AMD能否在AI芯片領(lǐng)域與英偉達(dá)抗衡 瞄準(zhǔn)推理市場(chǎng)突破口

在人工智能芯片的競(jìng)爭(zhēng)中,,英偉達(dá)憑借其強(qiáng)大的技術(shù)實(shí)力和完整的生態(tài)系統(tǒng),,構(gòu)筑了難以逾越的壁壘。然而,,隨著AI應(yīng)用場(chǎng)景的擴(kuò)展,,特別是在推理階段的需求爆發(fā),,AMD等競(jìng)爭(zhēng)者正在尋找突破口。
最新消息顯示,,AMD利用DeepSeek模型走紅的機(jī)會(huì),,宣布將新的DeepSeek-V3模型集成到Instinct MI300X GPU上。這一集成旨在與SGLang配合使用,,以實(shí)現(xiàn)最佳性能,。DeepSeek-V3專門針對(duì)AI推理進(jìn)行了優(yōu)化,表明AMD正在積極布局AI應(yīng)用落地場(chǎng)景,。
這種合作反映了AI行業(yè)格局的變化,。過去兩年,大模型的訓(xùn)練需求主導(dǎo)了算力市場(chǎng),,英偉達(dá)憑借CUDA生態(tài)和H100系列GPU占據(jù)絕對(duì)優(yōu)勢(shì),。但隨著大模型進(jìn)入應(yīng)用落地階段,推理需求激增,,企業(yè)更關(guān)注成本,、能效和部署靈活性。AMD瞄準(zhǔn)這一窗口期,,試圖通過優(yōu)化推理性能打破英偉達(dá)的壟斷,。
AMD的Instinct MI300X是其AI戰(zhàn)略的核心武器。這款采用Chiplet設(shè)計(jì)的GPU集成1460億晶體管,,配備192GB HBM3內(nèi)存,,專為大規(guī)模AI推理設(shè)計(jì),。據(jù)AMD數(shù)據(jù),MI300X的推理性能較英偉達(dá)H100提升30%,,內(nèi)存帶寬達(dá)5.3TB/s,,尤其擅長(zhǎng)實(shí)時(shí)對(duì)話、圖像生成等低延遲任務(wù),。不過,,MI300X面臨生態(tài)短板和產(chǎn)能瓶頸兩大挑戰(zhàn)。
英偉達(dá)的CUDA生態(tài)已形成近乎壟斷的開發(fā)者壁壘,,全球90%的AI框架依賴其工具鏈,。盡管AMD推出開源的ROCm平臺(tái)并適配PyTorch、TensorFlow,,但遷移成本高,、社區(qū)支持不足的問題依然突出。例如,,Meta雖采用MI300X運(yùn)行Llama 3.1模型的推理任務(wù),,但訓(xùn)練階段仍依賴英偉達(dá)芯片。此外,,2023年底臺(tái)積電先進(jìn)封裝產(chǎn)能緊張導(dǎo)致MI300X交付延遲,,部分客戶轉(zhuǎn)投英偉達(dá),也暴露出AMD在供應(yīng)鏈管理上的脆弱性,。
為應(yīng)對(duì)挑戰(zhàn),,AMD加速硬件迭代并強(qiáng)化生態(tài)合作。2024年6月,,AMD推出了升級(jí)版的MI325X芯片,,這款產(chǎn)品采用了8個(gè)計(jì)算芯片、4個(gè)I/O芯片和8個(gè)內(nèi)存芯片的復(fù)雜設(shè)計(jì),,通過2.5D和3D封裝技術(shù)實(shí)現(xiàn)整合,。在性能方面,MI325X提供了1.3petaFLOPS的BF/FP16性能,,或2.6petaFLOPS的FP8性能,,超過了英偉達(dá)的H200。特別是在內(nèi)存容量上,,MI325X配備了288GB的HBM3e內(nèi)存,,是H200的兩倍多,,內(nèi)存帶寬達(dá)到6TB/S,。

