DeepSeek開源第一彈:6小時收藏破5000次,,利好國產(chǎn)GPU,?加速大模型落地應(yīng)用

2月24日,DeepSeek啟動了“開源周”,,并開源了首個代碼庫FlashMLA。該代碼庫是針對Hopper GPU優(yōu)化的高效MLA解碼內(nèi)核,,專為處理可變長度序列設(shè)計,,現(xiàn)已投入生產(chǎn)使用。在H800 GPU上,,F(xiàn)lashMLA能實現(xiàn)3000 GB/s的內(nèi)存帶寬和580 TFLOPS的計算性能,。
簡單來說,F(xiàn)lashMLA是一種優(yōu)化方案,,使大語言模型在H800這樣的GPU上運行得更快,、更高效,特別適用于高性能AI任務(wù),。這一代碼能夠加速大語言模型的解碼過程,提高模型的響應(yīng)速度和吞吐量,,對于實時生成任務(wù)(如聊天機器人,、文本生成等)尤為重要。
MLA(多層注意力機制)是一種改進的注意力機制,,旨在提高Transformer模型在處理長序列時的效率和性能,。通過多個頭的并行計算,MLA讓模型能夠同時關(guān)注文本中不同位置和不同語義層面的信息,,從而更全面,、更深入地捕捉長距離依賴關(guān)系和復雜語義結(jié)構(gòu)。
此前,,有從業(yè)者解析DeepSeek架構(gòu)時提到,,MLA的本質(zhì)是對KV(Key-Value緩存機制)的有損壓縮,提高了存儲信息的效率,。這項技術(shù)首次在DeepSeek-V2中引入,目前是開源模型中顯著減小KV緩存大小的最佳方法之一,。
DeepSeek表示,,F(xiàn)lashMLA就像給AI推理引擎裝上了一臺“渦輪增壓器”,使大模型在處理復雜任務(wù)時更快,、更省資源,,并降低了技術(shù)門檻。FlashMLA的意義不僅在于技術(shù)優(yōu)化,,更是打破算力壟斷,、加速AI普及的關(guān)鍵一步。
具體來說,,F(xiàn)lashMLA可以突破GPU算力瓶頸,,降低成本。傳統(tǒng)解碼方法在處理不同長度的序列時,,GPU的并行計算能力會被浪費,,而FlashMLA通過動態(tài)調(diào)度和內(nèi)存優(yōu)化,使Hopper GPU(如H100)的算力得到充分利用,,相同硬件下吞吐量顯著提升,。這意味著企業(yè)可以用更少的GPU服務(wù)器完成同樣的任務(wù),直接降低推理成本,。
另一方面,F(xiàn)lashMLA可以推動大模型落地應(yīng)用?,F(xiàn)實場景中的可變長度序列(如聊天對話,、文檔生成)需要動態(tài)處理,但傳統(tǒng)方法需要填充到固定長度,,導致計算冗余,。FlashMLA支持動態(tài)處理變長輸入,,讓AI應(yīng)用(如客服機器人、代碼生成)響應(yīng)更快,、更流暢,,用戶體驗提升,加速商業(yè)化落地,。

美國多地龍卷風致40余人死亡 惡劣天氣威脅持續(xù)

清明節(jié)勞動節(jié)高速免費8天 自駕游福音

華為FreeBuds 6外觀參數(shù)提前曝光 音質(zhì)與降噪大升級
華為FreeBuds 6外觀參數(shù)提前曝光 音質(zhì)與降噪大升級

美國多地遭遇強風暴致40人死亡 白宮監(jiān)測災(zāi)情并準備援助
美國多地龍卷風致40余人死亡 惡劣天氣威脅持續(xù)

杜特爾特勸說女兒回國有何目的 政治局勢微妙變化

美財長稱無法保證美經(jīng)濟不會衰退 通脹與關(guān)稅政策引擔憂
韓國因何被美國“拉黑” 核想法惹的禍

也門民眾稱美軍襲擊不動搖挺巴決心 堅定支持巴勒斯坦

自駕“出逃”阿姨蘇敏說離婚心情很好:我徹底自由了,!

