的感想,,他表示內容創(chuàng)作行業(yè)已經永遠的改變了,,并且毫不夸張?!拔疫M入YouTube世界已經15年時間,,但OpenAI剛剛的展示讓我無言…動畫師/3D藝術家們有麻煩了,素材網(wǎng)站將變得無關緊要,,任何人都可以無壁壘獲得難以置信的產品,,內容背后的‘想法’和故事將變得更加重要?!?/p>
但Sora模型當前也存在弱點,。OpenAI稱它可能難以準確模擬復雜場景的物理原理,并且可能無法理解因果關系,。例如,一個人可能咬了一口餅干后,,餅干會沒有咬痕,,玻璃破碎的物理過程可能也無法被準確呈現(xiàn),。

雨天路滑貨車超車后失控側翻 西瓜遍地險成隱患

轎車突發(fā)自燃 公交司機幫忙滅火 見義勇為獲贊

為什么得物越來越不受歡迎了?
為什么得物越來越不受歡迎了,?

詹雯婷勝訴 網(wǎng)絡謠言再引熱議

交管12123 APP將升級優(yōu)化 打造便民服務新體驗
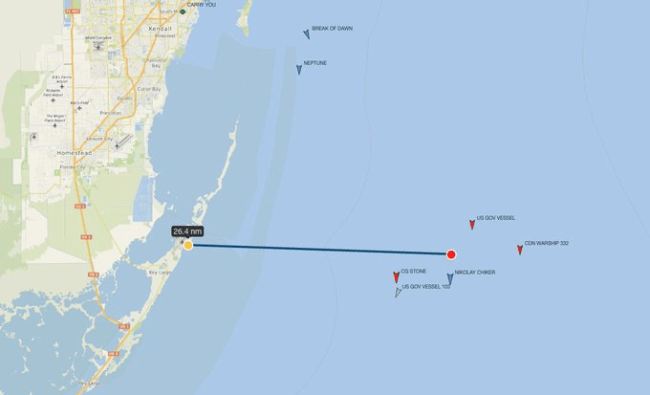
俄護衛(wèi)艦核潛艇抵近佛羅里達,,美軍緊密監(jiān)視

美國解禁烏克蘭“亞速營”使用美制武器,,俄方回應
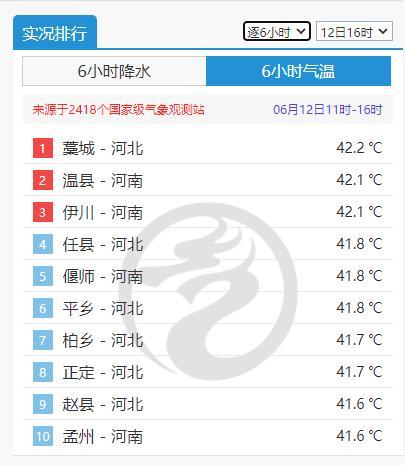
山河三省霸榜全國高溫榜 多地地表溫度超60℃

1周3國,澤連斯基密集外訪要軍援,,求西方盟友助烏加強防空

俄醉酒男子從9樓墜落竟安然無恙 奇跡生還引熱議

現(xiàn)在的米萊,,超級有意思
雨天路滑貨車超車后失控側翻 西瓜遍地險成隱患
轎車突發(fā)自燃 公交司機幫忙滅火 見義勇為獲贊

俄海軍編隊訪古巴為什么讓西方緊張?

三項罪名指控均成立,!拜登之子被判有罪轟動美國,判決將在大選前出爐

建議大家購買飲料別加冰 健康風險需警惕

G7在質疑聲中舉行峰會,英媒:成員國領導人大都“心情沮喪”

權力的游戲,?歐盟委員會主席選舉暗藏激烈博弈
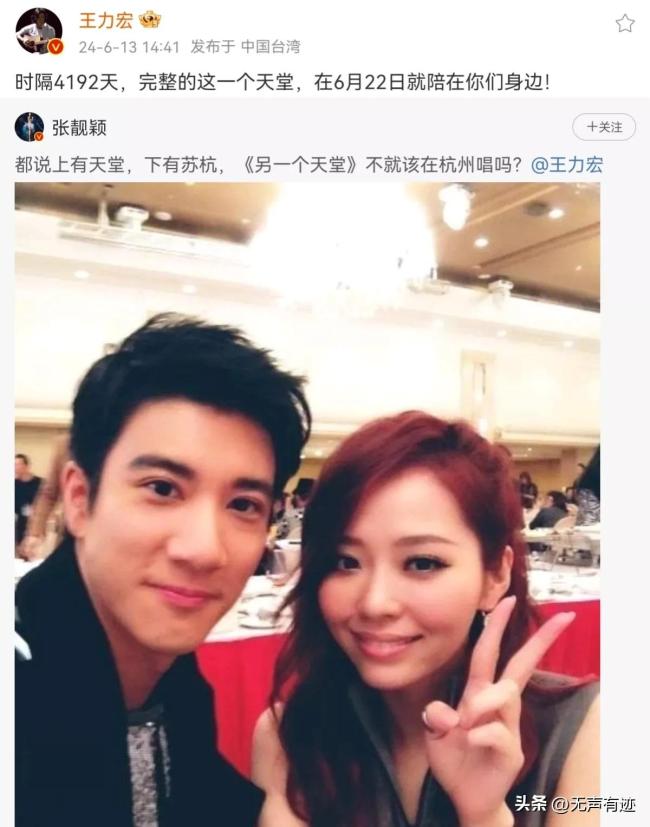
張靚穎嘉賓 王力宏攜手獻唱:土木建筑學子畢業(yè)在即

真主黨高級指揮官被殺后,,以色列北部遭160枚火??箭彈攻擊

北約秘書長:匈牙利同意不會阻止北約援助烏克蘭,但也不會參與其中

墨雨云間男主吃燒烤蘸醋 劇中人設引熱議

連任印度外長,,蘇杰生緊盯中印邊境!

