調(diào)查英偉達(dá)是中國(guó)GPU自主化一步險(xiǎn)棋

調(diào)查英偉達(dá)是中國(guó)GPU自主化一步險(xiǎn)棋
近日,中國(guó)科技領(lǐng)域接連發(fā)生兩件大事:
12月3日,,包括中國(guó)半導(dǎo)體行業(yè)協(xié)會(huì)在內(nèi)的多個(gè)權(quán)威行業(yè)組織,,罕見(jiàn)地發(fā)布公告,警告美國(guó)芯片產(chǎn)品的安全性和供應(yīng)穩(wěn)定性問(wèn)題,建議國(guó)內(nèi)企業(yè)在采購(gòu)時(shí)保持高度警惕;
12月9日,中國(guó)市場(chǎng)監(jiān)管總局宣布,,對(duì)全球GPU巨頭英偉達(dá)展開(kāi)反壟斷調(diào)查。調(diào)查英偉達(dá)是中國(guó)GPU自主化一步險(xiǎn)棋!
這兩件看似獨(dú)立的事件,,卻隱隱透出一條清晰的主線:在全球芯片供應(yīng)鏈?zhǔn)芟?、中美科技?jìng)爭(zhēng)加劇的背景下,中國(guó)正有意減少對(duì)美國(guó)產(chǎn)芯片的依賴,,特別是對(duì)英偉達(dá)GPU產(chǎn)品的高度依賴,。
英偉達(dá),毫無(wú)疑問(wèn)是全球AI計(jì)算領(lǐng)域的*,。在AI模型的訓(xùn)練與推理中,,GPU是核心算力的提供者,而英偉達(dá)的GPU市占率超過(guò)90%,,幾乎在AI訓(xùn)練市場(chǎng)占據(jù)壟斷地位,。無(wú)論是ChatGPT這樣的超大規(guī)模語(yǔ)言模型,還是自動(dòng)駕駛,、圖像識(shí)別等前沿應(yīng)用,,背后都有英偉達(dá)的身影。
不僅如此,,英偉達(dá)的霸權(quán)不止于硬件,。其自主開(kāi)發(fā)的CUDA生態(tài),早已成為AI開(kāi)發(fā)者的“操作系統(tǒng)”,,從底層硬件到上層算法工具一應(yīng)俱全,。可以說(shuō),,英偉達(dá)不僅掌握了硬件性能的高地,,還牢牢控制了開(kāi)發(fā)者生態(tài)的護(hù)城河。
然而,,這樣一家巨頭,,也成為中國(guó)“卡脖子”技術(shù)的象征。
目前,,中國(guó)正處于AI大模型發(fā)展的關(guān)鍵時(shí)期,。訓(xùn)練大模型需要海量數(shù)據(jù)、復(fù)雜算法,,更需要強(qiáng)大的算力支撐。作為支撐AI發(fā)展的“底座”,,GPU的短缺和技術(shù)封鎖直接決定了中國(guó)AI產(chǎn)業(yè)的上限,。
但擺在面前的,是一對(duì)矛盾:一方面,,中國(guó)需要大規(guī)模的GPU支持來(lái)推動(dòng)AI行業(yè)的發(fā)展,;另一方面,美國(guó)的技術(shù)封鎖讓中國(guó)對(duì)英偉達(dá)等美國(guó)產(chǎn)品的依賴變得極其脆弱。
在這種背景下,,中國(guó)的兩大動(dòng)作——行業(yè)協(xié)會(huì)警告和反壟斷調(diào)查——不禁讓人聯(lián)想:中國(guó)是否已經(jīng)準(zhǔn)備好對(duì)英偉達(dá)“開(kāi)刀”,?更重要的是,國(guó)產(chǎn)GPU是否已經(jīng)有能力接過(guò)這一重任,,承擔(dān)起支撐中國(guó)AI發(fā)展的任務(wù),?
如果答案是否定的,那么此舉可能會(huì)對(duì)中國(guó)AI產(chǎn)業(yè)帶來(lái)短期陣痛,;如果答案是肯定的,,那或許意味著國(guó)產(chǎn)GPU已經(jīng)迎來(lái)屬于自己的“拐點(diǎn)時(shí)刻”。
某種程度上,,這是一場(chǎng)關(guān)于技術(shù)自立的“豪賭”,。
國(guó)產(chǎn)GPU能否在這一輪科技競(jìng)賽中破局,關(guān)乎的不僅是AI產(chǎn)業(yè)的發(fā)展,,更是中國(guó)在全球科技版圖中的未來(lái)地位,。
01設(shè)計(jì)領(lǐng)域,國(guó)產(chǎn)GPU是否已經(jīng)準(zhǔn)備好,?
中國(guó)的GPU產(chǎn)業(yè)盡管起步較晚,,但近年來(lái),以華為昇騰,、壁仞科技,、寒武紀(jì)、景嘉微和摩爾線程為代表的一批企業(yè)正在迎頭追趕,。這些企業(yè)通過(guò)自主研發(fā)和技術(shù)創(chuàng)新,,在設(shè)計(jì)能力上取得了長(zhǎng)足進(jìn)步,逐漸縮小與國(guó)際巨頭的差距,。
華為昇騰:AI算力的領(lǐng)軍者
華為的昇騰系列芯片定位于AI計(jì)算領(lǐng)域,,其高性能計(jì)算能力使其在訓(xùn)練與推理任務(wù)中表現(xiàn)優(yōu)異。以昇騰910為例,,這款A(yù)I芯片在浮點(diǎn)運(yùn)算性能(FLOPS)方面達(dá)到256TFLOPS,,已經(jīng)能夠支持主流大模型的訓(xùn)練需求。此外,,昇騰的“MindSpore”生態(tài)進(jìn)一步豐富了其應(yīng)用場(chǎng)景,,為國(guó)產(chǎn)GPU生態(tài)奠定了基礎(chǔ)。
壁仞科技近年來(lái)憑借其BR100芯片成為行業(yè)焦點(diǎn),,據(jù)悉,,BR100是全球*采用Chiplet設(shè)計(jì)的大算力通用GPU,在AI訓(xùn)練與推理,、科學(xué)計(jì)算等場(chǎng)景中展現(xiàn)了強(qiáng)大潛力,。這標(biāo)志著中國(guó)在GPU芯片架構(gòu)設(shè)計(jì)上邁出了重要一步,,開(kāi)始具備與國(guó)際先進(jìn)設(shè)計(jì)理念抗衡的能力。
寒武紀(jì):推理與邊緣計(jì)算的穩(wěn)健選手
