黃仁勛最新2萬字演講實錄:機器人時代已經(jīng)到來

黃仁勛:機器人時代已經(jīng)到來
騰訊科技訊 6月2日,英偉達聯(lián)合創(chuàng)始人兼首席執(zhí)行官黃仁勛在Computex 2024(2024臺北國際電腦展)上發(fā)表主題演講,分享了人工智能時代如何助推全球新產(chǎn)業(yè)革命,。
以下是騰訊科技整理的兩小時演講全文實錄:
尊敬的各位來賓,,我非常榮幸能再次站在這里,。首先,,我要感謝臺灣大學為我們提供這個體育館作為舉辦活動的場所。上一次我來到這里,,是我從臺灣大學獲得學位的時候,。今天,我們即將探討的內容很多,,所以我必須加快步伐,,以快速而清晰的方式傳達信息。我們有很多話題要聊,,我有許多激動人心的故事要與大家分享,。
我很高興能夠來到中國臺灣,這里有我們很多合作伙伴,。事實上,,這里不僅是英偉達發(fā)展歷程中不可或缺的一部分,,更是我們與合作伙伴共同將創(chuàng)新推向全球的關鍵節(jié)點。我們與許多合作伙伴共同構建了全球范圍內的人工智能基礎設施,。今天,,我想與大家探討幾個關鍵議題:

1)我們共同的工作正在取得哪些進展,以及這些進展的意義何在,?
2)生成式人工智能到底是什么,?它將如何影響我們的行業(yè),乃至每一個行業(yè),?
3)一個關于我們如何前進的藍圖,,我們將如何抓住這個令人難以置信的機遇?
接下來會發(fā)生什么,?生成式人工智能及其帶來的深遠影響,,我們的戰(zhàn)略藍圖,這些都是我們即將探討的令人振奮的主題,。我們正站在計算機行業(yè)重啟的起點上,一個由你們鑄就,、由你們創(chuàng)造的新時代即將開啟?,F(xiàn)在,你們已經(jīng)為下一段重要旅程做好了準備,。
新的計算時代正在開始
但在開始深入討論之前,,我想先強調一點:英偉達位于計算機圖形學、模擬和人工智能的交匯點上,,這構成了我們公司的靈魂,。今天,我將向大家展示的所有內容,,都是基于模擬的,。這些不僅僅是視覺效果,它們背后是數(shù)學,、科學和計算機科學的精髓,,以及令人嘆為觀止的計算機架構。沒有任何動畫是預先制作的,,一切都是我們自家團隊的杰作,。這就是英偉達的領會,我們將其全部融入了我們引以為傲的Omniverse虛擬世界中?,F(xiàn)在,,請欣賞視頻!
全球數(shù)據(jù)中心的電力消耗正在急劇上升,,同時計算成本也在不斷攀升,。我們正面臨著計算膨脹的嚴峻挑戰(zhàn),,這種情況顯然無法長期維持。數(shù)據(jù)將繼續(xù)以指數(shù)級增長,,而CPU的性能擴展卻難以像以往那樣快速,。然而,有一種更為高效的方法正在浮現(xiàn),。
近二十年來,,我們一直致力于加速計算的研究。CUDA技術增強了CPU的功能,,將那些特殊處理器能更高效完成的任務卸載并加速,。事實上,,由于CPU性能擴展的放緩甚至停滯,加速計算的優(yōu)勢愈發(fā)顯著,。我預測,,每個處理密集型的應用都將實現(xiàn)加速,,且不久的將來,每個數(shù)據(jù)中心都將實現(xiàn)全面加速。

現(xiàn)在,,選擇加速計算是明智之舉,,這已成為行業(yè)共識。想象一下,,一個應用程序需要100個時間單位來完成,。無論是100秒還是100小時,我們往往無法承受運行數(shù)天甚至數(shù)月的人工智能應用,。
在這100個時間單位中,,有1個時間單位涉及需要順序執(zhí)行的代碼,,此時單線程CPU的重要性不言而喻,。操作系統(tǒng)的控制邏輯是不可或缺的,,必須嚴格按照指令序列執(zhí)行,。然而,,還有許多算法,如計算機圖形學,、圖像處理,、物理模擬,、組合優(yōu)化、圖處理和數(shù)據(jù)庫處理,,特別是深度學習中廣泛使用的線性代數(shù),它們非常適合通過并行處理進行加速,。為了實現(xiàn)這一目標,,我們發(fā)明了一種創(chuàng)新架構,將GPU與CPU完美結合,。
專用的處理器能夠將原本耗時的任務加速至令人難以置信的速度,。由于這兩個處理器能并行工作,它們各自獨立且自主運行,。這意味著,,原本需要100個時間單位才能完成的任務,,現(xiàn)在可能僅需1個時間單位即可完成,。盡管這種加速效果聽起來令人難以置信,但今天,,我將通過一系列實例來驗證這一說法,。

這種性能提升所帶來的好處是驚人的,,加速100倍,而功率僅增加約3倍,,成本僅上升約50%,。我們在PC行業(yè)早已實踐了這種策略。在PC上添加一個價值500美元的GeForce GPU,,就能使其性能大幅提升,,同時整體價值也增加至1000美元。在數(shù)據(jù)中心,,我們也采用了同樣的方法,。一個價值十億美元的數(shù)據(jù)中心,在添加了價值5億美元的GPU后,,瞬間轉變?yōu)橐粋€強大的人工智能工廠,。今天,這種變革正在全球范圍內發(fā)生,。
節(jié)省的成本同樣令人震驚,。每投入1美元,你就能獲得高達60倍的性能提升,。加速100倍,,而功率僅增加3倍,成本僅上升1.5倍,。節(jié)省的費用是實實在在的,!

顯然,許多公司在云端處理數(shù)據(jù)上花費了數(shù)億美元。當數(shù)據(jù)得到加速處理時,,節(jié)省數(shù)億美元就變得合情合理,。為什么會這樣呢?原因很簡單,,我們在通用計算方面經(jīng)歷了長時間的效率瓶頸,。
現(xiàn)在,我們終于認識到了這一點,,并決定加速,。通過采用專用處理器,我們可以重新獲得大量之前被忽視的性能提升,,從而節(jié)省大量金錢和能源,。這就是為什么我說,你購買得越多,,節(jié)省得也越多,。
現(xiàn)在,我已經(jīng)向你們展示了這些數(shù)字,。雖然它們并非精確到小數(shù)點后幾位,,但這準確地反映了事實。這可以稱之為“CEO數(shù)學”,。CEO數(shù)學雖不追求極致的精確,,但其背后的邏輯是正確的——你購買的加速計算能力越多,節(jié)省的成本也就越多,。

350個函式庫幫助開拓新市場
加速計算帶來的結果確實非凡,,但其實現(xiàn)過程并不容易。為什么它能節(jié)省這么多錢,,但人們卻沒有更早地采用這種技術呢,?原因就在于它的實施難度太大。
沒有現(xiàn)成的軟件可以簡單地通過加速編譯器運行,,然后應用程序就能瞬間提速100倍,。這既不符合邏輯也不現(xiàn)實。如果這么容易,,那么CPU廠商早就這樣做了,。
事實上,要實現(xiàn)加速,,軟件必須進行全面重寫,。這是整個過程中最具挑戰(zhàn)性的部分。軟件需要被重新設計,、重新編碼,,以便將原本在CPU上運行的算法轉化為可以在加速器上并行運行的格式,。
這項計算機科學研究雖然困難,但我們在過去的20年里已經(jīng)取得了顯著的進展,。例如,我們推出了廣受歡迎的cuDNN深度學習庫,,它專門處理神經(jīng)網(wǎng)絡加速,。我們還為人工智能物理模擬提供了一個庫,適用于流體動力學等需要遵守物理定律的應用,。另外,,我們還有一個名為Aerial的新庫,它利用CUDA加速5G無線電技術,,使我們能夠像軟件定義互聯(lián)網(wǎng)網(wǎng)絡一樣,,用軟件定義和加速電信網(wǎng)絡。

