本地化部署DeepSeek是智商稅嗎 改變AI格局的力量(2)

然而,,大模型“六小虎”面臨的行業(yè)質(zhì)疑再度抬頭,。一年前,,這些初創(chuàng)企業(yè)還被資本選中要跟OpenAI打擂臺,,但現(xiàn)在他們在影響力,、技術(shù)認(rèn)可度和用戶規(guī)模等方面全面落后。
DeepSeek的影響廣泛,,既是對手的威脅,,也是行業(yè)的東風(fēng)。它已成為2025年的絕對主角,。
在今年的達(dá)沃斯論壇上,,許多人向Fusion Fund創(chuàng)始合伙人張璐打聽起DeepSeek。這家公司成立于2023年,,脫胎于知名量化基金幻方量化,,目前未進(jìn)行任何外部融資。創(chuàng)始人梁文鋒自去年年中起,,憑借DeepSeek-V2在MLA等方面的創(chuàng)新得到了業(yè)內(nèi)認(rèn)可,,被視為一股“來自東方的神秘力量”。
DeepSeek最近發(fā)布的V3和R1成為轉(zhuǎn)折點(diǎn),。特別是R1完全復(fù)現(xiàn)了OpenAI o1推理模型能力,,并且完全免費(fèi)。DeepSeek的創(chuàng)新包括模型壓縮,、多頭潛在注意力機(jī)制,、混合專家模型和FP8混合精度訓(xùn)練等技術(shù)。硅谷的華人工程師們對此表示佩服,。
DeepSeek掀起的“AI降本浪潮”使得大家都能以更低的成本開發(fā)大模型,。據(jù)官方論文介紹,DeepSeek訓(xùn)練V3模型的成本約為557.6萬美元,,而Llama-3.1的訓(xùn)練成本高達(dá)數(shù)億美元,。華爾街再次對AI算力泡沫心生恐慌,擔(dān)心未來DeepSeek的低成本模式一旦推廣,科技公司是否還需要大量購入英偉達(dá)先進(jìn)的AI芯片支持模型開發(fā),?
盡管如此,,英偉達(dá)強(qiáng)調(diào)DeepSeek的進(jìn)步不僅不意味著算力過剩,反而證明市場需要更多AI芯片,。事實(shí)上,,微軟、亞馬遜,、Meta,、谷歌等巨頭都大幅增加了2025年的資本開支,重點(diǎn)投資數(shù)據(jù)中心等AI基建項(xiàng)目,。
此外,,DeepSeek的創(chuàng)新對國產(chǎn)算力芯片也是一大利好。比如FP8混合精度算力訓(xùn)練方法在一定程度上彌補(bǔ)了國內(nèi)芯片硬件性能的不足,,提供了更多軟件算法的創(chuàng)新空間,。
DeepSeek的成功也影響了國內(nèi)的大模型創(chuàng)業(yè)公司,如“六小虎”,。這些公司在技術(shù)創(chuàng)新,、產(chǎn)品認(rèn)知和企業(yè)影響力方面面臨巨大壓力。一些公司甚至調(diào)整了項(xiàng)目的優(yōu)先級,,以應(yīng)對DeepSeek的競爭,。
許多公司開始接入DeepSeek模型,包括云廠商,、芯片廠商和其他大模型同行,。騰訊元寶也在自有混元大模型的情況下接入了DeepSeek R1。AI產(chǎn)業(yè)鏈的東風(fēng)已至,,更多的下游應(yīng)用公司也將搭上這股東風(fēng),,例如教育公司、證券行業(yè)和手機(jī)廠商,。
DeepSeek的成功啟示了更多公司,,尤其是在算法架構(gòu)和工程上的創(chuàng)新。未來,,更多公司將利用開源大模型以低成本服務(wù)市場,,催生大量獨(dú)立小廠的機(jī)會。完全自動化而非co-pilot模式的應(yīng)用場景潛力更加突出,。市場已經(jīng)傳出DeepSeek正在以80億美元估值融資的消息,,投資者將目光轉(zhuǎn)向AI產(chǎn)業(yè)鏈的其他變革機(jī)會。