專注AI芯片的寒武紀(jì),,通過(guò)MLU系列產(chǎn)品(如MLU290,、MLU370),逐步占據(jù)國(guó)內(nèi)AI推理市場(chǎng)的高地,。其芯片不僅在深度學(xué)習(xí)推理中表現(xiàn)穩(wěn)定,,還廣泛應(yīng)用于智能駕駛、醫(yī)療影像等垂直領(lǐng)域,,展現(xiàn)了靈活性和適應(yīng)性,。
景嘉微:GPU的多元玩家
景嘉微以嵌入式GPU起家,其產(chǎn)品廣泛應(yīng)用于航空航天,、工業(yè)控制等特殊場(chǎng)景,。這種聚焦細(xì)分領(lǐng)域的策略,讓其在“短板領(lǐng)域”填補(bǔ)了市場(chǎng)空白,。
摩爾線程:瞄準(zhǔn)AI和圖形計(jì)算的先鋒者
摩爾線程是國(guó)內(nèi)為數(shù)不多專注于AI和圖形計(jì)算領(lǐng)域的全功能GPU企業(yè),,其自研的MUSA(摩爾線程統(tǒng)一系統(tǒng)架構(gòu))讓人眼前一亮。針對(duì)渲染,、視頻編解碼,、AI等場(chǎng)景,摩爾線程逐步完善產(chǎn)品布局,,成為國(guó)內(nèi)AI和圖形計(jì)算的重要補(bǔ)充,。
國(guó)產(chǎn)GPU與英偉達(dá)的性能較量,差距還有多遠(yuǎn),?
雖然國(guó)產(chǎn)GPU設(shè)計(jì)能力在近年來(lái)取得了顯著突破,,但與英偉達(dá)這樣的國(guó)際巨頭相比,依然存在差距,。英偉達(dá)的H100,、A100系列GPU,目前仍是全球AI計(jì)算領(lǐng)域的*產(chǎn)品,。
國(guó)產(chǎn)GPU與英偉達(dá)的差距,,體現(xiàn)在多個(gè)方面,例如:英偉達(dá)H100基于5nm Hopper架構(gòu),,支持HBM3內(nèi)存,,單卡算力超過(guò)1000TFLOPS,而國(guó)產(chǎn)GPU在多項(xiàng)參數(shù)上仍遜色于英偉達(dá),;在能耗比和散熱設(shè)計(jì)等方面,,國(guó)產(chǎn)GPU與英偉達(dá)的產(chǎn)品仍有一定距離。
另一方面,,國(guó)產(chǎn)GPU在推理任務(wù)和邊緣計(jì)算場(chǎng)景中,,已經(jīng)表現(xiàn)出接近甚至媲美英偉達(dá)的能力。例如寒武紀(jì)的MLU系列和壁仞的BR100,,在推理性能上可以替代部分英偉達(dá)的中高端產(chǎn)品,。此外,由于美國(guó)對(duì)華出口管控政策的限制,,中國(guó)能夠獲得的英偉達(dá)芯片往往是“閹割版”,,如A800(A100的降級(jí)版)。在這種情況下,,國(guó)產(chǎn)GPU的性能差距進(jìn)一步縮小,。
性能差距縮小,信心正在建立,。
盡管與英偉達(dá)的*產(chǎn)品相比,,國(guó)產(chǎn)GPU在算力和能耗比上仍存在顯著差距,但這一差距已經(jīng)不再“無(wú)法逾越”,。尤其是在推理,、邊緣計(jì)算和部分垂直場(chǎng)景中,國(guó)產(chǎn)GPU的表現(xiàn)已經(jīng)達(dá)到“可用”的水平,。
更重要的是,,國(guó)產(chǎn)GPU在自主設(shè)計(jì)上的突破,為未來(lái)的進(jìn)一步追趕奠定了堅(jiān)實(shí)基礎(chǔ),。隨著技術(shù)迭代和市場(chǎng)應(yīng)用的加速,,中國(guó)GPU設(shè)計(jì)能力有望逐步從“追趕”走向“部分超越”。
02中國(guó)半導(dǎo)體制造,,能否支撐高性能GPU生產(chǎn),?
高性能GPU的設(shè)計(jì)離不開(kāi)強(qiáng)大的制造支撐,近年來(lái),,中國(guó)(大陸)的半導(dǎo)體制造能力雖然仍與國(guó)際*水平存在一定差距,,但在關(guān)鍵技術(shù)節(jié)點(diǎn)上已取得顯著突破。
中芯國(guó)際和華虹集團(tuán)是中國(guó)大陸*的芯片代工企業(yè),,它們的技術(shù)進(jìn)展為國(guó)產(chǎn)GPU的制造提供了重要保障,。中芯國(guó)際的14nm工藝已進(jìn)入量產(chǎn)階段,且正在快速推進(jìn)N+1(接近7nm)工藝的研發(fā),。華虹集團(tuán)則在特色工藝上表現(xiàn)突出,,其28nm制程具備高可靠性和高良率,特別適合于國(guó)產(chǎn)GPU這類對(duì)性能和穩(wěn)定性要求較高的產(chǎn)品,。
相比之下,,國(guó)際*代工廠如臺(tái)積電、三星等已實(shí)現(xiàn)5nm,、3nm量產(chǎn),,這些制程更多用于智能手機(jī)SoC和高端CPU,。但在GPU領(lǐng)域,先進(jìn)制程的重要性有所降低,。
GPU與手機(jī)芯片制造,,截然不同的需求曲線。
GPU芯片的制造需求與手機(jī)芯片有顯著不同,,智能手機(jī)芯片強(qiáng)調(diào)小型化和功耗控制,,需要先進(jìn)的制程工藝,如5nm甚至3nm,,以實(shí)現(xiàn)高集成度和低能耗,。GPU主要應(yīng)用于數(shù)據(jù)中心和云計(jì)算服務(wù)器中,計(jì)算性能和并行處理能力是關(guān)鍵,,這使得GPU在功耗和尺寸上的要求相對(duì)寬松,。14nm和7nm制程,完全能夠滿足主流GPU的性能需求,。
這種需求差異意味著GPU的制造“門檻”低于手機(jī)芯片,,例如,英偉達(dá)的上一代A100GPU采用的是7nm工藝,,其性能已經(jīng)可以滿足大部分AI模型的訓(xùn)練需求,,而國(guó)產(chǎn)廠商的旗艦GPU產(chǎn)品在14nm制程下也能達(dá)到“可用”水平。對(duì)比之下,,制造GPU芯片對(duì)工藝的要求更可控,,進(jìn)一步降低了生產(chǎn)門檻。
產(chǎn)能需求,,小規(guī)模生產(chǎn)的制造潛力,。
