DeepSeek婉拒所有采訪專(zhuān)注研發(fā) 引發(fā)OpenAI緊急應(yīng)對(duì)(2)

V3模型的性能提升顯著,,但在AI快速迭代的背景下,,半年前的技術(shù)已顯得陳舊,。隨著時(shí)間推移,用更少的計(jì)算資源實(shí)現(xiàn)相當(dāng)或更強(qiáng)的性能成為行業(yè)趨勢(shì),。例如,現(xiàn)在可以在普通筆記本電腦上運(yùn)行的小型模型能達(dá)到與GPT-3相當(dāng)?shù)男阅芩?,而后者在發(fā)布時(shí)需要超級(jí)計(jì)算機(jī)進(jìn)行訓(xùn)練,。
DeepSeek的獨(dú)特之處在于他們率先實(shí)現(xiàn)了成本和性能的突破。雖然開(kāi)源模型權(quán)重的做法已有先例,,但DeepSeek的成就仍然顯著,。預(yù)計(jì)到今年年底,相關(guān)成本可能還會(huì)進(jìn)一步下降5倍左右,。
R1能夠達(dá)到與o1相當(dāng)?shù)男阅芩?,關(guān)鍵在于新的“推理”范式。這種范式通過(guò)合成數(shù)據(jù)生成和后訓(xùn)練強(qiáng)化學(xué)習(xí)提升推理能力,,使得以更低成本獲得快速進(jìn)展成為可能,。然而,R1在許多場(chǎng)景下表現(xiàn)不如o1,。OpenAI最近發(fā)布的o3測(cè)試結(jié)果顯示,,其性能提升幾乎呈垂直上升趨勢(shì)。
谷歌推出的Gemini Flash 2.0 Thinking在基準(zhǔn)測(cè)試中表現(xiàn)優(yōu)于R1,,具有很強(qiáng)的穩(wěn)定性,。盡管如此,DeepSeek憑借快速行動(dòng),、充足資金,、卓越智慧和明確目標(biāo),,在競(jìng)爭(zhēng)中超越了Meta等科技巨頭,。
DeepSeek的多Token預(yù)測(cè)技術(shù)和混合專(zhuān)家模型架構(gòu)顯著提高了訓(xùn)練和推理效率。這些創(chuàng)新引起了西方實(shí)驗(yàn)室的關(guān)注,。RL在R1中的應(yīng)用也起到了重要作用,,使其在格式化和安全性方面表現(xiàn)出色。通過(guò)合成數(shù)據(jù)集微調(diào),,R1的推理能力得以自然涌現(xiàn),。
MLA技術(shù)顯著降低了DeepSeek模型的推理成本,減少了每次查詢所需的KV緩存量,,從而降低運(yùn)營(yíng)成本,。由于H20芯片的高內(nèi)存帶寬和容量,DeepSeek在推理工作負(fù)載方面獲得了更多效率提升,。
R1并未真正動(dòng)搖o1的技術(shù)優(yōu)勢(shì),,而是以更低的成本實(shí)現(xiàn)了相似的性能。這種現(xiàn)象符合市場(chǎng)邏輯,類(lèi)似于半導(dǎo)體制造業(yè)的發(fā)展模式,。率先突破新能力層次的公司將獲得顯著的價(jià)格溢價(jià),,而追趕者只能獲得適度利潤(rùn)。DeepSeek通過(guò)零利潤(rùn)率策略打破了OpenAI的高利潤(rùn)率格局,,但這是否可持續(xù)仍存疑,。未來(lái),計(jì)算資源的集中度將變得更加重要,。

《北上》觀眾口碑出爐 收視率亮眼引發(fā)熱議

東契奇為歐文祈禱 傷病牽動(dòng)人心

深圳連發(fā)四份重磅文件 布局AI與機(jī)器人產(chǎn)業(yè)

誰(shuí)來(lái)承擔(dān)烏克蘭安全保障 美烏礦產(chǎn)協(xié)議引爭(zhēng)議

從小鮮肉,,到苦大仇深的小老頭,澤連斯基是這三年里老得最快的人

英首相辦公室:對(duì)加沙援助不能受阻 呼吁持續(xù)?;?/a>

默森質(zhì)疑阿森納勝埃因霍溫能力 攻擊火力成疑

代表建議在全國(guó)推行春秋假 緩解假日旅游潮汐效應(yīng)