周深佩戴珠寶細(xì)節(jié) 舞臺(tái)形象引熱議
網(wǎng)傳陳曉凈身出戶 十年情路終落幕
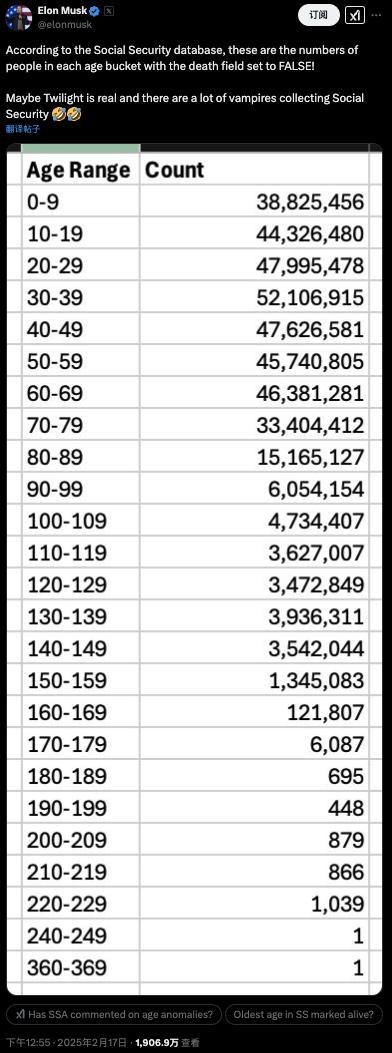
馬斯克聲稱發(fā)現(xiàn)360歲老人 數(shù)據(jù)異常引爭(zhēng)議

恭喜!國(guó)乒24歲新星戀情曝光 甜蜜合影引關(guān)注

特朗普批波音總統(tǒng)專機(jī)還沒造好 項(xiàng)目拖延引不滿

韓國(guó)空姐打開應(yīng)急艙門站機(jī)翼上自拍 爭(zhēng)議舉動(dòng)惹眾怒
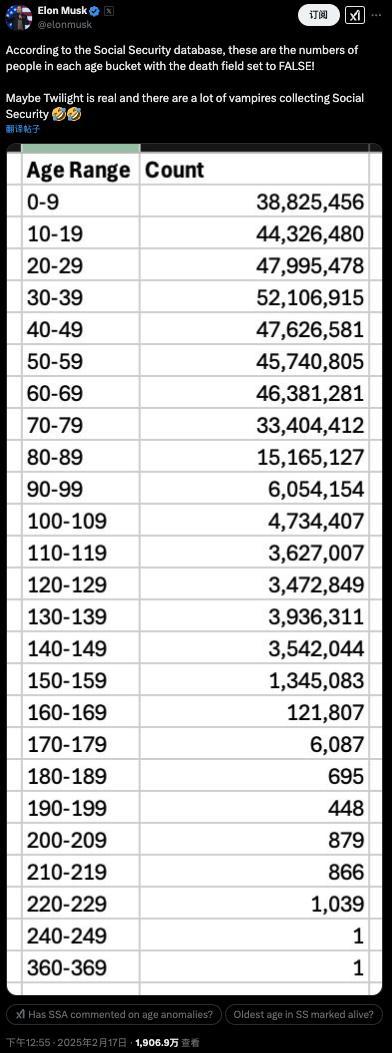
馬斯克查賬“美國(guó)社?!?,稱發(fā)現(xiàn)360歲老人,?

臺(tái)北市議員:特朗普想要臺(tái)積電的命 擔(dān)憂核心技術(shù)外流
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

“廿二做三事,不富也平安”,,明日正月廿二 金佛下凡祈福日
周深佩戴珠寶細(xì)節(jié) 舞臺(tái)形象引熱議

上海多地驚現(xiàn)南美“巨型老鼠” 生態(tài)危機(jī)引關(guān)注

澤連斯基將到訪沙特 不參與美俄會(huì)談

“最沒含金量”的世界冠軍,,偷走了假賽主播的人生?