相比智能手機(jī)芯片動(dòng)輒上億片的年需求量,GPU市場(chǎng)對(duì)產(chǎn)能的需求顯得更加“友好”,。以全球GPU市場(chǎng)為例,,2023年英偉達(dá)的AI訓(xùn)練GPU出貨量約為200萬(wàn)片,而整個(gè)高性能GPU市場(chǎng)的規(guī)模也不過(guò)千萬(wàn)片級(jí)別,。
國(guó)產(chǎn)GPU的目標(biāo)市場(chǎng)更為集中,,例如,壁仞科技和天數(shù)智芯瞄準(zhǔn)的數(shù)據(jù)中心和信創(chuàng)領(lǐng)域,,每年的出貨量需求大致在百萬(wàn)片級(jí)別,。這種需求規(guī)模對(duì)于中芯國(guó)際和華虹集團(tuán)現(xiàn)有的產(chǎn)能來(lái)說(shuō),完全在可控范圍內(nèi),。即使在14nm制程節(jié)點(diǎn)上,,國(guó)產(chǎn)代工廠也有能力快速滿足這一需求,并留有進(jìn)一步擴(kuò)展的余地,。
更重要的是,,中國(guó)的半導(dǎo)體制造業(yè)在產(chǎn)能和技術(shù)水平上具備一定的“實(shí)用主義”特質(zhì),,這尤其適用于GPU的生產(chǎn)。一方面,,國(guó)內(nèi)代工廠能夠快速調(diào)動(dòng)資源,,在較短時(shí)間內(nèi)完成中等規(guī)模的生產(chǎn)需求,;另一方面,,GPU的設(shè)計(jì)本身也有助于制造環(huán)節(jié)的靈活性。例如,,GPU的面積更大且不受封裝工藝的高度限制,,這使得國(guó)內(nèi)制造商能夠在“非最前沿”節(jié)點(diǎn)上實(shí)現(xiàn)高效生產(chǎn)。
即使對(duì)更先進(jìn)的7nm制程需求,,國(guó)內(nèi)通過(guò)設(shè)備優(yōu)化和晶圓廠升級(jí)也有能力實(shí)現(xiàn)量產(chǎn),。以中芯國(guó)際的N+1工藝為例,雖然名義上不屬于7nm工藝,,但其性能指標(biāo)接近臺(tái)積電的7nm制程,,已經(jīng)能夠滿足部分GPU的算力要求。
綜合來(lái)看,,中國(guó)半導(dǎo)體制造能力已足以支撐高性能GPU的生產(chǎn)需求,。以14nm和7nm制程為基礎(chǔ),國(guó)內(nèi)代工廠完全能夠滿足百萬(wàn)片級(jí)別的GPU年產(chǎn)能需求,。相比于智能手機(jī)芯片對(duì)3nm和5nm工藝的極高依賴,,GPU制造對(duì)工藝先進(jìn)性的需求相對(duì)“溫和”,為中國(guó)本土的生產(chǎn)能力提供了更廣闊的發(fā)揮空間,。
未來(lái),,隨著中芯國(guó)際和其他國(guó)產(chǎn)代工廠進(jìn)一步提升技術(shù)水平,中國(guó)GPU制造產(chǎn)業(yè)的核心挑戰(zhàn)將從“能否制造”轉(zhuǎn)向“如何擴(kuò)大規(guī)?!?。從已有的技術(shù)積累和市場(chǎng)需求來(lái)看,國(guó)產(chǎn)GPU的制造能力已經(jīng)不再是制約行業(yè)發(fā)展的明顯短板,,而是成為一個(gè)穩(wěn)定的支持點(diǎn),,為產(chǎn)業(yè)鏈其他環(huán)節(jié)提供了堅(jiān)實(shí)的后盾。
03政策加把火,,幫助國(guó)產(chǎn)GPU構(gòu)建良性循環(huán)
國(guó)產(chǎn)GPU正在從實(shí)驗(yàn)室走向市場(chǎng),,但現(xiàn)實(shí)是冷峻的:企業(yè)買賬了嗎?答案并不樂(lè)觀,。盡管國(guó)產(chǎn)GPU在技術(shù)指標(biāo)上不斷進(jìn)步,,在價(jià)格和供貨周期上也顯示出競(jìng)爭(zhēng)優(yōu)勢(shì),但用戶的信心卻遠(yuǎn)未建立,。信任缺失,,成為國(guó)產(chǎn)GPU市場(chǎng)化的*軟肋,。
首先,市場(chǎng)認(rèn)知的固化讓國(guó)產(chǎn)GPU陷入“低端化”的刻板印象,。長(zhǎng)期以來(lái),,英偉達(dá)等國(guó)際巨頭憑借強(qiáng)勁的性能和豐富的生態(tài)圈,幾乎成為GPU行業(yè)的代名詞,。企業(yè)用戶在選擇時(shí),,習(xí)慣性地將“國(guó)際品牌”與“高可靠性”劃等號(hào),而國(guó)產(chǎn)GPU則被貼上“不成熟”的標(biāo)簽,。這種對(duì)技術(shù)能力的偏見(jiàn),,嚴(yán)重壓縮了國(guó)產(chǎn)GPU的市場(chǎng)空間。
其次,,路徑依賴造成了選擇慣性,。英偉達(dá)不僅占據(jù)了硬件市場(chǎng)的*優(yōu)勢(shì),更通過(guò)CUDA生態(tài)將自己牢牢嵌入用戶的技術(shù)棧中,。從硬件到軟件,,從驅(qū)動(dòng)到開(kāi)發(fā)工具鏈,英偉達(dá)已經(jīng)構(gòu)建了一整套封閉而高效的生態(tài)體系,。用戶的業(yè)務(wù)流程,、應(yīng)用模型、優(yōu)化代碼,,甚至團(tuán)隊(duì)的技術(shù)經(jīng)驗(yàn),,都深度綁定在英偉達(dá)之上。切換到國(guó)產(chǎn)GPU不僅意味著硬件更換,,還涉及高昂的遷移成本和風(fēng)險(xiǎn),。這種“全方位鎖定效應(yīng)”,讓國(guó)產(chǎn)GPU廠商舉步維艱,。
在這種情況下,,國(guó)產(chǎn)GPU能否實(shí)現(xiàn)市場(chǎng)化突破,光靠市場(chǎng)還不行,,還需要政策的助力,。
最近,中國(guó)政府對(duì)英偉達(dá)展開(kāi)反壟斷調(diào)查,,同時(shí)多個(gè)行業(yè)協(xié)會(huì)發(fā)聲警告美國(guó)產(chǎn)品的不可靠性,。這些動(dòng)作不僅是對(duì)國(guó)際供應(yīng)鏈不穩(wěn)定的應(yīng)對(duì),也是為國(guó)產(chǎn)GPU發(fā)展創(chuàng)造市場(chǎng)空間的戰(zhàn)略布局,。通過(guò)政策干預(yù),,削弱外資品牌的市場(chǎng)支配力,能為國(guó)產(chǎn)GPU提供“試驗(yàn)窗口”。