拜仁不再給基米希漲薪和簽字費(fèi) 監(jiān)事會(huì)決定不變

專(zhuān)家:烏克蘭最大優(yōu)勢(shì)是頑強(qiáng) 堅(jiān)韌面對(duì)挑戰(zhàn)

加元墨西哥比索跌至一個(gè)月新低 關(guān)稅風(fēng)暴沖擊匯市
《北上》觀眾口碑出爐 收視率亮眼引發(fā)熱議

吳彥祖首公開(kāi)洛杉磯新家 融合五行元素
臺(tái)學(xué)者:解放軍實(shí)彈演習(xí)越來(lái)越近

俄稱結(jié)束沖突是一個(gè)艱難的過(guò)程 俄方揭西方陣營(yíng)裂痕

英法支持烏克蘭能否替代美國(guó)援助 歐洲奪回和談主導(dǎo)權(quán)
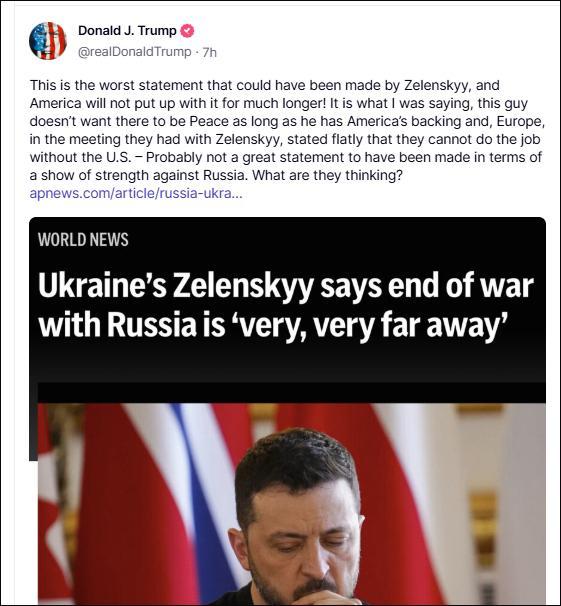
美政府被曝已暫停向?yàn)蹩颂m輸送武器 援助凍結(jié)引發(fā)擔(dān)憂
你以為胸悶只是小事,?其實(shí)可能是心臟在預(yù)警! 了解背后的大隱患
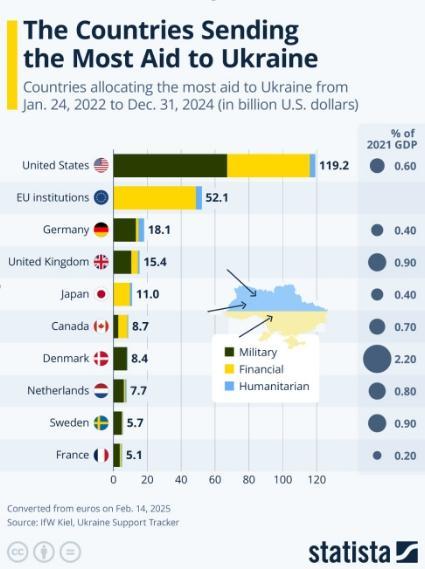
美斷供若歐洲砸錢(qián) 烏能堅(jiān)持下去嗎