這些加速能力不僅提升了性能,,還幫助我們將整個電信行業(yè)轉化為一種與云計算類似的計算平臺,。此外,Coolitho計算光刻平臺也是一個很好的例子,,它極大地提升了芯片制造過程中計算最密集的部分——掩模制作的效率,。臺積電等公司已經(jīng)開始使用Coolitho進行生產(chǎn),不僅顯著節(jié)省了能源,,而且大幅降低了成本,。他們的目標是通過加速技術棧,為算法的更進一步發(fā)展和制造更深更窄的晶體管所需的龐大計算能力做好準備,。
Pair of Bricks是我們引以為傲的基因測序庫,,它擁有世界領先的基因測序吞吐量。而Co OPT則是一個令人矚目的組合優(yōu)化庫,,能夠解決路線規(guī)劃,、優(yōu)化行程、旅行社問題等復雜難題,。人們普遍認為,,這些問題需要量子計算機才能解決,但我們卻通過加速計算技術,,創(chuàng)造了一個運行極快的算法,,成功打破了23項世界紀錄,至今我們仍保持著每一個主要的世界紀錄,。
Coup Quantum是我們開發(fā)的量子計算機仿真系統(tǒng),。對于想要設計量子計算機或量子算法的研究人員來說,一個可靠的模擬器是必不可少的,。在沒有實際量子計算機的情況下,,英偉達CUDA——我們稱之為世界上最快的計算機——成為了他們的首選工具,。我們提供了一個模擬器,能夠模擬量子計算機的運行,,幫助研究人員在量子計算領域取得突破,。這個模擬器已經(jīng)被全球數(shù)十萬研究人員廣泛使用,并被集成到所有領先的量子計算框架中,,為世界各地的科學超級計算機中心提供了強大的支持,。
此外,我們還推出了數(shù)據(jù)處理庫Kudieff,,專門用于加速數(shù)據(jù)處理過程,。數(shù)據(jù)處理占據(jù)了當今云支出的絕大部分,因此加速數(shù)據(jù)處理對于節(jié)省成本至關重要,。QDF是我們開發(fā)的加速工具,,能夠顯著提升世界上主要數(shù)據(jù)處理庫的性能,如Spark,、Pandas,、Polar以及NetworkX等圖處理數(shù)據(jù)庫。
這些庫是生態(tài)系統(tǒng)中的關鍵組成部分,,它們使得加速計算得以廣泛應用,。如果沒有我們精心打造的如cuDNN這樣的特定領域庫,僅憑CUDA,,全球深度學習科學家可能無法充分利用其潛力,,因為CUDA與TensorFlow、PyTorch等深度學習框架中使用的算法之間存在顯著差異,。這就像在沒有OpenGL的情況下進行計算機圖形學設計,,或是在沒有SQL的情況下進行數(shù)據(jù)處理一樣不切實際。
這些特定領域的庫是我們公司的寶藏,,我們目前擁有超過350個這樣的庫,。正是這些庫讓我們在市場中保持開放和領先。今天,,我將向你們展示更多令人振奮的例子,。
就在上周,谷歌宣布他們已經(jīng)在云端部署了QDF,,并成功加速了Pandas,。Pandas是世界上最受歡迎的數(shù)據(jù)科學庫,被全球1000萬數(shù)據(jù)科學家所使用,,每月下載量高達1.7億次,。它就像是數(shù)據(jù)科學家的Excel,是他們處理數(shù)據(jù)的得力助手,。
現(xiàn)在,,只需在谷歌的云端數(shù)據(jù)中心平臺Colab上點擊一下,,你就可以體驗到由QDF加速的Pandas帶來的強大性能。這種加速效果確實令人驚嘆,,就像你們剛剛看到的演示一樣,,它幾乎瞬間就完成了數(shù)據(jù)處理任務。

CUDA實現(xiàn)良性循環(huán)
CUDA已經(jīng)達到了一個人們所稱的臨界點,,但現(xiàn)實情況比這要好,。CUDA已經(jīng)實現(xiàn)一個良性的發(fā)展循環(huán)?;仡櫄v史和各種計算架構,、平臺的發(fā)展,,我們可以發(fā)現(xiàn)這樣的循環(huán)并不常見,。以微處理器CPU為例,它已經(jīng)存在了60年,,但其加速計算的方式在這漫長的歲月里并未發(fā)生根本性改變,。
要創(chuàng)建一個新的計算平臺往往面臨著“先有雞還是先有蛋”的困境。沒有開發(fā)者的支持,,平臺很難吸引用戶,;而沒有用戶的廣泛采用,又難以形成龐大的安裝基礎來吸引開發(fā)者,。這個困境在過去20年中一直困擾著多個計算平臺的發(fā)展,。
然而,通過持續(xù)不斷地推出特定領域的庫和加速庫,,我們成功打破了這一困境,。如今,我們已在全球擁有500萬開發(fā)者,,他們利用CUDA技術服務于從醫(yī)療保健,、金融服務到計算機行業(yè)、汽車行業(yè)等幾乎每一個主要行業(yè)和科學領域,。
隨著客戶群的不斷擴大,,OEM和云服務提供商也開始對我們的系統(tǒng)產(chǎn)生興趣,這進一步推動了更多系統(tǒng)進入市場,。這種良性循環(huán)為我們創(chuàng)造了巨大的機遇,,使我們能夠擴大規(guī)模,增加研發(fā)投入,,從而推動更多應用的加速發(fā)展,。
每一次應用的加速都意味著計算成本的顯著降低。正如我之前展示的,,100倍的加速可以帶來高達97.96%,,即接近98%的成本節(jié)省,。隨著我們將計算加速從100倍提升至200倍,再飛躍至1000倍,,計算的邊際成本持續(xù)下降,,展現(xiàn)出了令人矚目的經(jīng)濟效益。
當然,,我們相信,,通過顯著降低計算成本,市場,、開發(fā)者,、科學家和發(fā)明家將不斷發(fā)掘出消耗更多計算資源的新算法。直至某個時刻,,一種深刻的變革將悄然發(fā)生,。當計算的邊際成本變得如此低廉時,全新的計算機使用方式將應運而生,。
事實上,,這種變革正在我們眼前上演。過去十年間,,我們利用特定算法將計算的邊際成本降低了驚人的100萬倍,。如今,利用互聯(lián)網(wǎng)上的所有數(shù)據(jù)來訓練大語言模型已成為一種合乎邏輯且理所當然的選擇,,不再受到任何質疑。
這個想法——打造一臺能夠處理海量數(shù)據(jù)以自我編程的計算機——正是人工智能崛起的基石,。人工智能的崛起之所以成為可能,,完全是因為我們堅信,如果我們讓計算變得越來越便宜,,總會有人找到巨大的用途,。如今,,CUDA的成功已經(jīng)證明了這一良性循環(huán)的可行性,。
隨著安裝基礎的持續(xù)擴大和計算成本的持續(xù)降低,越來越多的開發(fā)者得以發(fā)揮他們的創(chuàng)新潛能,,提出更多的想法和解決方案,。這種創(chuàng)新力推動了市場需求的激增。現(xiàn)在我們正站在一個重大轉折點上,。然而,,在我進一步展示之前,,我想強調的是,如果不是CUDA和現(xiàn)代人工智能技術——尤其是生成式人工智能的突破,,以下我所要展示的內容將無法實現(xiàn),。
這就是“地球2號”項目——一個雄心勃勃的設想,旨在創(chuàng)建地球的數(shù)字孿生體,。我們將模擬整個地球的運行,,以預測其未來變化。通過這樣的模擬,,我們可以更好地預防災難,,更深入地理解氣候變化的影響,從而讓我們能夠更好地適應這些變化,,甚至現(xiàn)在就開始改變我們的行為和習慣,。
“地球2號”項目可能是世界上最具挑戰(zhàn)性、最雄心勃勃的項目之一,。我們每年都在這個領域取得顯著的進步,,而今年的成果尤為突出?,F(xiàn)在,,請允許我為大家展示這些令人振奮的進展。
在不遠的將來,,我們將擁有持續(xù)的天氣預報能力,,覆蓋地球上的每一平方公里。你將始終了解氣候將如何變化,,這種預測將不斷運行,,因為我們訓練了人工智能,而人工智能所需的能量又極為有限,。這將是一個令人難以置信的成就,。我希望你們會喜歡它,,而更加重要的是,,這一預測實際上是由Jensen AI做出的,而非我本人,。我設計了它,,但最終的預測由Jensen AI來呈現(xiàn)。
由于我們致力于不斷提高性能并降低成本,,研究人員在2012年發(fā)現(xiàn)了CUDA,,那是英偉達與人工智能的首次接觸。那一天對我們而言至關重要,,因為我們做出了明智的選擇,,與科學家們緊密合作,,使深度學習成為可能。AlexNet的出現(xiàn)實現(xiàn)了計算機視覺的巨大突破,。