但需要指出的是,,僅靠政策推力還不夠,。政策可以創(chuàng)造機(jī)會(huì),卻無(wú)法替代產(chǎn)品本身的競(jìng)爭(zhēng)力,。過(guò)度依賴政策保護(hù),,不僅無(wú)法建立用戶信任,還可能削弱國(guó)產(chǎn)廠商在技術(shù)競(jìng)爭(zhēng)中的動(dòng)力,。
真正讓國(guó)產(chǎn)GPU“跑起來(lái)”的關(guān)鍵,,在于通過(guò)市場(chǎng)應(yīng)用形成技術(shù)和資金的良性循環(huán)。GPU的技術(shù)迭代高度依賴實(shí)際使用場(chǎng)景的反饋,。只有讓產(chǎn)品走向市場(chǎng),,才能發(fā)現(xiàn)問(wèn)題、改進(jìn)性能,,形成“應(yīng)用優(yōu)化迭代”的正向循環(huán)。
在這一過(guò)程中,,典型場(chǎng)景的突破尤為重要,。國(guó)產(chǎn)GPU需要抓住一些能夠展示其性能和可靠性的代表性場(chǎng)景。比如,,景嘉微通過(guò)在軍工,、工業(yè)控制領(lǐng)域的穩(wěn)定表現(xiàn),逐漸積累了用戶信任,;天數(shù)智芯則在數(shù)據(jù)中心和AI推理領(lǐng)域證明了其性價(jià)比優(yōu)勢(shì),。這些成功案例不僅提升了產(chǎn)品的市場(chǎng)認(rèn)知,也為廠商提供了進(jìn)一步優(yōu)化的機(jī)會(huì),。
解決了市場(chǎng)認(rèn)知問(wèn)題,,接下來(lái)還需要打破路徑依賴。
而要打破用戶對(duì)英偉達(dá)的路徑依賴,,國(guó)產(chǎn)GPU廠商必須在技術(shù)支持,、應(yīng)用適配和生態(tài)建設(shè)三個(gè)層面發(fā)力,逐步瓦解英偉達(dá)的優(yōu)勢(shì)壁壘,。
*步:技術(shù)支持,,解決用戶的遷移顧慮
用戶對(duì)國(guó)產(chǎn)GPU*的擔(dān)憂在于使用風(fēng)險(xiǎn)。遷移意味著現(xiàn)有模型的重新優(yōu)化,、工具鏈的適配,,甚至可能導(dǎo)致業(yè)務(wù)中斷。國(guó)產(chǎn)廠商需要建立強(qiáng)大的技術(shù)支持體系,,從底層驅(qū)動(dòng)到應(yīng)用調(diào)優(yōu),,提供一站式的遷移解決方案。通過(guò)降低切換成本和風(fēng)險(xiǎn),讓用戶愿意嘗試國(guó)產(chǎn)方案,。
第二步:應(yīng)用適配,,用實(shí)際場(chǎng)景證明實(shí)力
企業(yè)用戶選擇GPU的核心標(biāo)準(zhǔn)是“能否高效完成現(xiàn)有任務(wù)”。國(guó)產(chǎn)廠商必須在應(yīng)用適配上大做文章,,通過(guò)兼容主流AI框架(如TensorFlow,、PyTorch)和優(yōu)化關(guān)鍵算法場(chǎng)景,確保國(guó)產(chǎn)GPU可以無(wú)縫接入用戶的業(yè)務(wù)流程,。只有在實(shí)際場(chǎng)景中表現(xiàn)穩(wěn)定,,用戶信任才能逐步建立。
第三步:生態(tài)建設(shè),,擺脫硬件的單點(diǎn)競(jìng)爭(zhēng)
英偉達(dá)*的護(hù)城河不是硬件,,而是其深厚的生態(tài)系統(tǒng)。CUDA生態(tài)幾乎成為行業(yè)開(kāi)發(fā)者的默認(rèn)語(yǔ)言,,綁定了整個(gè)技術(shù)鏈條,。國(guó)產(chǎn)GPU要實(shí)現(xiàn)突破,必須在生態(tài)建設(shè)上投入更多資源,。這不僅包括軟件工具的開(kāi)發(fā),,還需要通過(guò)與國(guó)內(nèi)AI框架(如飛槳、MindSpore)合作,,構(gòu)建開(kāi)放而多元的國(guó)產(chǎn)GPU生態(tài),。
國(guó)產(chǎn)GPU的市場(chǎng)化不只是一次技術(shù)競(jìng)賽,更是一場(chǎng)信任的戰(zhàn)役,。政策可以提供一時(shí)的助推力,,但無(wú)法真正改變用戶的選擇習(xí)慣。只有通過(guò)應(yīng)用場(chǎng)景的突破,、技術(shù)支持的完善和生態(tài)系統(tǒng)的構(gòu)建,,國(guó)產(chǎn)GPU才能從“替代性產(chǎn)品”轉(zhuǎn)型為“可信賴的選擇”。
未來(lái)的競(jìng)爭(zhēng)不僅是GPU性能的較量,,更是生態(tài)的比拼,。國(guó)產(chǎn)廠商需要認(rèn)識(shí)到,用戶選擇GPU并不僅僅因?yàn)樗昂糜谩?,而是因?yàn)樗爸档眯湃巍?。而這種信任的建立,絕非一朝一夕之功,,而是一場(chǎng)漫長(zhǎng)而深刻的市場(chǎng)教育與技術(shù)迭代之旅,。
04CUDA,是擺在國(guó)產(chǎn)GPU面前*的攔路虎
前面,,我們分析了國(guó)產(chǎn)GPU崛起的可能性,。不要高興得太早,接下來(lái),我們就來(lái)分析一下其中的障礙和問(wèn)題,。首先,,我們來(lái)看看最廣為人知的CUDA。
英偉達(dá)在GPU領(lǐng)域的主導(dǎo)地位,,不僅來(lái)源于其硬件性能的強(qiáng)悍,,更因?yàn)樗鼧?gòu)筑了一個(gè)牢不可破的生態(tài)護(hù)城河——CUDA。這一軟件開(kāi)發(fā)框架,,堪稱英偉達(dá)的“殺手級(jí)武器”,,鎖定了從開(kāi)發(fā)者到企業(yè)用戶的全產(chǎn)業(yè)鏈。
