DeepSeek為何在美國引起巨大關(guān)注 打破大模型壟斷

這幾天,,中國人工智能初創(chuàng)公司DeepSeek在美區(qū)下載榜上超越了ChatGPT,,還引發(fā)多個美國科技股股價暴跌。美國總統(tǒng)特朗普稱DeepSeek的出現(xiàn)“給美國相關(guān)產(chǎn)業(yè)敲響了警鐘”,。
DeepSeek用較少的資金實現(xiàn)了與世界頂尖大模型如GPT-4相媲美的性能,。OpenAI訓(xùn)練ChatGPT-4的成本高達(dá)7800萬美元甚至可能達(dá)到1億美元,而DeepSeek的大模型訓(xùn)練成本不到600萬美元,,僅為同性能模型的5%到10%,。新模型訓(xùn)練方法大幅降低了大模型行業(yè)的入局門檻,使得大規(guī)模預(yù)訓(xùn)練不再是科技巨頭的專利,。此外,,在模型推理層面,DeepSeek推出的DeepSeek-R1價格為2.2美元/百萬詞元,,而同性能的OpenAI-o1價格為60美元/百萬詞元,,前者僅為后者的三十分之一。這種低成本顯著改善了大模型的應(yīng)用成本,,對科研,、企業(yè)等智力密集型產(chǎn)業(yè)具有重大價值。因此,,無論是從基礎(chǔ)研究角度還是商業(yè)層面上看,,DeepSeek對美國一些大模型公司的既有模式構(gòu)成了沖擊。
DeepSeek開發(fā)成本大幅降低的原因在于其應(yīng)用了不同的模型訓(xùn)練模式,,打破了美國堆砌算力的方式,。在數(shù)據(jù)喂養(yǎng)這一重要環(huán)節(jié)上,OpenAI選擇了“人海戰(zhàn)術(shù)”,,通過海量數(shù)據(jù)投喂提升能力,。而DeepSeek則利用算法對數(shù)據(jù)進(jìn)行總結(jié)和分類,經(jīng)過選擇性處理后再輸送給大模型,,從而優(yōu)化了算力并降低了成本,。目前來看,Meta耗費(fèi)大量資金訓(xùn)練Llama,,但效果不如成本極低的DeepSeek,。這引發(fā)了Meta高層和技術(shù)人員的恐慌,他們擔(dān)心自己的技術(shù)能力和創(chuàng)新性被質(zhì)疑,,從而失去工作,。社交媒體上的討論也顯示,關(guān)于DeepSeek的帖子數(shù)量遠(yuǎn)高于新聞報道,,且討論時間早于新聞媒體五天,,這主要是由從事科技工作的自媒體人和員工圈層傳播所致。
根據(jù)中國工業(yè)互聯(lián)網(wǎng)研究院發(fā)布的《人工智能大模型年度發(fā)展趨勢報告》,,2024年國內(nèi)大模型的能力進(jìn)步顯著,。從2023年第四季度到2025年第一季度的測評顯示,國內(nèi)外大模型能力差距縮小了將近75%,。這表明DeepSeek的出現(xiàn)是中國國內(nèi)大模型整體發(fā)展的階段性成果,。盡管中國在AI領(lǐng)域的投資額僅為美國的十一分之一,但在未來仍有很大的發(fā)展空間,。
如今,,許多業(yè)內(nèi)人士都喊出了“DeepSeek接班OpenAI”的口號。事實上,,DeepSeek的出現(xiàn)并不是要取代其他公司,,而是提出了更多樣化的方案,打破了國際主流大模型的市場壟斷,,在大模型的發(fā)展道路上提供了不同于西方的中國解法,,向世界展示了在大模型領(lǐng)域不僅僅只有拼算力一條路,再次證明了中國智慧的價值,。

烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅決立場
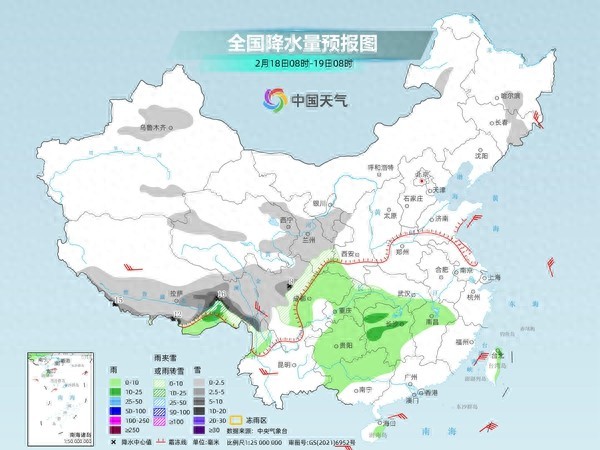
未來三天南方陰雨濕冷感明顯 北方降水增多