《五哈5》官宣回歸:老梗新玩,笑料升級,!

尹錫悅彈劾案或于本周后期宣判 憲院將做最終裁定

品牌方要求刪除惡意剪輯視頻 趙露思遭抹黑事件引關(guān)注

為何說杜特爾特可能有救了 中方揭露管轄漏洞

日本擬在九州率先部署遠程導彈 強化西南防衛(wèi)機制

90后女子辭去月薪8千工作轉(zhuǎn)行賣豬肉 努力實現(xiàn)杭州安家夢

母親偷簽3萬婚介合同,,未經(jīng)當事人同意有效嗎

英法堅持要向烏克蘭派駐部隊 歐洲內(nèi)部意見分歧嚴重

朝鮮譴責西方議論朝“棄核”問題

巴基斯坦一客車遇襲,已造成3名軍人2名平民死亡 3名恐怖分子被當場擊斃
清明節(jié)勞動節(jié)高速免費8天 自駕游福音

臺民調(diào):58%民眾反對大罷免 主流民意不贊成

遼寧省公安廳副廳長袁林履新 赴沈陽市政府任職

美官員:預計特朗普和普京本周將進行交談

3名網(wǎng)紅街頭拍低俗視頻被處罰 策劃擺拍引圍觀

提前17天集訓,,國腳們的狀態(tài)能保證嗎,?

網(wǎng)友到雷軍評論區(qū)許愿小米做衛(wèi)生巾 3·15晚會后呼聲再起

烏軍失守蘇賈后庫爾斯克的戰(zhàn)局如何 俄軍大踏步前進

“十八遇北風,,遍地起墳頭”,二月十八啥日子,?刮北風咋了,?

為引流造謠現(xiàn)場抓獲恐怖分子 貴州一男子被行政處罰
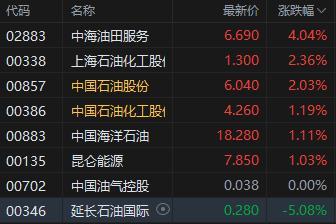
機構(gòu):油價或能企穩(wěn)并緩慢小幅回升 底部震蕩后有望回升

俄官員:30天?;鹛嶙h只是為烏軍提供喘息的機會 烏軍爭取時間重新部署

俄官員:30天停火提議只是為烏軍提供喘息的機會

伊朗譴責美國對胡塞武裝空襲 違反國際法
相關(guān)新聞
DeepSeek開源影響幾何,?掀起開源浪潮
2025-02-20 08:25:36DeepSeek開源影響幾何DeepSeek開源周第五天:開源3FS 數(shù)據(jù)訪問助推器發(fā)布
每經(jīng)AI快訊,2月28日,,DeepSeek開源周第五天,,DeepSeek在官方X賬號宣布開源3FS,它是所有Deepseek數(shù)據(jù)訪問的助推器
2025-02-28 11:52:14DeepSeek開源周第五天DeepSeek后又一大模型向全球開源 吉利貢獻開源力量
2025-02-19 08:09:19DeepSeek后又一大模型向全球開源DeepSeek又有重大突破 開源大模型性能卓越
DeepSeek發(fā)布了新一代開源大模型DeepSeek-R1,。該模型在數(shù)學、代碼、自然語言推理等任務(wù)上的性能與美國OpenAI公司的最新o1大模型相當
2025-01-21 22:05:22DeepSeek又有重大突破DeepSeek啟動“開源周” 推動AI技術(shù)革新
2025-02-24 18:17:43DeepSeek啟動開源周幻方DeepSeek如何“震驚”硅谷 性價比與開源的勝利
過去一周,,中國的人工智能大模型成為硅谷乃至全球科技界的熱議話題。引發(fā)這場討論的是中國人工智能初創(chuàng)公司深度求索(DeepSeek)
2025-01-27 10:02:46幻方DeepSeek如何震驚硅谷