AI超算的崛起,,起初并不被認同
但更為重要的智慧在于我們退后一步,深入理解了深度學習的本質,。它的基礎是什么,?它的長期影響是什么?它的潛力是什么,?我們意識到,,這項技術擁有巨大的潛力,能夠繼續(xù)擴展幾十年前發(fā)明和發(fā)現(xiàn)的算法,,結合更多的數(shù)據(jù),、更大的網(wǎng)絡和至關重要的計算資源,深度學習突然間能夠實現(xiàn)人類算法無法企及的任務,。
現(xiàn)在,,想象一下,如果我們進一步擴大架構,,擁有更大的網(wǎng)絡,、更多的數(shù)據(jù)和計算資源,將會發(fā)生什么,?因此,,我們致力于重新發(fā)明一切。自2012年以來,,我們改變了GPU的架構,,增加了張量核心,發(fā)明了MV-Link,,推出了cuDNN,、TensorRT、Nickel,,還收購了Mellanox,,推出了Triton推理服務器。
這些技術集成在一臺全新的計算機上,,它超越了當時所有人的想象,。沒有人預料到,沒有人提出這樣的需求,,甚至沒有人理解它的全部潛力,。事實上,我自己也不確定是否會有人會想買它,。
但在GTC大會上,,我們正式發(fā)布了這項技術。舊金山一家名叫OpenAI的初創(chuàng)公司迅速注意到了我們的成果,,并請求我們提供一臺設備,。我親自為OpenAI送去了世界上首臺人工智能超級計算機DGX。
2016年,,我們持續(xù)擴大研發(fā)規(guī)模,。從單一的人工智能超級計算機,單一的人工智能應用,,擴大到在2017年推出了更為龐大且強大的超級計算機,。隨著技術的不斷進步,世界見證了Transformer的崛起,。這一模型的出現(xiàn),,使我們能夠處理海量的數(shù)據(jù),并識別和學習在長時間跨度內連續(xù)的模式,。
如今,,我們有能力訓練這些大語言模型,以實現(xiàn)自然語言理解方面的重大突破,。但我們并未止步于此,,我們繼續(xù)前行,構建了更大的模型,。到了2022年11月,,在極為強大的人工智能超級計算機上,,我們使用數(shù)萬顆英偉達GPU進行訓練,。
僅僅5天后,OpenAI宣布ChatGPT已擁有100萬用戶,。這一驚人的增長速度,,在短短兩個月內攀升至1億用戶,創(chuàng)造了應用歷史上最快的增長記錄,。其原因十分簡單——ChatGPT的使用體驗便捷而神奇,。
用戶能夠與計算機進行自然、流暢的互動,,仿佛與真人交流一般,。無需繁瑣的指令或明確的描述,ChatGPT便能理解用戶的意圖和需求,。
ChatGPT的出現(xiàn)標志著一個劃時代的變革,,這張幻燈片恰恰捕捉到了這一關鍵轉折。請允許我為大家展示下。
直至ChatGPT的問世,,它才真正向世界揭示了生成式人工智能的無限潛能,。長久以來,人工智能的焦點主要集中在感知領域,,如自然語言理解,、計算機視覺和語音識別,這些技術致力于模擬人類的感知能力,。但ChatGPT帶來了質的飛躍,,它不僅僅局限于感知,而是首次展現(xiàn)了生成式人工智能的力量,。
它會逐個生成Token,,這些Token可以是單詞、圖像,、圖表,、表格,甚至是歌曲,、文字,、語音和視頻。Token可以代表任何具有明確意義的事物,,無論是化學物質,、蛋白質、基因,,還是之前我們提到的天氣模式,。
這種生成式人工智能的崛起意味著,我們可以學習并模擬物理現(xiàn)象,,讓人工智能模型理解并生成物理世界的各種現(xiàn)象,。我們不再局限于縮小范圍進行過濾,而是通過生成的方式探索無限可能,。
如今,,我們幾乎可以為任何有價值的事物生成Token,無論是汽車的轉向盤控制,、機械臂的關節(jié)運動,,還是我們目前能夠學習的任何知識。因此,,我們所處的已不僅僅是一個人工智能時代,,而是一個生成式人工智能引領的新紀元。
更重要的是,,這臺最初作為超級計算機出現(xiàn)的設備,,如今已經(jīng)演化為一個高效運轉的人工智能數(shù)據(jù)中心,。它不斷地產(chǎn)出,不僅生成Token,,更是一個創(chuàng)造價值的人工智能工廠,。這個人工智能工廠正在生成、創(chuàng)造和生產(chǎn)具有巨大市場潛力的新商品,。
正如19世紀末尼古拉·特斯拉(Nikola Tesla)發(fā)明了交流發(fā)電機,,為我們帶來了源源不斷的電子,英偉達的人工智能生成器也正在源源不斷地產(chǎn)生具有無限可能性的Token,。這兩者都有巨大的市場機會,,有望在每個行業(yè)掀起變革。這確實是一場新的工業(yè)革命,!
我們現(xiàn)在迎來了一個全新的工廠,,能夠為各行各業(yè)生產(chǎn)出前所未有的、極具價值的新商品,。這一方法不僅極具可擴展性,,而且完全可重復。請注意,,目前,,每天都在不斷涌現(xiàn)出各種各樣的人工智能模型,尤其是生成式人工智能模型,。如今,,每個行業(yè)都競相參與其中,這是前所未有的盛況,。
價值3萬億美元的IT行業(yè),,即將催生出能夠直接服務于100萬億美元產(chǎn)業(yè)的創(chuàng)新成果。它不再僅僅是信息存儲或數(shù)據(jù)處理的工具,,而是每個行業(yè)生成智能的引擎,。這將成為一種新型的制造業(yè),但它并非傳統(tǒng)的計算機制造業(yè),,而是利用計算機進行制造的全新模式,。這樣的變革以前從未發(fā)生過,這確實是一件令人矚目的非凡之事,。

生成式AI推動軟件全棧重塑,展示NIM云原生微服務
這開啟了計算加速的新時代,,推動了人工智能的迅猛發(fā)展,,進而催生了生成式人工智能的興起。而如今,,我們正在經(jīng)歷一場工業(yè)革命,。關于其影響,讓我們深入探討一下。
對于我們所在的行業(yè)而言,,這場變革的影響同樣深遠,。正如我之前所言,這是過去六十年來的首次,,計算的每一層都正在發(fā)生變革,。從CPU的通用計算到GPU的加速計算,每一次變革都標志著技術的飛躍,。
過去,,計算機需要遵循指令執(zhí)行操作,而現(xiàn)在,,它們更多地是處理LLM(大語言模型)和人工智能模型,。過去的計算模型主要基于檢索,幾乎每次你使用手機時,,它都會為你檢索預先存儲的文本,、圖像或視頻,并根據(jù)推薦系統(tǒng)重新組合這些內容呈現(xiàn)給你,。
但在未來,,你的計算機會盡可能多地生成內容,只檢索必要的信息,,因為生成數(shù)據(jù)在獲取信息時消耗的能量更少,。而且,生成的數(shù)據(jù)具有更高的上下文相關性,,能更準確地反映你的需求,。當你需要答案時,不再需要明確指示計算機“給我獲取那個信息”或“給我那個文件”,,只需簡單地說:“給我一個答案,。”
此外,,計算機不再僅僅是我們使用的工具,,它開始生成技能。它執(zhí)行任務,,而不再是一個生產(chǎn)軟件的行業(yè),,這在90年代初是一個顛覆性的觀念。記得嗎,?微軟提出的軟件打包理念徹底改變了PC行業(yè),。沒有打包軟件,我們的PC將失去大部分功能,。這一創(chuàng)新推動了整個行業(yè)的發(fā)展,。
現(xiàn)在我們有了新工廠,、新計算機,而在這個基礎上運行的是一種新型軟件——我們稱之為Nim(NVIDIA Inference Microservices),。在這個新工廠中運行的Nim是一個預訓練模型,,它是一個人工智能。