武漢一培訓(xùn)機(jī)構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力

網(wǎng)紅高收入合理嗎,?顧茜茜稱每天躺賺30萬是氣話
武漢一培訓(xùn)機(jī)構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力

以民眾持續(xù)抗議要求政府維持停火 呼吁釋放被扣押人員

美為何提議從中國向烏派遣維和人員 美國的奇葩主意

為了增加軍費(fèi),,英國公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,歐洲派兵計劃陷入僵局

美客機(jī)翻覆現(xiàn)場視頻曝光 惡劣天氣或成事故主因
烏方將不承認(rèn)美俄談判達(dá)成的協(xié)議 澤連斯基堅決立場

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈

申公豹的結(jié)巴能矯正嗎 口吃并非無法改善
媒體批特朗普又一次“搶劫”臺灣 美國的真實意圖暴露

歐洲的安全,,還是美國的利益?美俄談判前夕,,歐洲被邊緣化引發(fā)擔(dān)憂
馬斯克坐實AI游戲工作室計劃 讓游戲再次偉大
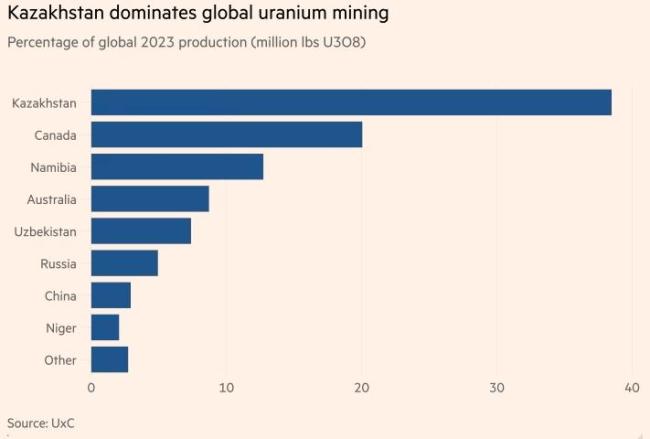
哈薩克斯坦鈾出口重心東移 哈鈾售中俄后致歐美快斷供了
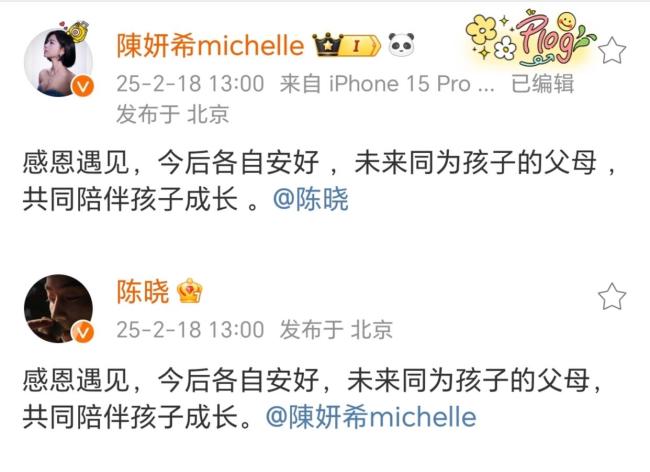
陳曉陳妍希 今后各自安好 感恩遇見共伴成長

