媒體:DeepSeek不需要被神話 理性看待其成就

1月27日,,DeepSeek AI智能助手登上中美iOS免費(fèi)應(yīng)用排行榜榜首,,這是中國(guó)應(yīng)用首次取得這一成績(jī),。與此同時(shí),,與該公司相關(guān)的多個(gè)詞條進(jìn)入微博熱搜,,其中一條是“DeepSeek徹底爆發(fā)”,。這背后反映了開(kāi)源模型追趕甚至超越閉源模型的情緒,。
事實(shí)上,,DeepSeek在這幾天并沒(méi)有特別的動(dòng)作,將其推上輿論中心的力量主要來(lái)自Meta,。三天前,,在美國(guó)匿名職場(chǎng)社區(qū)teamblind上,有Meta員工表示,,DeepSeek的低成本訓(xùn)練工作讓Meta的生成式AI團(tuán)隊(duì)感到恐慌,,工程師們正努力分析DeepSeek,試圖從中復(fù)制任何可能的東西,。隨后,,Meta首席人工智能科學(xué)家楊立昆在X平臺(tái)上表示,對(duì)于認(rèn)為“中國(guó)在人工智能領(lǐng)域正在超越美國(guó)”的人,,正確的看法是“開(kāi)源模型正在超越閉源模型”,。
DeepSeek并不是突然崛起,。從DeepSeek-V2開(kāi)始,這家公司已被硅谷視為一股神秘力量,。它在國(guó)內(nèi)大模型行業(yè)率先發(fā)起了一場(chǎng)真正意義上的“降價(jià)潮”,,憑借“MoE+MLA”架構(gòu)創(chuàng)新實(shí)現(xiàn)了成本降低。近期熱議的原因在于它在過(guò)去一個(gè)月內(nèi)相繼發(fā)布了DeepSeek-V3和R1兩款大模型產(chǎn)品,。
2024年底,,DeepSeek發(fā)布新一代MoE模型DeepSeek-V3,擁有6710億參數(shù),,激活參數(shù)為370億,,在14.8萬(wàn)億token上進(jìn)行了預(yù)訓(xùn)練。V3在知識(shí)類任務(wù)上接近當(dāng)前表現(xiàn)最好的Claude-3.5-Sonnet-1022,,在代碼能力上稍好于后者,,并且在數(shù)學(xué)能力上領(lǐng)先其他開(kāi)閉源模型。更重要的是,,DeepSeek-V3的總訓(xùn)練成本僅為557.6萬(wàn)美元,,完整訓(xùn)練消耗了278.8萬(wàn)個(gè)GPU小時(shí),幾乎是同等性能水平模型所需成本的十分之一,。
一周前,,DeepSeek發(fā)布了推理模型R1,其性能對(duì)齊OpenAI-o1正式版,,并同步開(kāi)源模型權(quán)重,。R1在多項(xiàng)任務(wù)上與OpenAI-o1-1217基本持平,尤其在AIME 2024,、MATH-500,、SWE-Bench Verified三項(xiàng)測(cè)試集上以微弱優(yōu)勢(shì)取勝。此外,,R1還開(kāi)源了僅通過(guò)強(qiáng)化學(xué)習(xí)訓(xùn)練的大語(yǔ)言模型R1-Zero,,盡管沒(méi)有人類監(jiān)督數(shù)據(jù)介入,但該模型足以對(duì)標(biāo)OpenAI-o1-0912,,探索出僅通過(guò)強(qiáng)化學(xué)習(xí)就能獲得推理能力的技術(shù)可能性,。