這個人工智能本身相當復雜,,但運行人工智能的計算堆棧更是復雜得令人難以置信,。當你使用ChatGPT這樣的模型時,其背后是龐大的軟件堆棧,。這個堆棧復雜而龐大,,因為模型擁有數(shù)十億到數(shù)萬億個參數(shù),且不僅在一臺計算機上運行,,而是在多臺計算機上協(xié)同工作,。
為了最大化效率,系統(tǒng)需要將工作負載分配給多個GPU,,進行各種并行處理,,如張量并行、管道并行,、數(shù)據(jù)并行和專家并行,。這樣的分配是為了確保工作能盡快完成,因為在一個工廠中,,吞吐量直接關系到收入,、服務質量和可服務的客戶數(shù)量。如今,,我們身處一個數(shù)據(jù)中心吞吐量利用率至關重要的時代,。
過去,雖然吞吐量被認為重要,,但并非決定性的因素,。然而,現(xiàn)在,,從啟動時間,、運行時間、利用率,、吞吐量到空閑時間等每一個參數(shù)都被精確測量,,因為數(shù)據(jù)中心已成為真正的“工廠”。在這個工廠中,,運作效率直接關聯(lián)到公司的財務表現(xiàn),。
鑒于這種復雜性,我們深知大多數(shù)公司在部署人工智能時面臨的挑戰(zhàn),。因此,,我們開發(fā)了一個集成化的人工智能容器解決方案,將人工智能封裝在易于部署和管理的盒子中,。這個盒子包含了龐大的軟件集合,,如CUDA、CUDACNN和TensorRT,,以及Triton推理服務,。它支持云原生環(huán)境,允許在Kubernetes(基于容器技術的分布式架構解決方案)環(huán)境中自動擴展,,并提供管理服務,,方便用戶監(jiān)控人工智能服務的運行狀態(tài)。
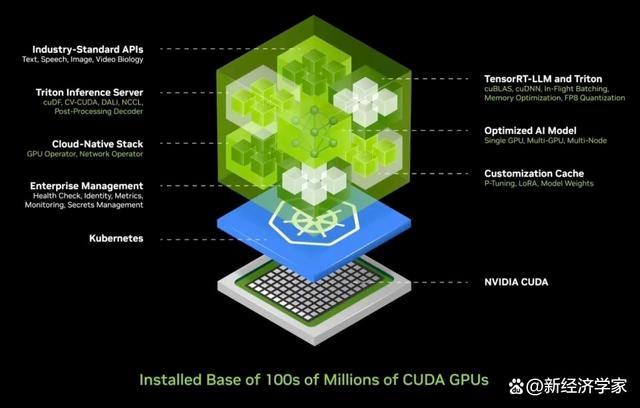
更令人振奮的是,,這個人工智能容器提供通用的,、標準的API接口,使得用戶可以直接與“盒子”進行交互,。用戶只需下載Nim,,并在支持CUDA的計算機上運行,即可輕松部署和管理人工智能服務,。如今,,CUDA已無處不在,它支持各大云服務提供商,,幾乎所有計算機制造商都提供CUDA支持,,甚至在數(shù)億臺PC中也能找到它的身影。
當你下載Nim時,,即刻擁有一個人工智能助手,,它能如與ChatGPT對話般流暢交流。現(xiàn)在,,所有的軟件都已精簡并整合在一個容器中,,原先繁瑣的400個依賴項全部集中優(yōu)化。我們對Nim進行了嚴格的測試,,每個預訓練模型都在我們的云端基礎設施上得到了全面測試,,包括Pascal、Ampere乃至最新的Hopper等不同版本的GPU,。這些版本種類繁多,,幾乎覆蓋了所有需求。
Nim的發(fā)明無疑是一項壯舉,,它是我最引以為傲的成就之一,。如今,我們有能力構建大語言模型和各種預訓練模型,,這些模型涵蓋了語言,、視覺,、圖像等多個領域,還有針對特定行業(yè)如醫(yī)療保健和數(shù)字生物學的定制版本,。

想要了解更多或試用這些版本,,只需訪問ai.nvidia.com。今天,,我們在Hugging Face上發(fā)布了完全優(yōu)化的Llama 3 Nim,,你可以立即體驗,甚至免費帶走它,。無論你選擇哪個云平臺,,都能輕松運行它。當然,,你也可以將這個容器下載到你的數(shù)據(jù)中心,,自行托管,并為你的客戶提供服務,。
我前面提到,,我們擁有覆蓋不同領域的Nim版本,包括物理學,、語義檢索,、視覺語言等,支持多種語言,。這些微服務可以輕松集成到大型應用中,,其中最具潛力的應用之一是客戶服務代理。它幾乎是每個行業(yè)的標配,,代表了價值數(shù)萬億美元的全球客戶服務市場,。
值得一提的是,護士們作為客戶服務的核心,,在零售,、快餐、金融服務,、保險等行業(yè)中發(fā)揮著重要作用,。如今,借助語言模型和人工智能技術,,數(shù)千萬的客戶服務人員得到了顯著的增強,。這些增強工具的核心,正是你所看到的Nim,。
有些被稱為推理智能體(Reasoning Agents),,它們被賦予任務后,能夠明確目標并制定計劃。有的擅長檢索信息,,有的精于搜索,,還有的可能會使用如Coop這樣的工具,或者需要學習在SAP上運行的特定語言如ABAP,,甚至執(zhí)行SQL查詢,。這些所謂的專家現(xiàn)在被組成一個高效協(xié)作的團隊,。
應用層也因此發(fā)生了變革:過去,,應用程序是由指令編寫的,而現(xiàn)在,,它們則是通過組裝人工智能團隊來構建,。雖然編寫程序需要專業(yè)技能,但幾乎每個人都知道如何分解問題并組建團隊,。因此,,我堅信,未來的每家公司都會擁有一個龐大的Nim集合,。你可以根據(jù)需要選擇專家,,將它們連接成一個團隊。
更神奇的是,,你甚至不需要弄清楚如何去連接它們,。只需給代理分配一個任務,Nim會智能地決定如何分解任務并分配給最適合的專家,。它們就像應用程序或團隊的中央領導者,,能夠協(xié)調團隊成員的工作,最終將結果呈現(xiàn)給你,。
整個過程就像人類團隊協(xié)作一樣高效,、靈活。這不僅僅是未來的趨勢,,而是即將在我們身邊成為現(xiàn)實,。這就是未來應用程序將要呈現(xiàn)的全新面貌。

PC將成為數(shù)字人主要載體
當我們談論與大型人工智能服務的交互時,,目前我們已經(jīng)可以通過文本和語音提示來實現(xiàn),。但展望未來,我們更希望以更人性化的方式——即數(shù)字人,,來進行互動,。英偉達在數(shù)字人技術領域已經(jīng)取得了顯著的進展。

數(shù)字人不僅具有成為出色交互式代理的潛力,,它們還更加吸引人,,并可能展現(xiàn)出更高的同理心。然而,,要跨越這個令人難以置信的鴻溝,,使數(shù)字人看起來和感覺更加自然,,我們仍需付出巨大的努力。這不僅是我們的愿景,,更是我們不懈追求的目標,。
在我向大家展示我們目前的成果之前,請允許我表達對中國臺灣的熱情問候,。在深入探索夜市的魅力之前,,讓我們先一同領略數(shù)字人技術的前沿動態(tài)。
這確實令人覺得不可思議,。ACE(Avatar Cloud Engine,,英偉達數(shù)字人技術)不僅能在云端高效運行,同時也兼容PC環(huán)境,。我們前瞻性地將Tensor Core GPU集成到所有RTX系列中,,這標志著人工智能GPU的時代已經(jīng)到來,我們?yōu)榇俗龊昧顺浞譁蕚洹?/p>
背后的邏輯十分清晰:要構建一個新的計算平臺,,必須先奠定堅實的基礎,。有了堅實的基礎,應用程序自然會隨之涌現(xiàn),。如果缺乏這樣的基礎,,那么應用程序便無從談起。所以,,只有當我們構建了它,,應用程序的繁榮才有可能實現(xiàn)。
因此,,我們在每一款RTX GPU中都集成了Tensor Core處理單元,,目前全球已有1億臺GeForce RTX AI PC投入使用,而且這個數(shù)字還在不斷增長,,預計將達到2億臺,。在最近的Computex展會上,我們更是推出了四款全新的人工智能筆記本電腦,。
這些設備都具備運行人工智能的能力,。未來的筆記本電腦和PC將成為人工智能的載體,它們將在后臺默默地為你提供幫助和支持,。同時,,這些PC還將運行由人工智能增強的應用程序,無論你是進行照片編輯,、寫作還是使用其他工具,,都將享受到人工智能帶來的便利和增強效果。