CUDA的“全覆蓋”能力是英偉達(dá)生態(tài)的核心,,通過(guò)提供從底層驅(qū)動(dòng)到高層應(yīng)用庫(kù)的全面支持,,CUDA幾乎成為GPU編程的行業(yè)標(biāo)準(zhǔn)。在AI領(lǐng)域,,CUDA的優(yōu)化使得開(kāi)發(fā)者可以輕松調(diào)用英偉達(dá)GPU的強(qiáng)大算力,,完成從圖像處理到深度學(xué)習(xí)的各種任務(wù)。無(wú)論是訓(xùn)練大模型還是進(jìn)行實(shí)時(shí)推理,,CUDA都提供了*的工具鏈支持,。
即便是國(guó)際巨頭如AMD和英特爾,也難以撼動(dòng)CUDA的生態(tài)地位,。AMD曾推出的ROCm(RadeonOpenCompute)在性能上雖能與CUDA抗衡,但由于生態(tài)不完善,,始終未能形成氣候,。英特爾推出的oneAPI嘗試通過(guò)跨平臺(tái)工具整合資源,但在開(kāi)發(fā)者支持上依然遠(yuǎn)遜于CUDA,。這表明,,生態(tài)護(hù)城河不僅是技術(shù)較量,更是時(shí)間積累和開(kāi)發(fā)者信任的結(jié)果,。
對(duì)于國(guó)產(chǎn)GPU而言,,這道護(hù)城河更顯深不可測(cè)。在硬件性能和制造能力逐漸接近國(guó)際水準(zhǔn)的今天,,應(yīng)用生態(tài)的差距成為國(guó)產(chǎn)GPU崛起的*障礙,。
相比英偉達(dá)幾十年的積累,國(guó)產(chǎn)GPU在生態(tài)建設(shè)上幾乎是“白紙起步”,。盡管近年來(lái)國(guó)內(nèi)企業(yè)在生態(tài)系統(tǒng)上有所布局,,但總體來(lái)看,軟件開(kāi)發(fā)工具的缺乏,、開(kāi)發(fā)者社區(qū)的薄弱以及行業(yè)標(biāo)準(zhǔn)的滯后,,嚴(yán)重制約了國(guó)產(chǎn)GPU的市場(chǎng)化進(jìn)程。
這具體表現(xiàn)在以下幾個(gè)方面:
1.工具鏈和算法庫(kù)的缺失
國(guó)產(chǎn)GPU雖然在硬件性能上逐漸追趕國(guó)際巨頭,但軟件工具鏈的匱乏讓開(kāi)發(fā)者“無(wú)從下手”,。英偉達(dá)的CUDA生態(tài)提供了幾乎所有主流算法的優(yōu)化庫(kù),,開(kāi)發(fā)者可以即插即用。而國(guó)產(chǎn)GPU大多僅提供基礎(chǔ)的驅(qū)動(dòng)支持,,甚至需要開(kāi)發(fā)者自行編寫底層接口,,使用門檻高、效率低,。
2.開(kāi)發(fā)者社區(qū)的缺位
開(kāi)發(fā)者是生態(tài)系統(tǒng)的“生命線”,,英偉達(dá)通過(guò)CUDA積累了數(shù)百萬(wàn)開(kāi)發(fā)者,這些開(kāi)發(fā)者不僅使用其產(chǎn)品,,更通過(guò)開(kāi)源社區(qū)貢獻(xiàn)代碼,,反哺生態(tài)成長(zhǎng)。而國(guó)產(chǎn)GPU在開(kāi)發(fā)者社區(qū)的建設(shè)上尚屬起步階段,,缺乏足夠的用戶規(guī)模和技術(shù)貢獻(xiàn),。
3.行業(yè)標(biāo)準(zhǔn)和應(yīng)用適配的滯后
在國(guó)際市場(chǎng)上,英偉達(dá)已經(jīng)通過(guò)CUDA影響了AI,、圖形渲染和高性能計(jì)算等多個(gè)行業(yè)的標(biāo)準(zhǔn),,而國(guó)產(chǎn)GPU仍缺乏類似的行業(yè)話語(yǔ)權(quán)。這導(dǎo)致許多主流應(yīng)用對(duì)國(guó)產(chǎn)GPU的支持不足,,進(jìn)一步加劇了生態(tài)劣勢(shì),。
那么,要如何跨越CUDA的“護(hù)城河”呢,?
打破英偉達(dá)的生態(tài)壟斷,,已經(jīng)成為國(guó)產(chǎn)GPU能否崛起的關(guān)鍵戰(zhàn)役。不得不說(shuō),,要打贏這一仗,,難度非常之大,而且失敗的可能性很大,。但是,,成事在天,謀事在人,,要想實(shí)現(xiàn)這個(gè)目標(biāo),,可以從以下幾個(gè)方面著手:
1.依托開(kāi)源,構(gòu)建國(guó)產(chǎn)GPU的基礎(chǔ)生態(tài)
開(kāi)源是國(guó)產(chǎn)GPU彎道超車的*路徑之一,,通過(guò)與開(kāi)源社區(qū)合作,,國(guó)產(chǎn)GPU可以快速積累工具鏈和算法庫(kù)的支持。例如,,國(guó)內(nèi)主流AI框架如飛槳(PaddlePaddle)和MindSpore,,已經(jīng)在部分國(guó)產(chǎn)GPU上完成適配,。這種依托開(kāi)源平臺(tái)的方式,不僅可以降低生態(tài)建設(shè)成本,,還能通過(guò)社區(qū)貢獻(xiàn)加速技術(shù)迭代,。
2.標(biāo)準(zhǔn)化與互通性,降低開(kāi)發(fā)者遷移成本
國(guó)產(chǎn)GPU需要制定開(kāi)放的行業(yè)標(biāo)準(zhǔn),,推動(dòng)與主流AI框架和開(kāi)發(fā)工具的無(wú)縫兼容,。類似CUDA的封閉生態(tài),盡管強(qiáng)大,,卻容易引發(fā)開(kāi)發(fā)者的反感,。國(guó)產(chǎn)GPU如果能夠通過(guò)標(biāo)準(zhǔn)化實(shí)現(xiàn)與TensorFlow、PyTorch等主流框架的兼容性,,將有助于吸引更多開(kāi)發(fā)者嘗試,,并逐步轉(zhuǎn)化為忠實(shí)用戶。
3.跨行業(yè)協(xié)同,,形成產(chǎn)業(yè)合力
國(guó)產(chǎn)GPU廠商需要聯(lián)合產(chǎn)業(yè)鏈上下游,,構(gòu)建協(xié)同發(fā)展的生態(tài)體系。通過(guò)與國(guó)內(nèi)的AI應(yīng)用開(kāi)發(fā)商,、科研機(jī)構(gòu)和云服務(wù)商合作,,推動(dòng)更多垂直行業(yè)采用國(guó)產(chǎn)GPU。這種自上而下的市場(chǎng)引導(dǎo),,可以有效帶動(dòng)開(kāi)發(fā)者群體的擴(kuò)展,。