安理會通過加沙停火決議,!哈馬斯準備就細節(jié)展開談判,,以色列面臨美國持續(xù)施壓

“環(huán)太平洋2024”軍演,美國海軍為什么要擊沉4萬噸級準航母,?
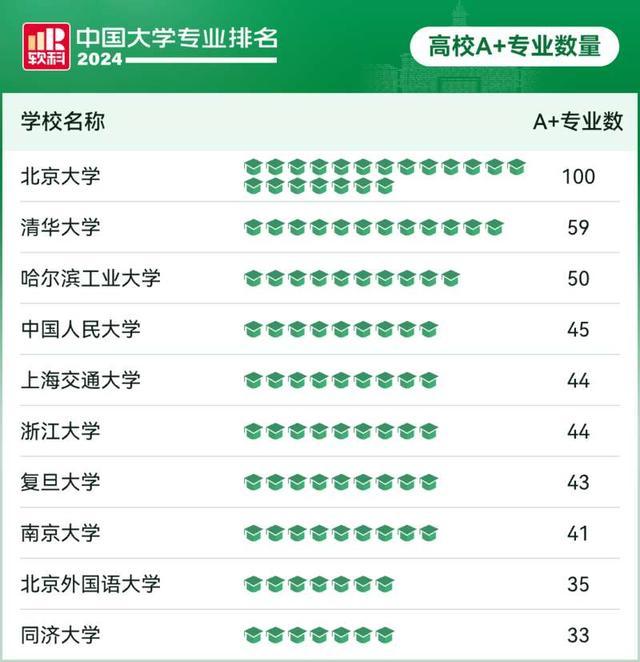
軟科中國大學專業(yè)排名2024 北大清華哈工大領跑A+專業(yè)榜

起底婚介公司忽悠套路 消費者頻遭"甜蜜陷阱

俄軍通報:核潛艇在美國本土附近進行打擊演習

以軍行動持續(xù) 加沙地帶多地發(fā)生激烈戰(zhàn)斗
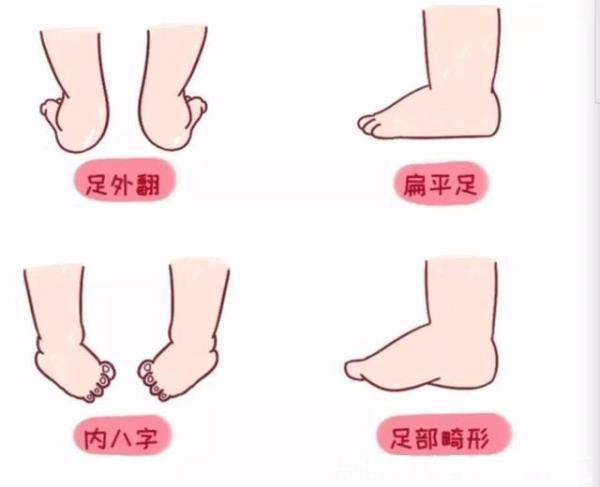
“踩屎感”拖鞋,可能不利腳部健康正在毀掉你的腳……
歌手改賽制應對爭議:斷眉退出引發(fā)變革

阿根廷計劃援烏5架“超軍旗”,,烏克蘭會嫌棄嗎,?
金碩珍被親了,!終于等到金碩珍退伍BTS退伍完成

安徽一挖機師傅清理河道挖到揚子鱷 多地接力搜尋鱷魚蹤跡
相關新聞
新模型Vidu直逼Sora,生數(shù)科技:還說“中國sora”就太沒想象力了 國產AI視頻新飛躍
4月27日,,中關村論壇未來人工智能先鋒論壇舉行期間,,生數(shù)科技攜手清華大學宣布了一個重要成果:中國首個長時長、高一致性,、高動態(tài)性視頻大模型Vidu正式面世
2024-04-28 18:58:48新模型Vidu直逼SoraOpenAI發(fā)布全新生成式AI模型GPT-4o 交互革新,,實時多模態(tài)引熱議
5月14日,OpenAI在春季發(fā)布會上揭曉了其最新的旗艦AI模型——GPT-4o,,這一模型以“全知全能”為目標,,實現(xiàn)了實時的語音、文本,、圖像交互功能
2024-05-15 09:10:07OpenAI發(fā)布全新生成式AI模型GPT-4oOpenAI或將推出下一代GPT模型 超級智能新紀元
2024-05-22 09:04:45OpenAI或將推出下一代GPT模型OpenAI推出更快更便宜AI模型 GPT-4o引領人機交互新時代
2024-05-14 09:15:31OpenAI推出更快更便宜AI模型OpenAI新模型:圖文音頻全搞定,GPT-4o引領交互新時代
在周二凌晨1點的春季發(fā)布會上,,OpenAI繼“文生視頻模型”Sora后再次為市場帶來新驚喜
2024-05-14 09:07:05OpenAI新模型:圖文音頻全搞定OpenAI新模型:絲滑如真人,,GPT-4o引領交互新時代
5月14日深夜,美國OpenAI公司舉辦線上“春季更新”活動,,揭曉兩大核心內容:發(fā)布最新旗艦模型GPT-4o及在ChatGPT服務中增添多項免費功能
2024-05-14 07:49:16OpenAI新模型:絲滑如真人