此外,你的PC還將能夠托管帶有人工智能的數(shù)字人類應用程序,,讓人工智能以更多樣化的方式呈現(xiàn)并在PC上得到應用,。顯然,PC將成為至關重要的人工智能平臺,。那么,,接下來我們將如何發(fā)展呢?
之前我談到了我們數(shù)據(jù)中心的擴展,,每次擴展都伴隨著新的變革,。當我們從DGX擴展到大型人工智能超級計算機時,我們實現(xiàn)了Transformer在巨大數(shù)據(jù)集上的高效訓練,。這標志著一個重大的轉變:一開始,,數(shù)據(jù)需要人類的監(jiān)督,通過人類標記來訓練人工智能,。然而,人類能夠標記的數(shù)據(jù)量是有限的?,F(xiàn)在,,隨著Transformer的發(fā)展,無監(jiān)督學習成為可能,。
如今,,Transformer能夠自行探索海量的數(shù)據(jù)、視頻和圖像,,從中學習并發(fā)現(xiàn)隱藏的模式和關系,。為了推動人工智能向更高層次發(fā)展,下一代人工智能需要根植于物理定律的理解,,但大多數(shù)人工智能系統(tǒng)缺乏對物理世界的深刻認識,。為了生成逼真的圖像、視頻,、3D圖形,,以及模擬復雜的物理現(xiàn)象,我們急需開發(fā)基于物理的人工智能,,這要求它能夠理解并應用物理定律,。
在實現(xiàn)這一目標的過程中,有兩個主要方法,。首先,,通過從視頻中學習,人工智能可以逐步積累對物理世界的認知,。其次,,利用合成數(shù)據(jù),我們可以為人工智能系統(tǒng)提供豐富且可控的學習環(huán)境。此外,,模擬數(shù)據(jù)和計算機之間的互相學習也是一種有效的策略,。這種方法類似于AlphaGo的自我對弈模式,讓兩個相同能力的實體長時間相互學習,,從而不斷提升智能水平,。因此,我們可以預見,,這種類型的人工智能將在未來逐漸嶄露頭角,。
Blackwell全面投產(chǎn),八年間算力增長1000倍
當人工智能數(shù)據(jù)通過合成方式生成,,并結合強化學習技術時,,數(shù)據(jù)生成的速率將得到顯著提升。隨著數(shù)據(jù)生成的增長,,對計算能力的需求也將相應增加,。我們即將邁入一個新時代,在這個時代中,,人工智能將能夠學習物理定律,,理解并基于物理世界的數(shù)據(jù)進行決策和行動。因此,,我們預計人工智能模型將繼續(xù)擴大,,對GPU性能的要求也將越來越高。
為滿足這一需求,,Blackwell應運而生,。這款GPU專為支持新一代人工智能設計,擁有幾項關鍵技術,。這種芯片尺寸之大在業(yè)界首屈一指,。我們采用了兩片盡可能大的芯片,通過每秒10太字節(jié)的高速鏈接,,結合世界上最先進的SerDes(高性能接口或連接技術)將它們緊密連接在一起,。進一步地,我們將兩片這樣的芯片放置在一個計算機節(jié)點上,,并通過Grace CPU進行高效協(xié)調,。
Grace CPU的用途廣泛,不僅適用于訓練場景,,還在推理和生成過程中發(fā)揮關鍵作用,,如快速檢查點和重啟。此外,,它還能存儲上下文,,讓人工智能系統(tǒng)擁有記憶,,并能理解用戶對話的上下文,這對于增強交互的連續(xù)性和流暢性至關重要,。
我們推出的第二代Transformer引擎進一步提升了人工智能的計算效率,。這款引擎能夠根據(jù)計算層的精度和范圍需求,動態(tài)調整至較低的精度,,從而在保持性能的同時降低能耗,。同時,Blackwell GPU還具備安全人工智能功能,,確保用戶能夠要求服務提供商保護其免受盜竊或篡改,。
在GPU的互聯(lián)方面,我們采用了第五代MV Link技術,,它允許我們輕松連接多個GPU,。此外,Blackwell GPU還配備了第一代可靠性和可用性引擎(Ras系統(tǒng)),,這一創(chuàng)新技術能夠測試芯片上的每一個晶體管,、觸發(fā)器、內存以及片外內存,,確保我們在現(xiàn)場就能準確判斷特定芯片是否達到了平均故障間隔時間(MTBF)的標準,。
對于大型超級計算機來說,可靠性尤為關鍵,。擁有10,000個GPU的超級計算機的平均故障間隔時間可能以小時為單位,但當GPU數(shù)量增加至100,000個時,,平均故障間隔時間將縮短至以分鐘為單位,。因此,為了確保超級計算機能夠長時間穩(wěn)定運行,,以訓練那些可能需要數(shù)個月時間的復雜模型,,我們必須通過技術創(chuàng)新來提高可靠性。而可靠性的提升不僅能夠增加系統(tǒng)的正常運行時間,,還能有效降低成本,。
最后,我們還在Blackwell GPU中集成了先進的解壓縮引擎,。在數(shù)據(jù)處理方面,,解壓縮速度至關重要。通過集成這一引擎,,我們可以從存儲中拉取數(shù)據(jù)的速度比現(xiàn)有技術快20倍,,從而極大地提升了數(shù)據(jù)處理效率。
Blackwell GPU的上述功能特性使其成為一款令人矚目的產(chǎn)品,。在之前的GTC大會上,,我曾向大家展示了處于原型狀態(tài)的Blackwell,。而現(xiàn)在,我們很高興地宣布,,這款產(chǎn)品已經(jīng)投入生產(chǎn),。

各位,這就是Blackwell,,使用了令人難以置信的技術,。這是我們的杰作,是當今世界上最復雜,、性能最高的計算機,。其中,我們特別要提到的是Grace CPU,,它承載了巨大的計算能力,。請看,這兩個Blackwell芯片,,它們緊密相連,。你注意到了嗎?這就是世界上最大的芯片,,而我們使用每秒高達A10TB的鏈接將兩片這樣的芯片融為一體,。
那么,Blackwell究竟是什么呢,?它的性能之強大,,簡直令人難以置信。請仔細觀察這些數(shù)據(jù),。在短短八年內,,我們的計算能力、浮點運算以及人工智能浮點運算能力增長了1000倍,。這速度,,幾乎超越了摩爾定律在最佳時期的增長。
Blackwell計算能力的增長簡直驚人,。而更值得一提的是,,每當我們的計算能力提高時,成本卻在不斷下降,。讓我給你們展示一下,。我們通過提升計算能力,用于訓練GPT-4模型(2萬億參數(shù)和8萬億Token)的能量下降了350倍,。
想象一下,,如果使用Pascal進行同樣的訓練,它將消耗高達1000吉瓦時的能量,。這意味著需要一個吉瓦數(shù)據(jù)中心來支持,,但世界上并不存在這樣的數(shù)據(jù)中心,。即便存在,它也需要連續(xù)運行一個月的時間,。而如果是一個100兆瓦的數(shù)據(jù)中心,,那么訓練時間將長達一年。
顯然,,沒有人愿意或能夠創(chuàng)造這樣的數(shù)據(jù)中心。這就是為什么八年前,,像ChatGPT這樣的大語言模型對我們來說還是遙不可及的夢想,。但如今,我們通過提升性能并降低能耗實現(xiàn)了這一目標,。
我們利用Blackwell將原本需要高達1000吉瓦時的能量降低到僅需3吉瓦時,,這一成就無疑是令人震驚的突破。想象一下,,使用1000個GPU,,它們所消耗的能量竟然只相當于一杯咖啡的熱量。而10,000個GPU,,更是只需短短10天左右的時間就能完成同等任務,。八年間取得的這些進步,簡直令人難以置信,。

Blackwell不僅適用于推理,,其在Token生成性能上的提升更是令人矚目。在Pascal時代,,每個Token消耗的能量高達17,000焦耳,,這大約相當于兩個燈泡運行兩天的能量。而生成一個GPT-4的Token,,幾乎需要兩個200瓦特的燈泡持續(xù)運行兩天??紤]到生成一個單詞大約需要3個Token,,這確實是一個巨大的能量消耗。
然而,,現(xiàn)在的情況已經(jīng)截然不同,。Blackwell使得生成每個Token只需消耗0.4焦耳的能量,以驚人的速度和極低的能耗進行Token生成,。這無疑是一個巨大的飛躍,。但即使如此,我們仍不滿足,。為了更大的突破,,我們必須建造更強大的機器,。
這就是我們的DGX系統(tǒng),Blackwell芯片將被嵌入其中,。這款系統(tǒng)采用空氣冷卻技術,,內部配備了8個這樣的GPU??纯催@些GPU上的散熱片,,它們的尺寸之大令人驚嘆。整個系統(tǒng)功耗約為15千瓦,,完全通過空氣冷卻實現(xiàn),。這個版本兼容X86,并已應用于我們已發(fā)貨的服務器中,。
然而,,如果你更傾向于液體冷卻技術,我們還有一個全新的系統(tǒng)——MGX,。它基于這款主板設計,,我們稱之為“模塊化”系統(tǒng)。MGX系統(tǒng)的核心在于兩塊Blackwell芯片,,每個節(jié)點都集成了四個Blackwell芯片,。它采用了液體冷卻技術,確保了高效穩(wěn)定的運行,。
整個系統(tǒng)中,,這樣的節(jié)點共有九個,共計72個GPU,,構成了一個龐大的計算集群,。這些GPU通過全新的MV鏈接技術緊密相連,形成了一個無縫的計算網(wǎng)絡,。MV鏈接交換機堪稱技術奇跡,。它是目前世界上最先進的交換機,數(shù)據(jù)傳輸速率令人咋舌,。這些交換機使得每個Blackwell芯片高效連接,,形成了一個巨大的72GPU集群。