可以說(shuō),國(guó)產(chǎn)GPU在性能和制造能力上的追趕已經(jīng)初見(jiàn)成效,,但生態(tài)建設(shè)仍是“最后一公里”,。這不僅是技術(shù)挑戰(zhàn),更是時(shí)間和信任的積累過(guò)程,。英偉達(dá)通過(guò)CUDA建立的護(hù)城河,成為全球GPU市場(chǎng)的“通行證”,,而國(guó)產(chǎn)GPU要想真正與之競(jìng)爭(zhēng),,必須在應(yīng)用生態(tài)的廣度和深度上實(shí)現(xiàn)突圍。
未來(lái),,國(guó)產(chǎn)GPU的成功不僅取決于硬件性能的迭代,,更依賴于能否構(gòu)建一個(gè)開(kāi)放、多元,、可持續(xù)發(fā)展的應(yīng)用生態(tài),。只有突破這道護(hù)城河,國(guó)產(chǎn)GPU才能真正站上全球競(jìng)爭(zhēng)的舞臺(tái),,而這場(chǎng)“生態(tài)之戰(zhàn)”,,才剛剛開(kāi)始,。
05除了CUDA,還有哪些“大山”要攀登
需要指出的是,,支撐英偉達(dá)3萬(wàn)億美元市值的,,可不僅僅是CUDA,他還有很多“絕招”,。國(guó)產(chǎn)GPU即使想在中國(guó)市場(chǎng)實(shí)現(xiàn)對(duì)英偉達(dá)的替換,,也必須在這些“招式”上取得成效。
英偉達(dá)的優(yōu)勢(shì)在于一個(gè)全方位的技術(shù)體系,,從高帶寬內(nèi)存到高性能互聯(lián),,從一體化數(shù)據(jù)中心解決方案到規(guī)模化GPU集群的部署,,每一個(gè)環(huán)節(jié)都構(gòu)成了其不可忽視的壁壘,。要實(shí)現(xiàn)全面替代,國(guó)產(chǎn)GPU必須逐一擊破這些核心障礙,。
1.HBM(高帶寬內(nèi)存):數(shù)據(jù)吞吐的極限挑戰(zhàn)
在AI訓(xùn)練和科學(xué)計(jì)算中,,GPU的性能不僅取決于算力,更受制于數(shù)據(jù)吞吐能力,。英偉達(dá)通過(guò)HBM(高帶寬內(nèi)存)技術(shù)實(shí)現(xiàn)了超高的數(shù)據(jù)帶寬,,其最新的H100GPU搭載HBM3內(nèi)存,帶寬高達(dá)3TB/s,。這一指標(biāo)對(duì)于處理大規(guī)模訓(xùn)練數(shù)據(jù),、加速模型收斂至關(guān)重要。
目前,,國(guó)產(chǎn)GPU大多仍采用傳統(tǒng)的GDDR顯存,。雖然GDDR在中低端應(yīng)用中尚可一戰(zhàn),但面對(duì)高強(qiáng)度AI訓(xùn)練場(chǎng)景,,內(nèi)存帶寬成為*的性能瓶頸,。此外,HBM技術(shù)由少數(shù)國(guó)際存儲(chǔ)廠商壟斷,,國(guó)產(chǎn)替代還處于研發(fā)初期,。
國(guó)產(chǎn)GPU廠商需要加速與本土存儲(chǔ)企業(yè)(如長(zhǎng)江存儲(chǔ)、兆易創(chuàng)新)的合作,,推動(dòng)HBM技術(shù)的國(guó)產(chǎn)化進(jìn)程,。同時(shí),在設(shè)計(jì)中優(yōu)化片上緩存(如SRAM)以提升數(shù)據(jù)處理效率,,彌補(bǔ)短期內(nèi)HBM不足的劣勢(shì),。
2.高性能互聯(lián)技術(shù):多卡協(xié)同的關(guān)鍵難題
AI模型的規(guī)模正在不斷擴(kuò)大,從數(shù)億參數(shù)擴(kuò)展到千億甚至萬(wàn)億級(jí)別,。這種規(guī)模下,,單卡性能已無(wú)法滿足計(jì)算需求,,多GPU協(xié)同成為主流解決方案。英偉達(dá)的NVLink技術(shù)通過(guò)高帶寬,、低延遲的互聯(lián)方式,,將多塊GPU整合為統(tǒng)一的計(jì)算資源,其在大規(guī)模集群中的表現(xiàn)尤為出色,。
國(guó)產(chǎn)GPU在多卡協(xié)同方面的能力相對(duì)較弱,,目前尚無(wú)可與NVLink匹敵的高效互聯(lián)技術(shù)。多卡通信帶寬不足,、延遲過(guò)高的問(wèn)題,,直接制約了國(guó)產(chǎn)GPU在大規(guī)模AI訓(xùn)練任務(wù)中的應(yīng)用。
國(guó)產(chǎn)GPU需要研發(fā)自主的高性能互聯(lián)技術(shù),,支持多卡間的高速數(shù)據(jù)交換,,同時(shí)優(yōu)化GPU與CPU之間的通信效率。與國(guó)內(nèi)CPU廠商(如飛騰,、海光)合作,,構(gòu)建兼容性強(qiáng)的異構(gòu)計(jì)算架構(gòu),是實(shí)現(xiàn)這一目標(biāo)的關(guān)鍵,。
3.數(shù)據(jù)中心解決方案:大規(guī)模GPU集群的挑戰(zhàn)
英偉達(dá)的成功不僅在于硬件,,更在于其對(duì)數(shù)據(jù)中心解決方案的深刻理解。其DGX系列產(chǎn)品將GPU,、存儲(chǔ),、網(wǎng)絡(luò)與軟件整合為一體化系統(tǒng),可直接部署到數(shù)據(jù)中心,,為企業(yè)提供即插即用的AI計(jì)算能力,。然而,真正的核心優(yōu)勢(shì)在于大規(guī)模GPU集群的構(gòu)建能力,,尤其是在萬(wàn)卡級(jí)別甚至10萬(wàn)卡級(jí)別的智算中心部署中,,英偉達(dá)展現(xiàn)了無(wú)可比擬的優(yōu)勢(shì)。
英偉達(dá)通過(guò)其DGXSuperPOD方案,,整合多達(dá)數(shù)千甚至上萬(wàn)塊GPU,,并通過(guò)NVSwitch和InfiniBand網(wǎng)絡(luò)實(shí)現(xiàn)全互聯(lián)。其分布式存儲(chǔ)系統(tǒng)與優(yōu)化軟件棧(如CUDA集群管理工具)高度協(xié)同,,能夠?qū)崿F(xiàn)高效的數(shù)據(jù)調(diào)度和算力分配。這種集群部署能力,,已經(jīng)成為支持超大規(guī)模AI模型(如GPT-4)訓(xùn)練的基礎(chǔ)設(shè)施,。