中國首個(gè)“星際礦工”誕生 太空資源開發(fā)邁出關(guān)鍵一步

一組“腿腳操”給血管減齡,,讓血管重返年輕態(tài),!
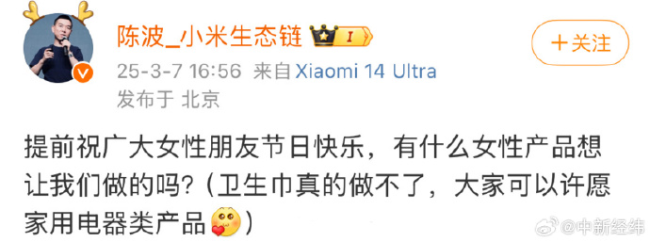
小米高管刪除“不做衛(wèi)生巾”博文 衛(wèi)生巾質(zhì)量問題引熱議

澤連斯基重申不承認(rèn)被占領(lǐng)土屬于俄 堅(jiān)定立場不變

伊朗回應(yīng)美國:勿再做以色列幫兇 堅(jiān)決反對美軍空襲
一組“腿腳操”給血管減齡,,讓血管重返年輕態(tài)!

俄羅斯會否兩手準(zhǔn)備以戰(zhàn)促談,,談不攏就開打?

新款iPad側(cè)面印中國制造 字樣位置變化引關(guān)注

業(yè)內(nèi):這些城市“小陽春”初現(xiàn) 樓市成交回暖
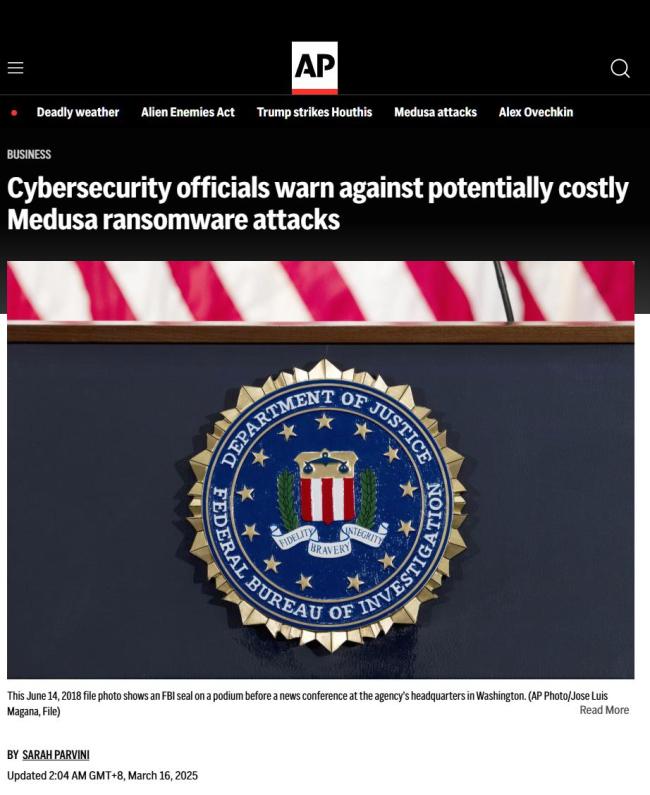
FBI等部門警告:美數(shù)百用戶已遭“美杜莎”勒索軟件攻擊,,威脅范圍正在擴(kuò)大

特朗普為何冒險(xiǎn)空襲胡塞 向伊朗發(fā)出警告信號

機(jī)器人跳斧頭幫舞蹈致敬《功夫》 AI合成引發(fā)熱議

匈總理要求歐盟不讓烏克蘭加入 歐爾班提出12點(diǎn)要求
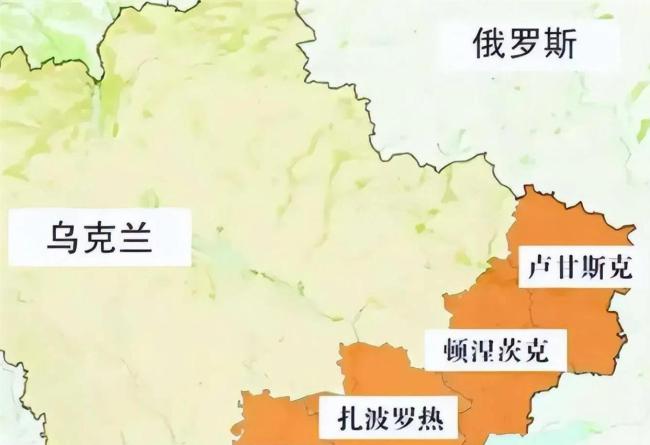
美方再次施壓烏克蘭割地 談判僵局難解