金價(jià)連漲7周后“跳水” 金店再現(xiàn)買金熱

美航司客機(jī)事故乘客拍下逃生瞬間 加拿大:事發(fā)時(shí)風(fēng)力強(qiáng)勁

私家車占人行道家長(zhǎng)擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球

武漢一培訓(xùn)機(jī)構(gòu)請(qǐng)千名學(xué)生看哪吒2 放松身心緩解壓力
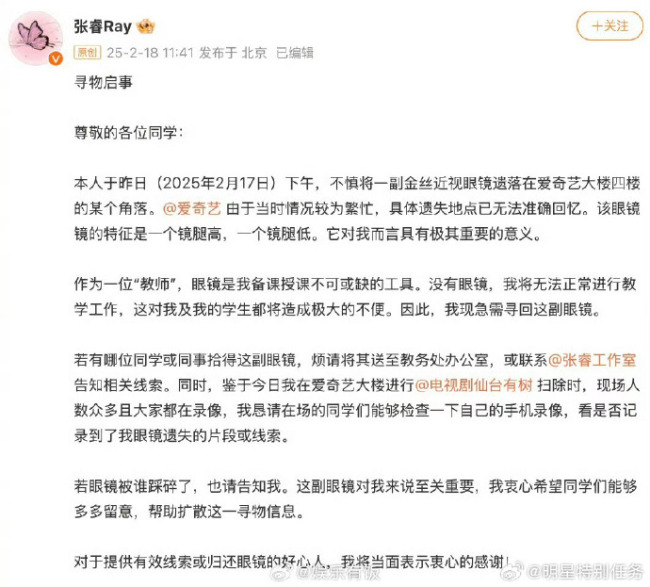
張睿發(fā)尋物啟事找眼鏡,張睿沒(méi)眼鏡上不了課

網(wǎng)紅高收入合理嗎,?顧茜茜稱每天躺賺30萬(wàn)是氣話
私家車占人行道家長(zhǎng)擔(dān)憂孩子走車道 社區(qū)回應(yīng):將安裝U型桿或石球

特朗普批波音總統(tǒng)專機(jī)還沒(méi)造好 項(xiàng)目拖延引不滿
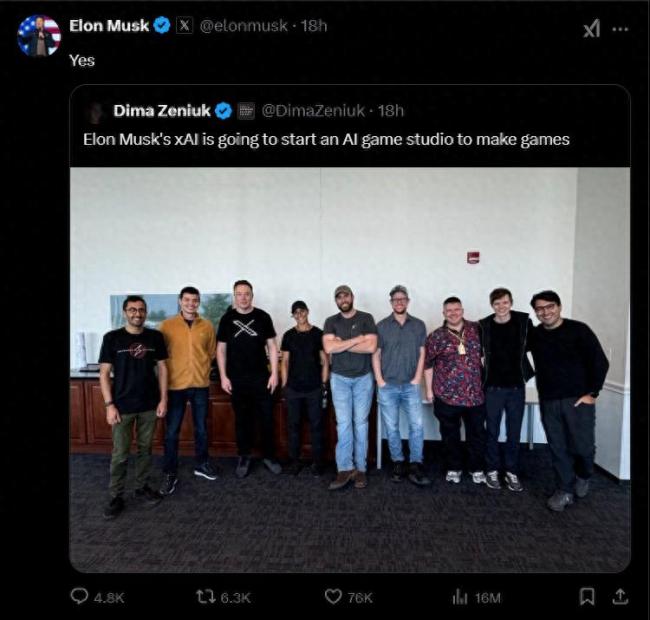
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

伊朗:反對(duì)外國(guó)勢(shì)力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

美為何提議從中國(guó)向?yàn)跖汕簿S和人員 美國(guó)的奇葩主意

三亞招募100名旅游體驗(yàn)官 提升服務(wù)質(zhì)量與游客滿意度

美國(guó)翻臉后,,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對(duì)三大危機(jī)