例如,讓馬斯克出盡風(fēng)頭的10萬(wàn)GPU的超算中心,,正是得益于英偉達(dá)的支持,。
國(guó)產(chǎn)GPU目前在集群方案的完整性上差距明顯,,雖然單卡性能逐步接近英偉達(dá),但在萬(wàn)卡級(jí)別的分布式部署中,,缺乏成熟的硬件架構(gòu)和軟件支持,。例如,多卡互聯(lián)方案不夠高效,,集群管理工具不完善,,導(dǎo)致算力利用率低、任務(wù)分配效率不足,。
國(guó)產(chǎn)GPU廠商需要引入片上交換網(wǎng)絡(luò)(如NVSwitch替代方案)和高性能互聯(lián)協(xié)議,,支持GPU之間的低延遲通信。同時(shí),,與國(guó)內(nèi)存儲(chǔ)廠商合作,,構(gòu)建高性能分布式存儲(chǔ)解決方案,解決海量數(shù)據(jù)的讀寫瓶頸,。
同時(shí),,國(guó)產(chǎn)GPU廠商需要借鑒英偉達(dá)的CUDA生態(tài),開(kāi)發(fā)集群調(diào)度和負(fù)載均衡工具,,支持任務(wù)分解,、數(shù)據(jù)分發(fā)和算力動(dòng)態(tài)調(diào)整,并與國(guó)內(nèi)云服務(wù)商(如阿里云,、騰訊云)合作,,提供大規(guī)模集群的全棧解決方案。
更進(jìn)一步,,國(guó)產(chǎn)GPU廠商需要與國(guó)內(nèi)IT基礎(chǔ)設(shè)施企業(yè)聯(lián)合,,建立以國(guó)產(chǎn)GPU為核心的智算中心示范項(xiàng)目,為國(guó)產(chǎn)GPU在大規(guī)模部署中的能力提供背書,。
4.GPU虛擬化與多租戶支持:云計(jì)算的基礎(chǔ)設(shè)施
英偉達(dá)的vGPU技術(shù)支持GPU虛擬化,,使單塊物理GPU可分割為多個(gè)虛擬實(shí)例,為云計(jì)算的多租戶管理和資源高效利用提供了可能,,這種能力已經(jīng)成為國(guó)內(nèi)云計(jì)算市場(chǎng)的剛需,。
國(guó)產(chǎn)GPU目前在虛擬化支持方面尚未形成完整的技術(shù)棧,云服務(wù)商在使用國(guó)產(chǎn)GPU時(shí),,難以實(shí)現(xiàn)靈活的資源分配,。這種劣勢(shì)直接削弱了國(guó)產(chǎn)GPU在云計(jì)算市場(chǎng)的競(jìng)爭(zhēng)力。
為了補(bǔ)上這個(gè)短板,,國(guó)產(chǎn)GPU廠商,,需要開(kāi)發(fā)GPU虛擬化技術(shù),支持多租戶環(huán)境中的資源動(dòng)態(tài)分配,;優(yōu)化與云計(jì)算平臺(tái)的適配,,確保在阿里云,、騰訊云等平臺(tái)上的無(wú)縫部署。同時(shí),,還要推動(dòng)國(guó)產(chǎn)GPU在虛擬桌面基礎(chǔ)設(shè)施(VDI)領(lǐng)域的應(yīng)用,,實(shí)現(xiàn)商業(yè)化突破。
此外,,國(guó)產(chǎn)GPU仍需其他方面的努力,,比如通過(guò)更先進(jìn)的架構(gòu)設(shè)計(jì)和工藝優(yōu)化,進(jìn)一步提升性能/功耗比,,減少部署成本,。
綜上,國(guó)產(chǎn)GPU正在迎來(lái)自己的“躍遷時(shí)刻”,。從性能到制造,,從市場(chǎng)化到生態(tài)建設(shè),國(guó)產(chǎn)廠商一步步縮小著與國(guó)際巨頭的差距,。然而,,與其說(shuō)這是一場(chǎng)追趕賽,不如說(shuō)是一場(chǎng)全新的產(chǎn)業(yè)博弈,。國(guó)產(chǎn)GPU不可能依靠簡(jiǎn)單的模仿超越英偉達(dá),,而是必須通過(guò)技術(shù)突破和生態(tài)創(chuàng)新,重新定義行業(yè)規(guī)則,。
真正的挑戰(zhàn)不僅在于技術(shù),,更在于時(shí)間和信任。英偉達(dá)用了幾十年構(gòu)建的生態(tài)系統(tǒng),,不僅鎖住了市場(chǎng),,更鎖住了開(kāi)發(fā)者和用戶的心。而國(guó)產(chǎn)GPU要打破這一桎梏,,必須以更加開(kāi)放的姿態(tài),、更敏捷的迭代能力,在關(guān)鍵領(lǐng)域中找到自己的獨(dú)特定位,。市場(chǎng)不會(huì)因?yàn)閲?guó)產(chǎn)化的情懷而買單,,用戶只會(huì)因?yàn)樾阅堋⒊杀竞腕w驗(yàn)的壓倒性優(yōu)勢(shì)而選擇,。
但更重要的是,,國(guó)產(chǎn)GPU的崛起并不僅僅是一個(gè)行業(yè)的成功,而是關(guān)乎中國(guó)科技自主的全局性課題,。從芯片設(shè)計(jì)到制造工藝,,從應(yīng)用生態(tài)到市場(chǎng)信任,每一步突破都意味著中國(guó)科技產(chǎn)業(yè)鏈更加堅(jiān)韌的一環(huán)。這是一場(chǎng)持久戰(zhàn),,也是一場(chǎng)決心之戰(zhàn)。
在未來(lái),,國(guó)產(chǎn)GPU能否打破英偉達(dá)的霸權(quán),,關(guān)鍵不在于復(fù)制對(duì)手的成功,而在于創(chuàng)造屬于自己的道路,?;蛟S,用不了多久,,當(dāng)我們提到全球最強(qiáng)算力時(shí),,國(guó)產(chǎn)GPU也能自信地說(shuō)一句:“我們,沒(méi)有辜負(fù)這個(gè)時(shí)代的饋贈(zèng),,沒(méi)有辜負(fù)這個(gè)國(guó)家的期待,。”調(diào)查英偉達(dá)是中國(guó)GPU自主化一步險(xiǎn)棋,!