這一集群的優(yōu)勢何在,?首先,,在GPU域中,它現(xiàn)在表現(xiàn)得就像一個單一的,、超大規(guī)模的GPU,。這個“超級GPU”擁有72個GPU的核心能力,相較于上一代的8個GPU,,性能提升了9倍,。同時,,帶寬增加了18倍,AI FLOPS(每秒浮點運算次數(shù))更是提升了45倍,,而功率僅增加了10倍,。也就是說,一個這樣的系統(tǒng)能提供100千瓦的強勁動力,,而上一代僅為10千瓦,。
當然,你還可以將更多的這些系統(tǒng)連接在一起,,形成更龐大的計算網(wǎng)絡,。但真正的奇跡在于這個MV鏈接芯片,隨著大語言模型的日益龐大,,其重要性也日益凸顯,。因為這些大語言模型已經(jīng)不適合單獨放在一個GPU或節(jié)點上運行,它們需要整個GPU機架的協(xié)同工作,。就像我剛才提到的那個新DGX系統(tǒng),,它能夠容納參數(shù)達到數(shù)十萬億的大語言模型。
MV鏈接交換機本身就是一個技術奇跡,,擁有500億個晶體管,,74個端口,每個端口的數(shù)據(jù)速率高達400GB,。但更重要的是,,交換機內部還集成了數(shù)學運算功能,可以直接進行歸約操作,,這在深度學習中具有極其重要的意義,。這就是現(xiàn)在的DGX系統(tǒng)的全新面貌。
許多人對我們表示好奇,。他們提出疑問,,對英偉達的業(yè)務范疇存在誤解。人們疑惑,,英偉達怎么可能僅憑制造GPU就變得如此龐大,。因此,很多人形成了這樣一種印象:GPU就應該是某種特定的樣子,。
然而,現(xiàn)在我要展示給你們的是,,這確實是一個GPU,,但它并非你們想象中的那種。這是世界上最先進的GPU之一,,但它主要用于游戲領域,。但我們都清楚,,GPU的真正力量遠不止于此。
各位,,請看這個,,這才是GPU的真正形態(tài)。這是DGX GPU,,專為深度學習而設計,。這個GPU的背面連接著MV鏈接主干,這個主干由5000條線組成,,長達3公里,。這些線,就是MV鏈接主干,,它們連接了70個GPU,,形成一個強大的計算網(wǎng)絡。這是一個電子機械奇跡,,其中的收發(fā)器讓我們能夠在銅線上驅動信號貫穿整個長度,。
因此,這個MV鏈接交換機通過MV鏈接主干在銅線上傳輸數(shù)據(jù),,使我們能夠在單個機架中節(jié)省20千瓦的電力,,而這20千瓦現(xiàn)在可以完全用于數(shù)據(jù)處理,這的確是一項令人難以置信的成就,。這就是MV鏈接主干的力量,。

為生成式AI推以太網(wǎng)
但這還不足以滿足需求,特別是對于大型人工智能工廠來說更是如此,,那么我們還有另一種解決方案,。我們必須使用高速網(wǎng)絡將這些人工智能工廠連接起來。我們有兩種網(wǎng)絡選擇:InfiniBand和以太網(wǎng),。其中,,InfiniBand已經(jīng)在全球各地的超級計算和人工智能工廠中廣泛使用,并且增長迅速,。然而,,并非每個數(shù)據(jù)中心都能直接使用InfiniBand,因為他們在以太網(wǎng)生態(tài)系統(tǒng)上進行了大量投資,,而且管理InfiniBand交換機和網(wǎng)絡確實需要一定的專業(yè)知識和技術,。
因此,我們的解決方案是將InfiniBand的性能帶到以太網(wǎng)架構中,,這并非易事,。原因在于,每個節(jié)點、每臺計算機通常與互聯(lián)網(wǎng)上的不同用戶相連,,但大多數(shù)通信實際上發(fā)生在數(shù)據(jù)中心內部,,即數(shù)據(jù)中心與互聯(lián)網(wǎng)另一端用戶之間的數(shù)據(jù)傳輸。然而,,在人工智能工廠的深度學習場景下,,GPU并不是與互聯(lián)網(wǎng)上的用戶進行通信,而是彼此之間進行頻繁的,、密集的數(shù)據(jù)交換,。
它們相互通信是因為它們都在收集部分結果。然后它們必須將這些部分結果進行規(guī)約(reduce)并重新分配(redistribute),。這種通信模式的特點是高度突發(fā)性的流量,。重要的不是平均吞吐量,而是最后一個到達的數(shù)據(jù),,因為如果你正在從所有人那里收集部分結果,,并且我試圖接收你所有的部分結果,如果最后一個數(shù)據(jù)包晚到了,,那么整個操作就會延遲,。對于人工智能工廠而言,延遲是一個至關重要的問題,。
所以,,我們關注的焦點并非平均吞吐量,而是確保最后一個數(shù)據(jù)包能夠準時,、無誤地抵達,。然而,傳統(tǒng)的以太網(wǎng)并未針對這種高度同步化,、低延遲的需求進行優(yōu)化,。為了滿足這一需求,我們創(chuàng)造性地設計了一個端到端的架構,,使NIC(網(wǎng)絡接口卡)和交換機能夠通信,。為了實現(xiàn)這一目標,我們采用了四種關鍵技術:
第一,,英偉達擁有業(yè)界領先的RDMA(遠程直接內存訪問)技術?,F(xiàn)在,我們有了以太網(wǎng)網(wǎng)絡級別的RDMA,,它的表現(xiàn)非常出色,。
第二,我們引入了擁塞控制機制,。交換機具備實時遙測功能,,能夠迅速識別并響應網(wǎng)絡中的擁塞情況。當GPU或NIC發(fā)送的數(shù)據(jù)量過大時,交換機會立即發(fā)出信號,,告知它們減緩發(fā)送速率,從而有效避免網(wǎng)絡熱點的產(chǎn)生,。
第三,,我們采用了自適應路由技術。傳統(tǒng)以太網(wǎng)按固定順序傳輸數(shù)據(jù),,但在我們的架構中,,我們能夠根據(jù)實時網(wǎng)絡狀況進行靈活調整。當發(fā)現(xiàn)擁塞或某些端口空閑時,,我們可以將數(shù)據(jù)包發(fā)送到這些空閑端口,,再由另一端的Bluefield設備重新排序,確保數(shù)據(jù)按正確順序返回,。這種自適應路由技術極大地提高了網(wǎng)絡的靈活性和效率,。
第四,我們實施了噪聲隔離技術,。在數(shù)據(jù)中心中,,多個模型同時訓練產(chǎn)生的噪聲和流量可能會相互干擾,并導致抖動,。我們的噪聲隔離技術能夠有效地隔離這些噪聲,,確保關鍵數(shù)據(jù)包的傳輸不受影響。
通過采用這些技術,,我們成功地為人工智能工廠提供了高性能,、低延遲的網(wǎng)絡解決方案。在價值高達數(shù)十億美元的數(shù)據(jù)中心中,,如果網(wǎng)絡利用率提升40%而訓練時間縮短20%,,這實際上意味著價值50億美元的數(shù)據(jù)中心在性能上等同于一個60億美元的數(shù)據(jù)中心,揭示了網(wǎng)絡性能對整體成本效益的顯著影響,。
幸運的是,,帶有Spectrum X的以太網(wǎng)技術正是我們實現(xiàn)這一目標的關鍵,它大大提高了網(wǎng)絡性能,,使得網(wǎng)絡成本相對于整個數(shù)據(jù)中心而言幾乎可以忽略不計,。這無疑是我們在網(wǎng)絡技術領域取得的一大成就。
我們擁有一系列強大的以太網(wǎng)產(chǎn)品線,,其中最引人注目的是Spectrum X800,。這款設備以每秒51.2 TB的速度和256路徑(radix)的支持能力,為成千上萬的GPU提供了高效的網(wǎng)絡連接,。接下來,,我們計劃一年后推出X800 Ultra,它將支持高達512路徑的512 radix,進一步提升了網(wǎng)絡容量和性能,。而X 1600則是為更大規(guī)模的數(shù)據(jù)中心設計的,,能夠滿足數(shù)百萬個GPU的通信需求。

隨著技術的不斷進步,,數(shù)百萬個GPU的數(shù)據(jù)中心時代已經(jīng)指日可待,。這一趨勢的背后有著深刻的原因。一方面,,我們渴望訓練更大,、更復雜的模型;但更重要的是,,未來的互聯(lián)網(wǎng)和計算機交互將越來越多地依賴于云端的生成式人工智能,。這些人工智能將與我們一起工作、互動,,生成視頻,、圖像、文本甚至數(shù)字人,。因此,,我們與計算機的每一次交互幾乎都離不開生成式人工智能的參與。并且總是有一個生成式人工智能與之相連,,其中一些在本地運行,,一些在你的設備上運行,很多可能在云端運行,。
這些生成式人工智能不僅具備強大的推理能力,,還能對答案進行迭代優(yōu)化,以提高答案的質量,。這意味著我們未來將產(chǎn)生海量的數(shù)據(jù)生成需求,。今晚,我們共同見證了這一技術革新的力量,。
Blackwell,,作為NVIDIA平臺的第一代產(chǎn)品,自推出以來便備受矚目,。如今,,全球范圍內都迎來了生成式人工智能的時代,這是一個全新的工業(yè)革命的開端,,每個角落都在意識到人工智能工廠的重要性,。我們深感榮幸,獲得了來自各行各業(yè)的廣泛支持,,包括每一家OEM(原始設備制造商),、電腦制造商,、CSP(云服務提供商)、GPU云,、主權云以及電信公司等,。
Blackwell的成功、廣泛的采用以及行業(yè)對其的熱情都達到了前所未有的高度,,這讓我們深感欣慰,,并在此向大家表示衷心的感謝。然而,,我們的腳步不會因此而停歇。在這個飛速發(fā)展的時代,,我們將繼續(xù)努力提升產(chǎn)品性能,,降低培訓和推理的成本,同時不斷擴展人工智能的能力,,使每一家企業(yè)都能從中受益,。我們堅信,隨著性能的提升,,成本將進一步降低,。而Hopper平臺,無疑可能是歷史上最成功的數(shù)據(jù)中心處理器,。

