DeepSeek能讓機(jī)器人“看穿”世界嗎 改變AI競爭格局

中國大模型技術(shù)和產(chǎn)業(yè)鏈的發(fā)展速度顯著,,Deepseek和阿里巴巴在開源方面已經(jīng)領(lǐng)先Meta,成為全球開源領(lǐng)域的佼佼者,。目前,,國內(nèi)發(fā)布的推理模型效果基本與o1持平,盡管仍弱于o3,,但技術(shù)路線已經(jīng)走通,追上甚至趕超只是時間問題,。
DeepSeek的崛起為中國掌握下一代行業(yè)標(biāo)準(zhǔn)提供了機(jī)會,,甚至可能使美國的芯片禁令變得無效。關(guān)于DeepSeek是否能改變?nèi)駻I競爭格局的問題,,AGI短期內(nèi)不會實(shí)現(xiàn),,至少十年內(nèi)不會有全知全能的模型出現(xiàn)。因此,,各行業(yè)仍然需要根據(jù)具體需求定制多種模型,。訓(xùn)練模型的主要成本在于預(yù)訓(xùn)練階段,而后續(xù)訓(xùn)練階段的成本相對較低,。
傳統(tǒng)SFT階段,,模型只能從標(biāo)注樣本中學(xué)習(xí)知識,效果一般且容易過擬合,。DeepSeek V3開創(chuàng)了一種新范式:資金雄厚且具有理想主義色彩的公司可以訓(xùn)練更大更好的模型并開源,。各行業(yè)利用這些模型蒸餾出專用模型,再進(jìn)行微調(diào)或直接調(diào)用API,。這樣,,整個行業(yè)形成了一條分工協(xié)作的產(chǎn)業(yè)鏈,上下游企業(yè)各司其職,,發(fā)揮各自的優(yōu)勢,。
算力瓶頸問題也可以通過這種方式解決,因?yàn)橹挥写竽P皖A(yù)訓(xùn)練階段最消耗算力,,即使通過非常規(guī)手段也能應(yīng)對,。DeepSeek關(guān)聯(lián)公司杭州深度求索人工智能基礎(chǔ)技術(shù)研究有限公司注冊資本1000萬元,法定代表人裴湉,,由寧波程恩企業(yè)管理咨詢合伙企業(yè)持股99%,,梁文鋒持股1%。
DeepSeek不僅完全開源,,還放出了詳細(xì)的技術(shù)報(bào)告,,并開源了最大671B R1模型及多個尺寸的蒸餾模型,,采用寬松的MIT License協(xié)議,,允許任何人免費(fèi)使用、修改,、分發(fā),包括商業(yè)用途,。這種開放性使其受到廣泛支持,被譽(yù)為真正的OpenAI,。
DeepSeek的訓(xùn)練成本也出乎意料地低,,總訓(xùn)練成本僅為557.6萬美元。這使得其在大模型市場上的邏輯發(fā)生了根本變化,,過去認(rèn)為非常燒錢的事情現(xiàn)在變得不再那么昂貴。此外,,DeepSeek模型性能強(qiáng)大,在某些評測中甚至超越了GPT-4o和o1,。考慮到其免費(fèi)使用和低廉的API價(jià)格,,綜合用戶成本來看,,體驗(yàn)達(dá)到T1級別。
DeepSeek來自幻方量化而非傳統(tǒng)互聯(lián)網(wǎng)大廠,,更具理想主義氣息,。創(chuàng)始人梁文鋒近期備受關(guān)注,他的言論被逐字解讀,,增加了討論熱度,。相比之下,DeepSeek商業(yè)氣息較少,,更像是一個小而美的研究機(jī)構(gòu),。
美國明確表示要挑起AI競賽,特朗普宣布5000億美元投資星際之門計(jì)劃,,意圖遏制中國AI發(fā)展。在這種背景下,,中國企業(yè)推出DeepSeek,對國內(nèi)來說是振奮人心的消息,。DeepSeek不僅降低了訓(xùn)練成本,還在一定程度上削弱了對高性能顯卡的依賴,,這對美國來說難以接受,。未來,全世界的工程師可能會從Qwen和DeepSeek開始學(xué)習(xí)大模型,,或許這將是中國公司首次掌握互聯(lián)網(wǎng)基建標(biāo)準(zhǔn)的機(jī)會,。