羅馬主帥拉涅利被罰款2萬(wàn)歐元 批評(píng)裁判遭罰

菲律賓一架FA50戰(zhàn)機(jī)夜間失聯(lián) 搜救行動(dòng)進(jìn)行中

加拿大將只能靠烏克蘭難民抵御美國(guó)擴(kuò)張
東契奇為歐文祈禱 傷病牽動(dòng)人心

埃梅里:勝利是結(jié)果不是目標(biāo) 專(zhuān)注過(guò)程迎接挑戰(zhàn)
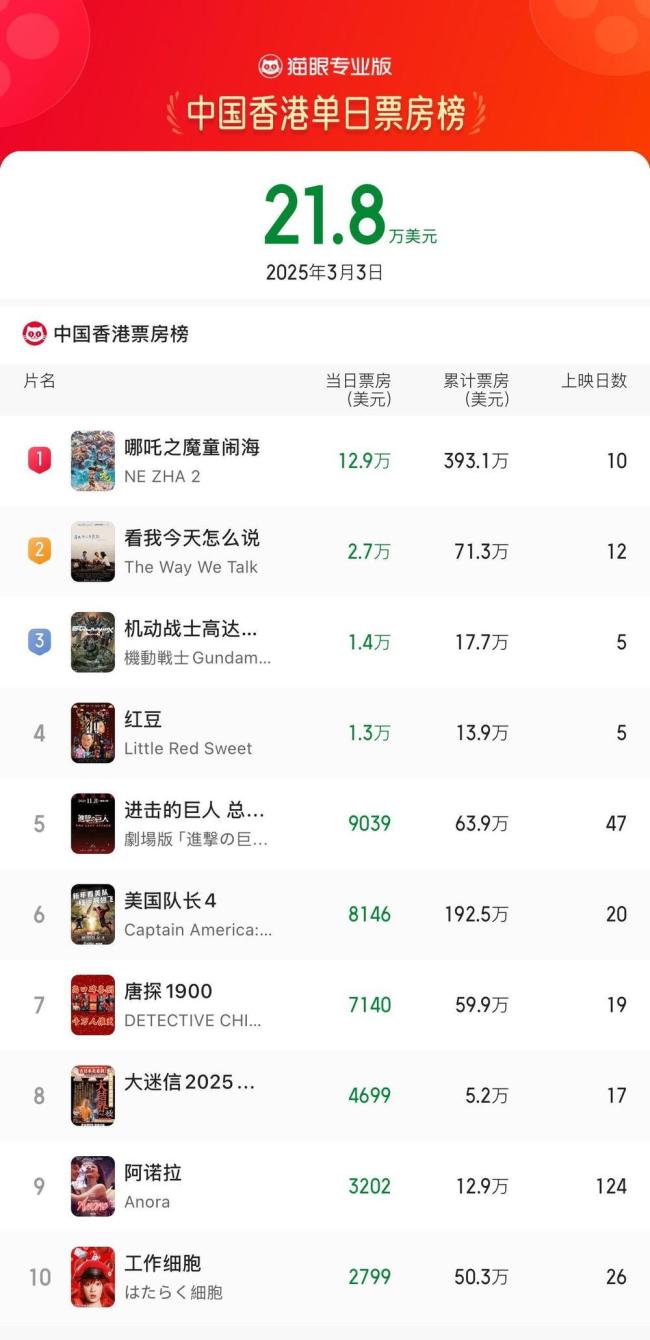
《哪吒2》成香港票房最高內(nèi)地電影 連續(xù)10天登頂票房榜

祖沖之三號(hào)再次打破紀(jì)錄 超導(dǎo)量子計(jì)算新突破

代表建議在全國(guó)推行“春秋假” 緩解假日旅游潮汐效應(yīng)

伊爾迪茲:球迷渴望勝利很正常 保持出色表現(xiàn)

交警暴雪疏導(dǎo)車(chē)輛一夜凍成“雪人” 寒潮下的堅(jiān)守

建議回收動(dòng)力電池緩解進(jìn)口依賴 推動(dòng)規(guī)范運(yùn)營(yíng)

美“援烏資金”至少70%被留美國(guó)

反馬斯克浪潮席卷全美:政府效率部引爆社會(huì)裂痕

中國(guó)國(guó)防費(fèi)連續(xù)9年個(gè)位數(shù)增長(zhǎng) 占比低于世界平均水平

庫(kù)爾德工人黨會(huì)對(duì)土耳其政府服軟嗎 厄賈蘭呼吁解散組織
深圳連發(fā)四份重磅文件 布局AI與機(jī)器人產(chǎn)業(yè)
相關(guān)新聞
哪吒創(chuàng)作團(tuán)隊(duì)停止所有對(duì)外采訪 專(zhuān)注作品本身
2025-02-19 21:11:04哪吒創(chuàng)作團(tuán)隊(duì)停止所有對(duì)外采訪《哪吒》創(chuàng)作團(tuán)隊(duì)停止所有對(duì)外采訪 專(zhuān)注作品本身
2025-02-19 21:08:21哪吒創(chuàng)作團(tuán)隊(duì)停止所有對(duì)外采訪王大雷慘敗后婉拒采訪 心態(tài)崩潰拒絕發(fā)聲
2024-09-09 09:18:05王大雷慘敗后婉拒采訪DeepSeek明確對(duì)商業(yè)化不感興趣 專(zhuān)注技術(shù)研究
2025-02-11 08:46:45DeepSeek明確對(duì)商業(yè)化不感興趣為何是DeepSeek殺出重圍 專(zhuān)注技術(shù)而非商業(yè)化
2025-02-11 09:43:21為何是DeepSeek殺出重圍李行亮團(tuán)隊(duì)稱不方便回應(yīng) 婉拒媒體采訪
2024-12-03 08:16:05李行亮團(tuán)隊(duì)稱不方便回應(yīng)








