全球掀DeepSeek復(fù)現(xiàn)狂潮 硅谷巨頭神話崩塌,!

硅谷正經(jīng)歷由中國公司引發(fā)的重大變革。全美都在擔(dān)憂全球人工智能的中心是否已經(jīng)轉(zhuǎn)向中國。此時,,全球范圍內(nèi)掀起了復(fù)現(xiàn)DeepSeek模型的熱潮,。正如LeCun所說:“這是開源對閉源的一次勝利,?!边@些討論引發(fā)了人們對數(shù)百億美元支出必要性的質(zhì)疑,,甚至有人預(yù)測中國量化基金可能會導(dǎo)致納斯達(dá)克崩盤,。

未來,,大模型時代可能進入一個分水嶺:高性能模型不再僅限于算力巨頭,,而是每個人都能擁有。UC伯克利博士生潘家怡及其團隊在CountDown游戲中復(fù)現(xiàn)了DeepSeek R1-Zero,,結(jié)果令人滿意,。實驗表明,通過強化學(xué)習(xí),,3B的基礎(chǔ)語言模型也能自我驗證和搜索,,成本不到30美元即可見證“啊哈”時刻。該項目名為TinyZero,,采用R1-Zero算法,,給定基礎(chǔ)語言模型、提示和真實獎勵信號后運行強化學(xué)習(xí),。模型從簡單輸出開始,,逐步進化出自我糾正和搜索策略。
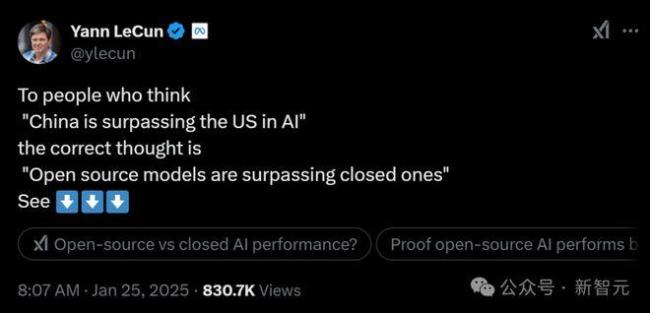
消融實驗中,,研究人員使用了Qwen-2.5-Base的不同參數(shù)規(guī)模(0.5B、1.5B,、3B,、7B)。結(jié)果顯示,,0.5B模型只能猜測解決方案,,而從1.5B開始,模型學(xué)會了搜索,、自我驗證和修正解決方案,,從而獲得更高分?jǐn)?shù)。研究還發(fā)現(xiàn),,額外的指令微調(diào)并非必要,,這支持了R1-Zero的設(shè)計決策。此外,,具體的RL算法并不重要,,PPO、GRPO,、PRIME等算法都能帶來不錯的性能表現(xiàn),。

港科大助理教授何俊賢的團隊僅用8K樣本,,在7B模型上復(fù)現(xiàn)了DeepSeek-R1-Zero和DeepSeek-R1的訓(xùn)練,,取得了顯著成果。他們在AIME基準(zhǔn)上實現(xiàn)了33.3%的準(zhǔn)確率,在AMC上為62.5%,,在MATH上為77.2%,。這一表現(xiàn)不僅超越了Qwen2.5-Math-7B-Instruct,還能與使用更多數(shù)據(jù)和復(fù)雜組件的PRIME和rStar-MATH相媲美,。他們使用純PPO方法訓(xùn)練Qwen2.5-7B-SimpleRL-Zero,,并采用MATH數(shù)據(jù)集中的8K樣本。Qwen2.5-7B-SimpleRL則先進行Long CoT監(jiān)督微調(diào),,再進行強化學(xué)習(xí),。兩種方法都只使用相同的8K MATH樣本。在第44步時,,模型出現(xiàn)了自我反思能力,,并表現(xiàn)出更長的CoT推理能力。

HuggingFace團隊也宣布復(fù)刻DeepSeek R1的所有流程,,并將所有訓(xùn)練數(shù)據(jù)和腳本開源。項目命名為Open R1,,發(fā)布一天內(nèi)獲得了超過1.9k星標(biāo)和142個fork,。DeepSeek的成功使其成為美國頂尖高校研究人員的首選模型,甚至取代了一些人對ChatGPT的需求,。這次,,中國AI確實震撼了世界。


00后夫妻過年各回各家 傳統(tǒng)與現(xiàn)代的碰撞

大衛(wèi)·林奇主義的飄散 好萊塢的損失與懷念

趙露思說暫時身上沒有賠款的項目,生病期間曾癱瘓不能說話

專家:月壤的重大發(fā)現(xiàn)是最幸福的事 研究成果登《科學(xué)》雜志

特朗普與洛杉磯市長爆發(fā)爭吵 煙霧問題引發(fā)激烈爭論

春節(jié)期間北京推出5600余場文旅活動 多彩活動迎新春

澤連斯基:只有讓烏克蘭參與談判,,特朗普才可能結(jié)束俄烏沖突 烏方強調(diào)自身角色

征兵到18歲,,最后一個烏克蘭人的時刻正式到來,!