武漢一培訓(xùn)機(jī)構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力

三亞招募100名旅游體驗(yàn)官 提升服務(wù)質(zhì)量與游客滿意度

哪吒2主創(chuàng)團(tuán)隊(duì)已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章

美國翻臉后,歐洲從“夸夸其談的少年”走向獨(dú)立成熟要做三件事 應(yīng)對三大危機(jī)
光線傳媒再度巨震 高位人氣股走弱

為了增加軍費(fèi),,英國公共服務(wù)部門被曝準(zhǔn)備削減11%的預(yù)算,,歐洲派兵計(jì)劃陷入僵局

賴志光任廣東惠州公安局局長 新任副市長兼公安局長

歐洲的安全,,還是美國的利益,?美俄談判前夕,歐洲被邊緣化引發(fā)擔(dān)憂

波蘭外長:在黃油和槍炮間很難選擇 歐洲需加強(qiáng)國防開支
美俄談判今日開始 澤連斯基:不承認(rèn) 烏克蘭缺席引發(fā)爭議

美客機(jī)翻覆現(xiàn)場視頻曝光 惡劣天氣或成事故主因
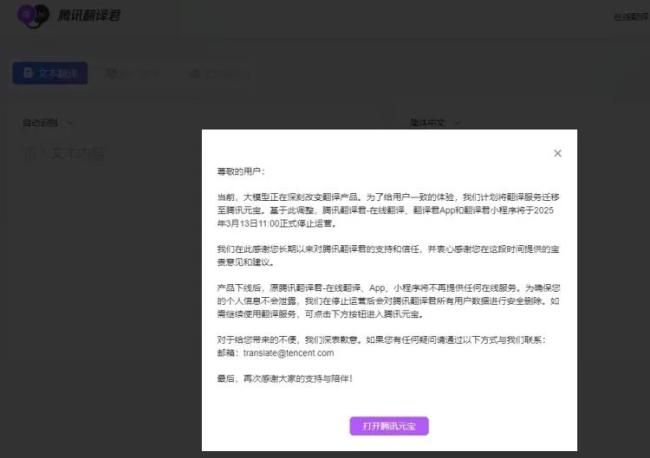
突然宣布:騰訊一產(chǎn)品即將停止運(yùn)營 服務(wù)遷移至騰訊元寶
安徽一車墜河4人遇難 事故仍在調(diào)查處理中
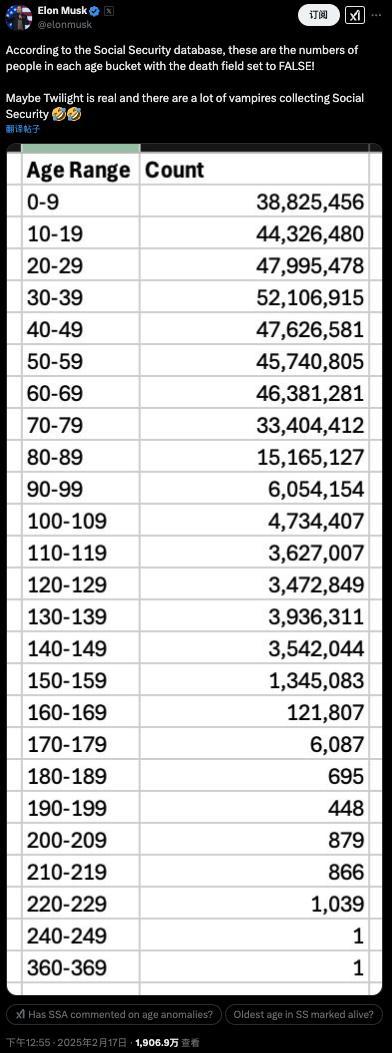
馬斯克查賬“美國社?!?,稱發(fā)現(xiàn)360歲老人?