新興市場(chǎng)貨幣遭遇不同程度拋售潮 新一輪貶值潮來(lái)襲
燒傷媽媽皮膚康復(fù)狀態(tài)良好,,跟丈夫感謝了所有幫助他們的人

李稻葵解讀公積金異地互通 順應(yīng)人口流動(dòng)大趨勢(shì)

珍愛(ài)網(wǎng)被罰170萬(wàn)重罰還當(dāng)重管 治理需出重拳

韓國(guó)9名家人遇難的小狗已被收養(yǎng) 苦等主人引關(guān)注
燒傷媽媽皮膚康復(fù)狀態(tài)良好,跟丈夫感謝了所有幫助他們的人

韓墜毀客機(jī)兩個(gè)黑匣子處理進(jìn)展 事故已致124人死亡

渝湘復(fù)線高速預(yù)計(jì)2025年內(nèi)全線通車 部分路段已開(kāi)放通行

韓國(guó)務(wù)安機(jī)場(chǎng)扣押搜查,!又叫曬辣椒機(jī)場(chǎng),? 新航線首航悲劇引發(fā)調(diào)查

專家:美以低估了胡塞武裝的實(shí)力 警告無(wú)效凸顯韌性

火箭擒獨(dú)行俠 申京格林圍剿歐文 火箭五人上雙鎖定勝局

韓國(guó)空難是天災(zāi)還是人禍 悲劇引發(fā)深思

突發(fā)!韓國(guó)執(zhí)政黨總部遭遇炸彈威脅 警方緊急搜查未發(fā)現(xiàn)爆炸物
韓國(guó)空難一個(gè)錯(cuò)誤連著一個(gè)錯(cuò)誤 多因素釀成慘劇

小S曬了全家福 姐妹團(tuán)聚歡樂(lè)多

俄對(duì)基輔中心發(fā)動(dòng)罕見(jiàn)空襲 瞄準(zhǔn)烏總統(tǒng)府區(qū)域
新興市場(chǎng)貨幣遭遇不同程度拋售潮 新一輪貶值潮來(lái)襲

男子跨年夜對(duì)近9萬(wàn)氣球噴射加特林 煙花惹禍被捕
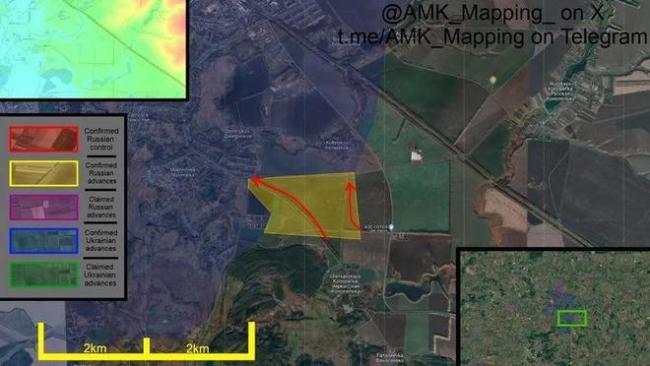
新年第一天,,俄軍紅軍城鉗形攻勢(shì)雛形初現(xiàn),,烏軍逃離庫(kù)拉霍夫發(fā)電廠!
鹿晗高瀚宇眉釘大片 新年第一炸

專家說(shuō)很多翻譯碩士水平比不上AI 人工智能沖擊下的職業(yè)挑戰(zhàn)

恭喜國(guó)乒,!孫穎莎教練走馬上任,,亮相國(guó)乒新崗位后,劉國(guó)梁期待,!

律師談超市因員工盜竊虧損200萬(wàn)倒閉 員工集體監(jiān)守自盜

韓國(guó)民眾獻(xiàn)花哀悼墜機(jī)遇難者 白菊寄哀思

馬斯克,、扎克伯格、黃仁勛等科技大佬領(lǐng)銜 全球500富豪身家合計(jì)破10萬(wàn)億美元

霉霉登上央視2024世界新聞年鑒 回顧一年熱點(diǎn)事件

朝鮮新型戰(zhàn)艦疑似曝光 加強(qiáng)軍事現(xiàn)代化進(jìn)程
馬斯克“改名”引爆潑天富貴 神秘交易員兩天狂賺上千萬(wàn) 幣圈掀起投機(jī)熱潮

韓代總統(tǒng)崔相穆同一天做了兩件事 政壇風(fēng)波再起

特朗普“突襲”,,新興市場(chǎng)貨幣貶值潮來(lái)襲,!這國(guó)匯率跌至歷史新低!

滑翔傘墜落女大學(xué)生及駕駛員身亡,!

春運(yùn)頭兩日北京始發(fā)熱門車次迅速售罄 熱門時(shí)段一票難求

媒體:中國(guó)軍用5G可連接萬(wàn)個(gè)機(jī)器人 改變現(xiàn)代戰(zhàn)爭(zhēng)模式

衡陽(yáng)一滑翔傘墜落 游客和教練身亡 兩人遺體已被運(yùn)走
李稻葵解讀公積金異地互通 順應(yīng)人口流動(dòng)大趨勢(shì)
相關(guān)新聞
涉嫌違反中國(guó)反壟斷法,,英偉達(dá)被立案調(diào)查
2024-12-10 10:47:26涉嫌違反反壟斷法英偉達(dá)被立案調(diào)查英偉達(dá)的“GPU狂熱”才剛開(kāi)始 全面AI熱潮蓄勢(shì)待發(fā)
2024-10-10 14:56:50英偉達(dá)的“GPU狂熱”才剛開(kāi)始英偉達(dá)市值一夜大漲7540億元 GPU需求持續(xù)強(qiáng)勁
2024-08-13 13:59:06英偉達(dá)市值一夜大漲7540億元花旗分析師發(fā)布報(bào)告力挺英偉達(dá) GPU仍將主導(dǎo)市場(chǎng)
2024-12-18 20:59:58花旗分析師發(fā)布報(bào)告力挺英偉達(dá)律師稱英偉達(dá)中國(guó)業(yè)務(wù)暫不受限 反壟斷調(diào)查進(jìn)行中
2024-12-10 18:23:27律師稱英偉達(dá)中國(guó)業(yè)務(wù)暫不受限英偉達(dá)被立案調(diào)查 涉嫌違反反壟斷法
2024-12-09 19:40:30英偉達(dá)被立案調(diào)查