美國已開始動用軍用飛機大規(guī)模驅(qū)逐移民 特朗普政策引發(fā)爭議

無憂傳媒稱:將徹查張大大霸凌事件

林語堂明快打字機曾被當(dāng)垃圾扔掉 美國網(wǎng)友地下室發(fā)現(xiàn)林語堂明快打字機
大衛(wèi)·林奇主義的飄散 好萊塢的損失與懷念

務(wù)工夫婦春節(jié)歸鄉(xiāng)談到家人眼含淚花 給親人買20余件新衣

實戰(zhàn)畫面揭示2000磅炸彈真實威力 十層高樓4秒鐘化為廢墟
中央氣象臺:寒潮向東推進東北地區(qū)現(xiàn)大暴雪 多地氣溫驟降風(fēng)力強勁

第9艘055大驅(qū)將首航 解放軍海軍東海南海實戰(zhàn)演訓(xùn) 強化臨戰(zhàn)演練

福奇被撤安全保護,?特朗普稱可自聘安保 引發(fā)爭議與關(guān)注

解放軍給全國人民拜年,身后漏出“國之重器” 展示反導(dǎo)實力

澤連斯基:美國對烏軍事援助并未停止 澄清傳言

春節(jié)檔電影神仙打架 預(yù)售票房刷新紀(jì)錄

美媒:特朗普下令終止為福奇提供聯(lián)邦安保 安全保護被撤

蛟龍行動預(yù)售票房破4000萬 映前熱度高漲

DeepSeek徹底爆發(fā) 性能卓越成本低

特朗普宣布“墨西哥灣“正式更名 更名為“美國灣”

王源新歌千秋一刻首發(fā) 明晚亮相河南春晚
趙露思說暫時身上沒有賠款的項目,,生病期間曾癱瘓不能說話
00后夫妻過年各回各家 傳統(tǒng)與現(xiàn)代的碰撞

美國已開始使用軍用飛機遣返非法移民 罕見動用軍機

歐洲央行行長開始挖墻腳:很多人才對美國幻滅了,,我們引進過來 歐洲經(jīng)濟或迎來轉(zhuǎn)機

氣勢拉滿!中國軍人的硬核拜年來了 福建艦官兵送祝福
春晚重慶分會場有門票,?謠言 警惕演唱會門票詐騙

特朗普下令終止為福奇提供聯(lián)邦安保 “他賺那么多錢 自己雇” 安保撤銷引發(fā)爭議

專家:俄烏局勢或變?yōu)檫厬?zhàn)邊談狀態(tài) 和平曙光初現(xiàn)

張大大涉毆打侮辱女員工,,將可能涉嫌多項罪名

一女子掃共享單車后手機被偷,北京警方刑拘8人
相關(guān)新聞
起底讓硅谷難安的DeepSeek 引發(fā)全球AI界風(fēng)暴
DeepSeek 給硅谷帶來的震撼持續(xù)不斷,。與幾個月前《黑神話·悟空》在歐美受到的追捧相比,,DeepSeek 的出現(xiàn)可謂石破天驚,充滿了各種不可能和不合理
2025-01-26 14:46:44起底讓硅谷難安的DeepSeekDeepSeek徹底爆發(fā) 性能卓越成本低
2025-01-26 15:56:02DeepSeek徹底爆發(fā)金價沉寂多日再創(chuàng)歷史新高 全球投資者聚焦貴金屬狂潮
2024-07-18 14:42:00金價沉寂多日再創(chuàng)歷史新高DeepSeek又有重大突破 開源大模型性能卓越
2025-01-21 22:05:22DeepSeek又有重大突破DeepSeek新模型“火”到海外 引發(fā)硅谷恐慌
短短一個月內(nèi),中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型:DeepSeek-V3和DeepSeek-R1
2025-01-26 15:51:02DeepSeek新模型火到海外DeepSeek讓Meta深陷恐慌 中國AI逆襲硅谷
短短一個月內(nèi),,中國AI初創(chuàng)公司深度求索(DeepSeek)發(fā)布了兩款大模型——DeepSeek-V3和DeepSeek-R1
2025-01-26 10:34:01DeepSeek讓Meta深陷恐慌