暴雪《守望先鋒》國服明日回歸,!中國主題四大天王皮膚來了 國服專屬福利揭曉
三亞招募100名旅游體驗(yàn)官 提升服務(wù)質(zhì)量與游客滿意度
馬斯克坐實(shí)AI游戲工作室計(jì)劃 讓游戲再次偉大

22日起哪吒2港澳地區(qū)全面上映 兩地首映儀式相繼舉行
武漢一培訓(xùn)機(jī)構(gòu)請千名學(xué)生看哪吒2 放松身心緩解壓力
哪吒2主創(chuàng)團(tuán)隊(duì)已進(jìn)入新創(chuàng)作周期 續(xù)寫神話新篇章

澤連斯基將到訪沙特 不參與美俄會談

曾被雷軍千萬年薪挖角,!親屬稱羅福莉與丈夫研究領(lǐng)域相同

網(wǎng)紅高收入合理嗎?顧茜茜稱每天躺賺30萬是氣話

伊朗:反對外國勢力干涉敘利亞 支持?jǐn)⑷嗣褡詻Q權(quán)

章昊直播時模仿徐冬冬姿勢

申公豹的結(jié)巴能矯正嗎 口吃并非無法改善

大V:歐洲和烏克蘭遭受三次沉重打擊 西方暴露三大問題

美為何提議從中國向?yàn)跖汕簿S和人員 美國的奇葩主意

網(wǎng)曝河北邢臺一局長酒后砸店傷人 當(dāng)?shù)丶o(jì)委介入調(diào)查
媒體批特朗普又一次“搶劫”臺灣 美國的真實(shí)意圖暴露

拉夫羅夫抵達(dá)沙特 單手揣兜下飛機(jī) 談判桌上的博弈

特朗普批波音總統(tǒng)專機(jī)還沒造好 項(xiàng)目拖延引不滿

以民眾持續(xù)抗議要求政府維持?;?呼吁釋放被扣押人員
陳曉陳妍希 今后各自安好 感恩遇見共伴成長

美國新版“空軍一號”再度延期交付 供應(yīng)鏈問題拖累進(jìn)度
相關(guān)新聞
人造肌肉仿生機(jī)器人來了 最接近《西部世界》的人形機(jī)器人
2024-10-29 07:46:50人造肌肉仿生機(jī)器人來了世界機(jī)器人大會映射經(jīng)濟(jì)發(fā)展“新動力”
2024-08-31 09:33:03世界機(jī)器人大會映射經(jīng)濟(jì)發(fā)展“新動力”DeepSeek沒能讓算力焦慮消失 國產(chǎn)算力迎來利好
2025-02-11 08:24:36DeepSeek沒能讓算力焦慮消失王毅:世界現(xiàn)代化不能讓任何一國掉隊(duì)
當(dāng)?shù)貢r間9月25日,,中共中央政治局委員、外交部長王毅在紐約聯(lián)合國總部出席“全球發(fā)展倡議支持全球南方-中國在行動”主題發(fā)布活動,。
2024-09-27 11:12:48王毅:世界現(xiàn)代化不能讓任何一國掉隊(duì)Nature:世界科學(xué)家涌向DeepSeek 廉價(jià)強(qiáng)大模型引關(guān)注
2025-01-31 11:45:58Nature3分鐘看懂為什么DeepSeek能震驚世界 低成本高效率引發(fā)全球關(guān)注
2025-01-29 18:00:323分鐘看懂為什么DeepSeek能震驚世界