美國新版“空軍一號”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度
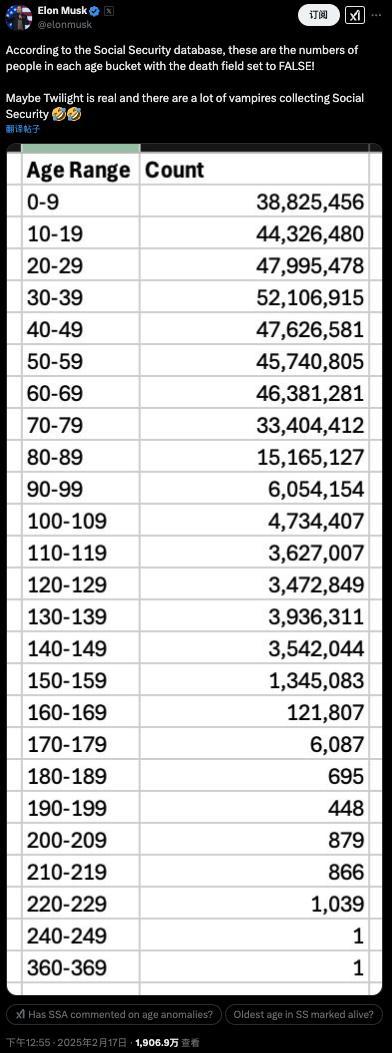
馬斯克查賬“美國社?!保Q發(fā)現(xiàn)360歲老人,?
未來三天南方陰雨濕冷感明顯 北方降水增多

賴志光任廣東惠州公安局局長 新任副市長兼公安局長

章昊直播時模仿徐冬冬姿勢

哪吒2主創(chuàng)團(tuán)隊已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章

美國翻臉后,,歐洲從“夸夸其談的少年”走向獨立成熟要做三件事 應(yīng)對三大危機(jī)

澤連斯基將到訪沙特 不參與美俄會談

伊朗:反對外國勢力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

網(wǎng)曝河北邢臺一局長酒后砸店傷人 當(dāng)?shù)丶o(jì)委介入調(diào)查

暴雪《守望先鋒》國服明日回歸,!中國主題四大天王皮膚來了 國服專屬福利揭曉

特朗普批波音總統(tǒng)專機(jī)還沒造好 項目拖延引不滿

波蘭外長:在黃油和槍炮間很難選擇 歐洲需加強(qiáng)國防開支
安徽一車墜河4人遇難 事故仍在調(diào)查處理中

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題
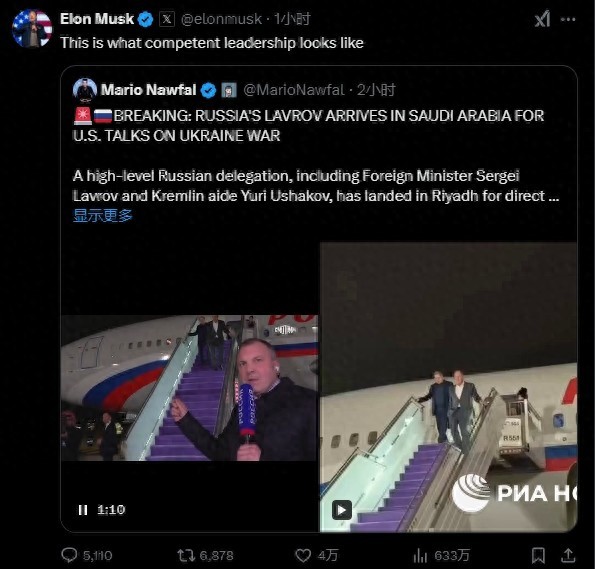
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭議
光線傳媒再度巨震 高位人氣股走弱

三亞招募100名旅游體驗官 提升服務(wù)質(zhì)量與游客滿意度
相關(guān)新聞
為何說DeepSeek改變了AI的投資邏輯 低成本高效引發(fā)資本關(guān)注
國產(chǎn)AI公司深度求索(DeepSeek)的出現(xiàn)不僅成為科技圈焦點,也引起了資本市場的廣泛關(guān)注,,并且還在不斷擴(kuò)展影響力
2025-02-08 07:58:52為何說DeepSeek改變了AI的投資邏輯一夜間DeepSeek在美國刷屏 “這是在做空英偉達(dá)嗎,?
2025-01-26 09:52:37一夜間DeepSeek在美國刷屏DeepSeek融資,?梁文鋒“打太極” 估值分歧巨大
2025-02-14 14:18:12DeepSeek融資日本人怎么看DeepSeek 低成本高性能引關(guān)注
2025-02-16 19:49:12日本人怎么看DeepSeekAI大??ㄅ廖魇①滵eepSeek 強(qiáng)化學(xué)習(xí)展現(xiàn)巨大潛力
2025-02-13 12:54:17AI大??ㄅ廖魇①滵eepSeekDeepSeek正在招人 高薪崗位引關(guān)注
2025-02-04 22:53:47DeepSeek正在招人