Blackwell Ultra將于明年發(fā)布,,下一代平臺名為Rubin
這確實是一個震撼人心的成功故事。Blackwell平臺的誕生,,正如大家所見,,并非單一組件的堆砌,而是一個綜合了CPU,、GPU,、NVLink、NICK(特定技術組件)以及MVLink交換機等多個元素的完整系統(tǒng),。我們致力于通過每代產(chǎn)品使用大型,、超高速的交換機將所有GPU緊密連接,形成一個龐大且高效的計算域,。
我們將整個平臺集成到人工智能工廠中,,但更為關鍵的是,我們將這一平臺以模塊化的形式提供給全球客戶,。這樣做的初衷在于,,我們期望每一位合作伙伴都能根據(jù)自身的需求,創(chuàng)造出獨特且富有創(chuàng)新性的配置,,以適應不同風格的數(shù)據(jù)中心,、不同的客戶群體和多樣化的應用場景,。從邊緣計算到電信領域,只要系統(tǒng)保持開放,,各種創(chuàng)新都將成為可能,。
為了讓你們能夠自由創(chuàng)新,我們設計了一個一體化的平臺,,但同時又以分解的形式提供給你們,,使你們能夠輕松構建模塊化系統(tǒng)。現(xiàn)在,,Blackwell平臺已經(jīng)全面登場,。
英偉達始終堅持每年一次的更新節(jié)奏。我們的核心理念非常明確:1)構建覆蓋整個數(shù)據(jù)中心規(guī)模的解決方案,;2)將這些解決方案分解為各個部件,,以每年一次的頻率向全球客戶推出;3)我們不遺余力地將所有技術推向極限,,無論是臺積電的工藝技術,、封裝技術、內存技術,,還是光學技術等,,我們都追求極致的性能表現(xiàn)。
在完成硬件的極限挑戰(zhàn)后,,我們將全力以赴確保所有軟件都能在這個完整的平臺上順暢運行,。在計算機技術中,軟件慣性至關重要,。當我們的計算機平臺能夠向后兼容,,且架構上與已有軟件完美契合時,產(chǎn)品的上市速度將顯著提升,。因此,,當Blackwell平臺問世時,我們能夠充分利用已構建的軟件生態(tài)基礎,,實現(xiàn)驚人的市場響應速度,。明年,我們將迎來Blackwell Ultra,。
正如我們曾推出的H100和H200系列一樣,,Blackwell Ultra也將引領新一代產(chǎn)品的熱潮,帶來前所未有的創(chuàng)新體驗,。同時,,我們將繼續(xù)挑戰(zhàn)技術的極限,推出下一代頻譜交換機,,這是行業(yè)內的首次嘗試,。這一重大突破已經(jīng)成功實現(xiàn),,盡管我現(xiàn)在對于公開這個決定還心存些許猶豫。
在英偉達內部,,我們習慣于使用代碼名并保持一定的保密性,。很多時候,連公司內部的大多數(shù)員工都不甚了解這些秘密,。然而,,我們的下一代平臺已被命名為Rubin。關于Rubin,,我不會在此過多贅述,。我深知大家的好奇心,但請允許我保持一些神秘感,。你們或許已經(jīng)迫不及待想要拍照留念,,或是仔細研究那些小字部分,那就請隨意吧,。
我們不僅有Rubin平臺,一年后還將推出Rubin Ultra平臺,。在此展示的所有芯片都處于全面開發(fā)階段,,確保每一個細節(jié)都經(jīng)過精心打磨。我們的更新節(jié)奏依然是一年一次,,始終追求技術的極致,,同時確保所有產(chǎn)品都保持100%的架構兼容性。

回顧過去的12年,,從Imagenet誕生的那一刻起,,我們就預見到計算領域的未來將會發(fā)生翻天覆地的變化。如今,,這一切都成為了現(xiàn)實,,與我們當初的設想不謀而合。從2012年之前的GeForce到如今的英偉達,,公司經(jīng)歷了巨大的轉變,。在此,我要衷心感謝所有合作伙伴的一路支持與陪伴,。

機器人時代已經(jīng)到來
這就是英偉達的Blackwell平臺,,接下來,讓我們談談人工智能與機器人相結合的未來,。
物理人工智能正引領人工智能領域的新浪潮,,它們深諳物理定律,并能自如地融入我們的日常生活,。為此,,物理人工智能不僅需要構建一個精準的世界模型,,以理解如何解讀和感知周圍世界,更需具備卓越的認知能力,,以深刻理解我們的需求并高效執(zhí)行任務,。
展望未來,機器人技術將不再是一個遙不可及的概念,,而是日益融入我們的日常生活,。當提及機器人技術時,人們往往會聯(lián)想到人形機器人,,但實際上,,它的應用遠不止于此。機械化將成為常態(tài),,工廠將全面實現(xiàn)自動化,,機器人將協(xié)同工作,制造出一系列機械化產(chǎn)品,。它們之間的互動將更加密切,,共同創(chuàng)造出一個高度自動化的生產(chǎn)環(huán)境。
為了實現(xiàn)這一目標,,我們需要克服一系列技術挑戰(zhàn),。接下來,我將通過視頻展示這些前沿技術,。
這不僅僅是對未來的展望,,它正逐步成為現(xiàn)實。
我們將通過多種方式服務市場,。首先,,我們致力于為不同類型的機器人系統(tǒng)打造平臺:機器人工廠與倉庫專用平臺、物體操縱機器人平臺,、移動機器人平臺,,以及人形機器人平臺。這些機器人平臺與我們其他眾多業(yè)務一樣,,依托于計算機加速庫和預訓練模型,。
我們運用計算機加速庫、預訓練模型,,并在Omniverse中進行全方位的測試,、訓練和集成。正如視頻所示,,Omniverse是機器人學習如何更好地適應現(xiàn)實世界的地方,。當然,機器人倉庫的生態(tài)系統(tǒng)極為復雜,,需要眾多公司,、工具和技術來共同構建現(xiàn)代化的倉庫,。如今,倉庫正逐步邁向全面機械化,,終有一天將實現(xiàn)完全自動化,。
在這樣一個生態(tài)系統(tǒng)中,我們?yōu)檐浖袠I(yè),、邊緣人工智能行業(yè)和公司提供了SDK和API接口,,同時也為PLC和機器人系統(tǒng)設計了專用系統(tǒng),以滿足國防部等特定領域的需求,。這些系統(tǒng)通過集成商整合,,最終為客戶打造高效、智能的倉庫,。舉個例子,,Ken Mac正在為Giant Giant集團構建一座機器人倉庫。
接下來,,讓我們聚焦工廠領域,。工廠的生態(tài)系統(tǒng)截然不同。以富士康為例,,他們正在建設世界上一些最先進的工廠,。這些工廠的生態(tài)系統(tǒng)同樣涵蓋了邊緣計算機、機器人軟件,,用于設計工廠布局、優(yōu)化工作流程,、編程機器人,,以及用于協(xié)調數(shù)字工廠和人工智能工廠的PLC計算機。我們同樣為這些生態(tài)系統(tǒng)中的每一個環(huán)節(jié)提供了SDK接口,。
這樣的變革正在全球范圍內上演,。富士康和Delta正為其工廠構建數(shù)字孿生設施,實現(xiàn)現(xiàn)實與數(shù)字的完美融合,,而Omniverse在其中扮演了至關重要的角色,。同樣值得一提的是,和碩與Wistron也在緊隨潮流,,為各自的機器人工廠建立數(shù)字孿生設施,。
這確實令人興奮。接下來,,請欣賞一段富士康新工廠的精彩視頻,。
機器人工廠由三個主要計算機系統(tǒng)組成,在NVIDIA AI平臺上訓練人工智能模型,,我們確保機器人在本地系統(tǒng)上高效運行以編排工廠流程,。同時,,我們利用Omniverse這一模擬協(xié)作平臺,對包括機械臂和AMR(自主移動機器人)在內的所有工廠元素進行模擬,。值得一提的是,,這些模擬系統(tǒng)均共享同一個虛擬空間,實現(xiàn)無縫的交互與協(xié)作,。
當機械臂和AMR進入這個共享的虛擬空間時,,它們能夠在Omniverse中模擬出真實的工廠環(huán)境,確保在實際部署前進行充分的驗證和優(yōu)化,。
為了進一步提升解決方案的集成度和應用范圍,,我們提供了三款高性能計算機,并配備了加速層和預訓練人工智能模型,。此外,,我們已成功將NVIDIA Manipulator和Omniverse與西門子的工業(yè)自動化軟件和系統(tǒng)相結合。這種合作使得西門子在全球各地的工廠中都能夠實現(xiàn)更高效的機器人操作和自動化,。