今日雨水節(jié)氣,老傳統(tǒng)“吃二樣,,做二事,,忌二事” 千年習(xí)俗的智慧
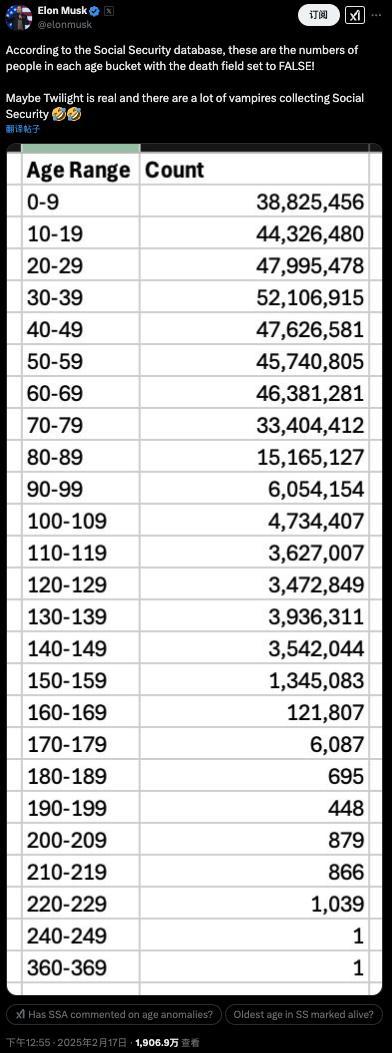
馬斯克查賬“美國(guó)社保”,稱發(fā)現(xiàn)360歲老人,?
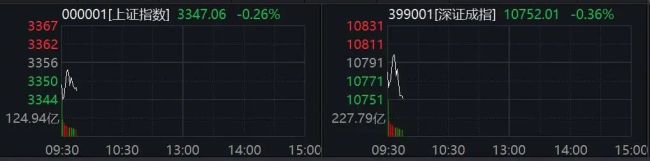
光線傳媒再度巨震 高位人氣股走弱

美客機(jī)翻覆現(xiàn)場(chǎng)視頻曝光 惡劣天氣或成事故主因
美航司客機(jī)事故乘客拍下逃生瞬間 加拿大:事發(fā)時(shí)風(fēng)力強(qiáng)勁
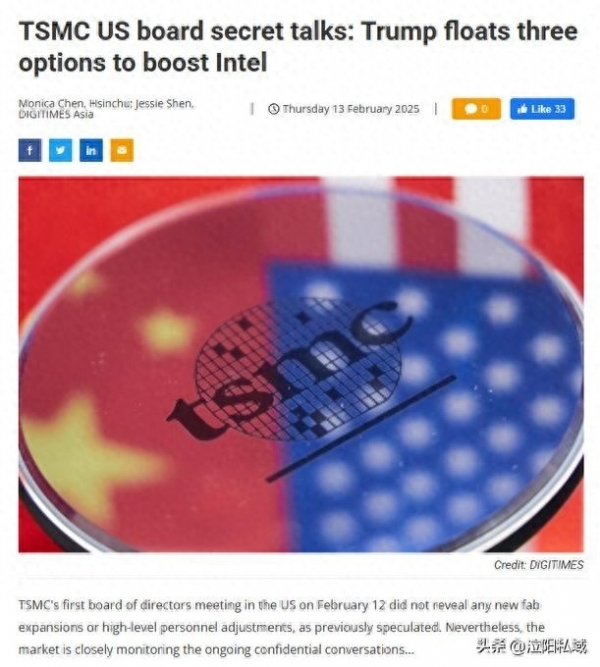
媒體批特朗普又一次“搶劫”臺(tái)灣 美國(guó)的真實(shí)意圖暴露

觀察:2025年的Mini LED電視市場(chǎng),,怎么打? 三大競(jìng)爭(zhēng)焦點(diǎn)浮現(xiàn)

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈
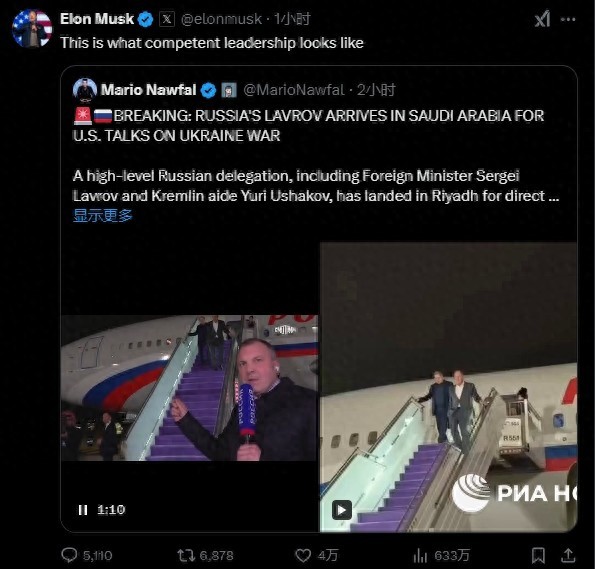
美俄談判今日開(kāi)始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭(zhēng)議

美國(guó)新版“空軍一號(hào)”再度延期交付 供應(yīng)鏈問(wèn)題拖累進(jìn)度

哪吒2主創(chuàng)團(tuán)隊(duì)已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章

烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅(jiān)決立場(chǎng)
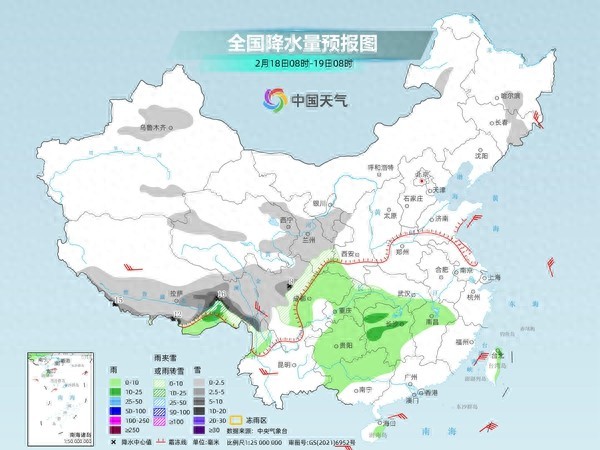
未來(lái)三天南方陰雨濕冷感明顯 北方降水增多

歐洲的安全,,還是美國(guó)的利益,?美俄談判前夕,歐洲被邊緣化引發(fā)擔(dān)憂
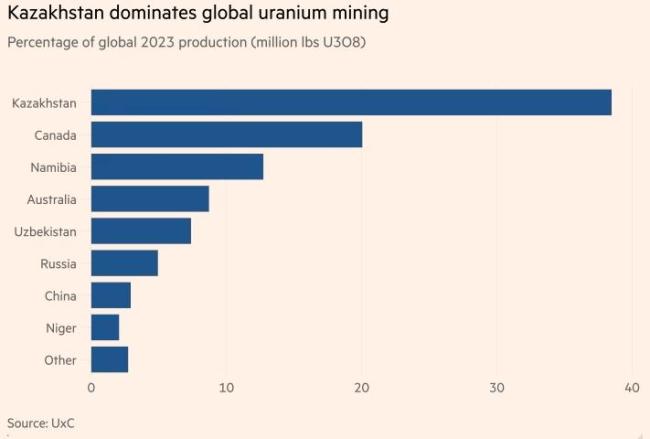
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了

曝王大陸涉嫌逃兵役被捕

黑中介騙取巨額服務(wù)費(fèi)被公訴 虛假承諾誘騙客戶

以民眾持續(xù)抗議要求政府維持?;?呼吁釋放被扣押人員

為了增加軍費(fèi),英國(guó)公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計(jì)劃陷入僵局

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問(wèn)題
金價(jià)連漲7周后“跳水” 金店再現(xiàn)買金熱

澤連斯基將到訪沙特 不參與美俄會(huì)談
相關(guān)新聞
紐約時(shí)報(bào)等媒體被“趕出”五角大樓 為其他媒體騰空間
特朗普政府于1月31日晚宣布,,要求包括《紐約時(shí)報(bào)》在內(nèi)的四家媒體從他們?cè)谖褰谴髽堑膶S棉k公場(chǎng)所撤走,。此舉的理由是為其他媒體騰出空間
2025-02-02 09:15:45紐約時(shí)報(bào)等媒體被趕出五角大樓媒體:油價(jià)下跌重新開(kāi)始
媒體:油價(jià)下跌重新開(kāi)始今早油價(jià)實(shí)現(xiàn)了2024年的第9次油價(jià)上調(diào),部分地區(qū)95號(hào)汽油漲回8元時(shí)代,。
2024-10-25 16:33:43媒體:油價(jià)下跌重新開(kāi)始16歲以下禁用社交媒體,!澳社交媒體未阻未成年或被罰5000萬(wàn)
2024-11-29 11:00:12澳社交媒體未阻未成年或被罰5000萬(wàn)媒體:造車很苦 不能亂來(lái)
2024-08-23 09:38:53媒體:造車很苦習(xí)近平在秘魯媒體發(fā)表署名文章
2024-11-14 18:00:15習(xí)近平在秘魯媒體發(fā)表署名文章媒體:富士康為何又回鄭州了,?
2024-08-14 20:20:25媒體:富士康為何又回鄭州了