伊朗:反對(duì)外國(guó)勢(shì)力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

俄代表:歐盟英國(guó)“完全不守信用” 質(zhì)疑其未來協(xié)議參與資格

男子撞勞斯萊斯逃逸車損預(yù)估20多萬
未參與美俄談判 烏克蘭被美拋棄了嗎 烏方未受邀參會(huì)引發(fā)猜測(cè)

多名官員被解雇后起訴美政府 裁員爭(zhēng)議升級(jí)
陳曉陳妍希情史回顧 九年婚姻終落幕

“一二三四五......”司機(jī)見中草藥包變10萬現(xiàn)金驚住了

12.4億美元買“酒”,!巴菲特,,釋放了什么信號(hào)? 加碼消費(fèi)股布局

藝人王大陸因涉嫌逃兵役被逮捕,,將送新北檢
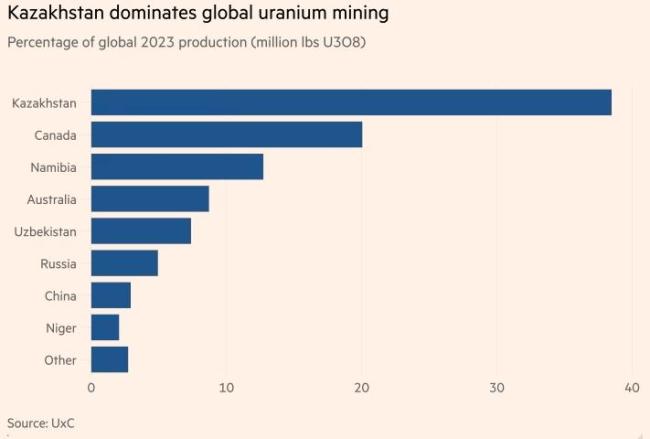
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了

當(dāng)DeepSeek開始教人買房,,中介的飯碗還端得住嗎?
中國(guó)經(jīng)濟(jì)2025年第一份“體檢報(bào)告”
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭(zhēng)議

美客機(jī)翻覆現(xiàn)場(chǎng)視頻曝光 惡劣天氣或成事故主因

美國(guó)翻臉后,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)
網(wǎng)傳陳曉凈身出戶 十年情路終落幕
馬斯克聲稱發(fā)現(xiàn)360歲老人 數(shù)據(jù)異常引爭(zhēng)議

為了增加軍費(fèi),,英國(guó)公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計(jì)劃陷入僵局

中國(guó)導(dǎo)演20萬美元拍出北美短劇第一 刷新票房紀(jì)錄

美國(guó)新版“空軍一號(hào)”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度

歐洲的安全,,還是美國(guó)的利益,?美俄談判前夕,歐洲被邊緣化引發(fā)擔(dān)憂
相關(guān)新聞
消息稱美國(guó)司法部已對(duì)英偉達(dá)在 AI 領(lǐng)域主導(dǎo)地位升級(jí)反壟斷調(diào)查 壟斷陰影下的AI芯片巨頭
2024-09-05 14:03:31消息稱美國(guó)司法部已對(duì)英偉達(dá)在英偉達(dá)回應(yīng)AI芯片推遲發(fā)布 設(shè)計(jì)缺陷引關(guān)注
AI芯片領(lǐng)域的領(lǐng)軍企業(yè)英偉達(dá)就近期關(guān)于其AI芯片延期發(fā)布的傳言進(jìn)行了回應(yīng)
2024-08-04 21:05:19英偉達(dá)回應(yīng)AI芯片推遲發(fā)布英偉達(dá)市值逼近全球第一蘋果 AI芯片需求激增
2024-10-22 11:51:00英偉達(dá)市值逼近全球第一蘋果分析師:英偉達(dá)就像高中時(shí)的詹姆斯,AI領(lǐng)域的絕對(duì)王者
2024-09-02 17:00:27分析師:英偉達(dá)就像高中時(shí)的詹姆斯誰能成為英偉達(dá)平替,?AI芯片新秀崛起挑戰(zhàn)巨人
2024-09-23 15:31:00誰能成為英偉達(dá)平替,?微軟今年買了48.5萬顆英偉達(dá)AI芯片 領(lǐng)先競(jìng)爭(zhēng)對(duì)手
2024-12-19 16:22:38微軟今年買了48