除了西門子,,我們還與多家知名企業(yè)建立了合作關系。例如,,Symantec Pick AI已經(jīng)集成了NVIDIA Isaac Manipulator,,而Somatic Pick AI則成功運行并操作了ABB、KUKA,、Yaskawa Motoman等知名品牌的機器人,。
機器人技術和物理人工智能的時代已經(jīng)到來,它們正在各地被廣泛應用,,這并非科幻,,而是現(xiàn)實,令人倍感振奮,。展望未來,,工廠內的機器人將成為主流,它們將制造所有的產(chǎn)品,,其中兩個高產(chǎn)量機器人產(chǎn)品尤為引人注目,。首先是自動駕駛汽車或具備高度自主能力的汽車,英偉達再次憑借其全面的技術堆棧在這一領域發(fā)揮了核心作用,。明年,,我們計劃與梅賽德斯-奔馳車隊攜手,隨后在2026年與捷豹路虎(JLR)車隊合作,。我們提供完整的解決方案堆棧,,但客戶可根據(jù)需求選擇其中的任何部分或層級,因為整個驅動堆棧都是開放和靈活的。
接下來,,另一個可能由機器人工廠高產(chǎn)量制造的產(chǎn)品是人形機器人,。近年來,在認知能力和世界理解能力方面取得了巨大突破,,這一領域的發(fā)展前景令人期待,。我對人形機器人特別興奮,因為它們最有可能適應我們?yōu)槿祟愃鶚嫿ǖ氖澜纭?/p>
與其他類型的機器人相比,,訓練人形機器人需要大量的數(shù)據(jù),。由于我們擁有相似的體型,通過演示和視頻能力提供的大量訓練數(shù)據(jù)將極具價值,。因此,,我們預計這一領域將取得顯著的進步。

現(xiàn)在,,讓我們歡迎一些特別的機器人朋友,。機器人時代已經(jīng)來臨,這是人工智能的下一波浪潮,。中國臺灣制造的計算機種類繁多,,既有配備鍵盤的傳統(tǒng)機型,也有小巧輕便,、便于攜帶的移動設備,,以及為云端數(shù)據(jù)中心提供強大算力的專業(yè)設備。但展望未來,,我們將見證一個更為激動人心的時刻——制造會走路,、四處滾動的計算機,即智能機器人,。
這些智能機器人與我們所熟知的計算機在技術上有著驚人的相似性,,它們都是基于先進的硬件和軟件技術構建的。因此,,我們有理由相信,這將是一段真正非凡的旅程?。ň幾g/金鹿)

云南5名網(wǎng)紅被抓 詐騙粉絲11萬余元
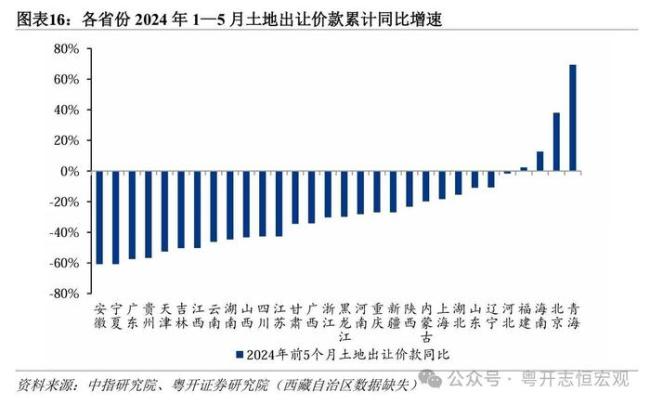
26省賣地收入下滑 地方政府財政承壓求變

17歲2米28女姚明入選大名單:國字號首秀能一鳴驚人嗎,?!

以色列前總理:我們在這幾個月中失去了世界的支持
云南5名網(wǎng)紅被抓 詐騙粉絲11萬余元

瞄準中國,,美軍加速!
17歲2米28女姚明入選大名單:國字號首秀能一鳴驚人嗎?!

秀肌肉,?美軍“羅斯福”號航母抵韓,,將參加韓美日“自由之刃”軍演

娜扎新電影哭到我心里了,,有點期待了!

白宮擔憂以總理訪美:不知道他會說些什么

專家稱文理分科讓畢業(yè)生就業(yè)更難 跨學科能力缺失成障礙

欲升級擴充核武庫 美國引全球走向“最危險的時刻”

全面戰(zhàn)爭,?美國向以色列保證

當美國海軍“最可怕的噩夢”真的來了……

李凱爾辟謠退出男籃 期待再次披掛上陣
26省賣地收入下滑 地方政府財政承壓求變

以美就武器交付問題陷入爭吵,以防長訪美尋求“解凍重型炸彈”

造價3億多美元扛不住4級風 美軍碼頭為何這么脆

沙特朝覲現(xiàn)死亡潮 千人亡,,半數(shù)因酷熱

普京強調國防只能依靠自己 自主軍工確保國家安全

村干部下潛徒手清淤 排水渠通了,村民心暖了

普京:沒人會援俄武器,,我們能自給自足

“這就是宇宙中最道德的軍隊?”

烏克蘭空襲克里米亞致5死逾百傷 俄方誓言回應
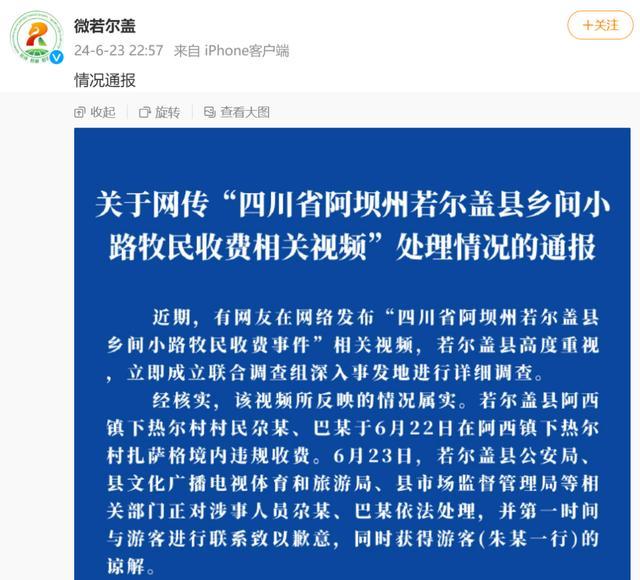
阿壩旅游遭攔路收費 官方通報處置結果

胡塞武裝趕跑了“艾森豪威爾”號航母,,菲律賓懵了!

汽車高管花式推薦大學專業(yè) 新機遇在哪?

俄對烏能源設施發(fā)動集群打擊,!澤連斯基:去年冬季以來,,俄已摧毀烏一半發(fā)電能力

貴州村超少年圓夢歐洲杯 足球激情跨越國界

胡塞武裝“襲擊疑云”下,,美軍“艾森豪威爾”號航母撤離紅海!

享界S9內飾曝光 8月上市 豪華行政級體驗來襲

針對中國意圖明顯,效果遭到各界質疑,!美軍加速組建關島“瀕海作戰(zhàn)團”
美國宇航員滯留太空 生命安危引關注

多地鼓勵放棄、退出農(nóng)村宅基地 新政策促房地產(chǎn)市場平穩(wěn)發(fā)展

警惕,!菲總統(tǒng)最新言論,話里有話
相關新聞
黃仁勛妄稱臺灣為“國家”,黃仁勛“飄”了,?
美國英偉達公司的創(chuàng)辦人及CEO黃仁勛訪問臺灣,,此行引發(fā)臺灣地區(qū)的高度關注,他的言論成為媒體聚焦點
2024-06-07 18:12:09黃仁勛妄稱臺灣為“國家”黃仁勛有望超越馬斯克成全球首富 GPU巨頭引領AI時代新篇章
英偉達的創(chuàng)始人兼CEO黃仁勛,,自企業(yè)1993年于硅谷誕生起,,便坐擁可觀財富。近期,,其個人資產(chǎn)更是經(jīng)歷了爆炸性增長,,達到了前所未有的高度
2024-05-27 22:49:22黃仁勛有望超越馬斯克成全球首富黃仁勛稱臺灣為國家 言論引爭議
2024-06-07 08:18:25黃仁勛稱臺灣為國家馬斯克向左,黃仁勛向右 華人首富之路加速,?
華人問鼎全球首富的位置,,正逐漸從夢想邁向現(xiàn)實。英偉達,,在人工智能時代的潮頭傲立,,僅一年半內股價激增十倍,五年視野下更是實現(xiàn)了二十八倍的驚人飛躍
2024-06-01 12:37:58馬斯克向左黃仁勛加州理工畢業(yè)典禮演講:我是個好老板
2024-06-18 09:45:41黃仁勛加州理工畢業(yè)典禮演講:我是個好老板黃仁勛在女粉絲胸前簽名 引網(wǎng)絡熱議
2024-06-06 17:31:45黃仁勛在女粉絲胸前簽名