Jonathan‘s 11 Years,loewe創(chuàng)意總監(jiān)離任

國際資本對俄資產(chǎn)“蠢蠢欲動” 押注制裁解除
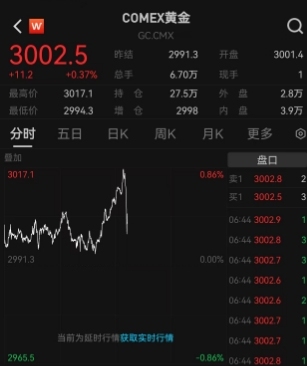
再創(chuàng)歷史新高的黃金還能接著漲嗎 三大驅(qū)動力推動金價(jià)飆升

“用了18枚導(dǎo)彈”,!美國航母突然遭襲 胡塞武裝誓言報(bào)復(fù)

特朗普轟炸也門是地緣政治秀嗎 戰(zhàn)爭背后的深層邏輯
FBI等部門警告:美數(shù)百用戶已遭“美杜莎”勒索軟件攻擊,!

資通電軍是干什么的 網(wǎng)絡(luò)攻擊與滲透真相
中國首個(gè)“星際礦工”誕生 太空資源開發(fā)邁出關(guān)鍵一步

莫迪對華最新表態(tài):確保分歧不會演變成爭端,進(jìn)行“健康且自然”的競爭 強(qiáng)調(diào)對話解決問題

縣醫(yī)院招保安要求35歲以下大專以上 回應(yīng):屬實(shí),!
小米高管刪除“不做衛(wèi)生巾”博文 衛(wèi)生巾質(zhì)量問題引熱議

英國邀20國派兵烏克蘭有何意味 歐洲戰(zhàn)略自主的嘗試

匈總理要求歐盟不讓烏克蘭加入 向歐盟提出十二項(xiàng)要求

學(xué)者解讀特朗普下令空襲胡塞武裝 意在向伊朗發(fā)出警告

事關(guān)和平協(xié)議 俄堅(jiān)持要求烏做到兩點(diǎn) 中立與拒入北約

醫(yī)院回應(yīng)1750元招保安要求35歲以下 高要求引發(fā)熱議

國乒大合影給受傷的王曼昱留了位置 團(tuán)隊(duì)溫暖細(xì)節(jié)感人

護(hù)士長路遇車禍上演教科書式救援 為患者爭取了寶貴的每一分每一秒

預(yù)測:菲律賓總統(tǒng)馬科斯的結(jié)局,,誰將笑到最后?

俄羅斯對?;馂楹渭确e極又謹(jǐn)慎 戰(zhàn)場形勢決定態(tài)度

烏在庫爾斯克作戰(zhàn)行動結(jié)束意味著啥 戰(zhàn)場失利與外部施壓交織
相關(guān)新聞
印度稱DeepSeek很快部署在當(dāng)?shù)胤?wù)器 符合數(shù)據(jù)本地化要求
2025-02-01 12:54:54印度稱DeepSeek很快部署在當(dāng)?shù)胤?wù)器醫(yī)用面膜是智商稅嗎 性價(jià)比引爭議
2024-10-30 14:31:00醫(yī)用面膜是智商稅嗎持續(xù)擴(kuò)容!至少16家券商完成DeepSeek本地化部署,,具體怎么應(yīng)用,? 大模型助力業(yè)務(wù)效率提升
近日,又有近10家券商宣布完成了DeepSeek-R1的本地化部署,。DeepSeek-R1是該系列模型的最新版本,。目前,至少有16家券商在探索DeepSeek模型的應(yīng)用
2025-02-10 10:50:23持續(xù)擴(kuò)容搶票神器是智商稅嗎 營銷噱頭暗藏陷阱
2025-01-23 07:41:10搶票神器是智商稅嗎水晶玄學(xué)屬性是智商稅嗎?取決于個(gè)人的看法和體驗(yàn)
2025-01-09 12:01:53水晶玄學(xué)屬性是智商稅嗎賣爆的AI玩具是智商稅嗎 智能對話引發(fā)熱議
2024-12-28 11:46:13賣爆的AI玩具是智商稅嗎








