中國工程院院士與DeepSeek過了一招 AI發(fā)展路徑新思考(2)

第3波人工智能興起后,,美國政府,、AI龍頭企業(yè)和投資界認(rèn)為高算力是發(fā)展人工智能的關(guān)鍵。特朗普簽署法案啟動星際之門計劃,,投資5000億美元打造基礎(chǔ)設(shè)施,。然而,DeepSeek的成功揭示了真相,,即推理模型開發(fā)比想象中簡單,,各行各業(yè)都能參與。初生牛犢不怕虎的中國科技工作者戳破了紙老虎,,展示了其實力,。
2020年,OpenAI發(fā)表論文提出規(guī)模法則,,認(rèn)為增加模型規(guī)模,、數(shù)據(jù)量和計算資源可以顯著提升性能。但規(guī)模法則并非科學(xué)定律,,而是經(jīng)驗歸納,。近幾年大模型訓(xùn)練效果表明,要獲得線性增長需高指數(shù)性增加投入,,這種模式難以持久,。理查德·薩頓指出,雖然規(guī)模法則有效,,但它不是解決所有問題的萬能鑰匙,,AI系統(tǒng)還需具備持續(xù)學(xué)習(xí),、適應(yīng)環(huán)境等能力。
DeepSeek的出現(xiàn)迫使AI界重新思考技術(shù)路線:是繼續(xù)追求高算力還是在算法優(yōu)化上下功夫,?DeepSeek標(biāo)志著從外延式發(fā)展階段轉(zhuǎn)向集約化系統(tǒng)優(yōu)化階段,。盡管成功并未否定算力的重要性,但綠色發(fā)展和降低能耗成為重要目標(biāo),。
通用人工智能是一個模糊概念,,OpenAI追求的是多個領(lǐng)域處理復(fù)雜問題的能力。莫拉維克悖論指出,,復(fù)雜問題易解而簡單問題難解,。因此,學(xué)術(shù)界更關(guān)注智能系統(tǒng)的持續(xù)學(xué)習(xí)和自我改進(jìn)能力,。實現(xiàn)通用智能是漸進(jìn)過程,,不會因某項技術(shù)突然到來。
DeepSeek和OpenAI都以通用人工智能為目標(biāo),,但路徑不同,。OpenAI通過擴大模型規(guī)模希望先做出通用基礎(chǔ)模型再蒸餾出垂直模型。DeepSeek則走“由專到通”的道路,,通過模型算法和工程優(yōu)化探索受限資源下的通用智能。未來可能是通專融合,,形成智能時代產(chǎn)業(yè)新生態(tài),。
科技界公認(rèn)圖靈是人工智能奠基人,他提出了計算模擬人類智能的假說,。迄今為止,,人工智能成果離不開計算,但高算力是否本質(zhì)需求值得深思,。人腦高效低功耗是因為分布式模擬計算,。深度學(xué)習(xí)奠基人辛頓提出“凡人計算”,采用與人腦相同的存算一體模擬計算方式,,追求高算效和高能效,,這是正確方向。
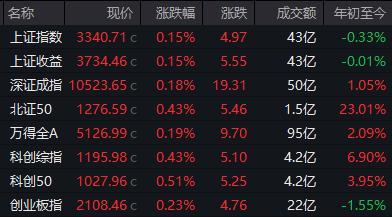
開盤:滬指漲0.15% 滬深兩市超3000股上漲
張國榮去世22周年 明星曬照緬懷

杜蘭特腳踝扭傷預(yù)計將缺席至少一周 太陽賽程艱難

騙子為洗錢全款買近8噸毛肚 新型洗錢手段曝光

大V談俄羅斯4萬噸準(zhǔn)航母曝光 中俄印態(tài)度各異

你平均一天走多少步 60歲后適宜步數(shù)探討,!

專家直播解讀解放軍臺島周邊演訓(xùn) 堅定捍衛(wèi)國家主權(quán)

臺媒稱7艘解放軍艦艇在臺海周邊活動 持續(xù)戰(zhàn)備警巡

現(xiàn)場:4名美軍士兵駕駛70噸重的裝甲車演習(xí)時陷入沼澤,,3人遇難1人失蹤!

緬甸領(lǐng)導(dǎo)人敏昂萊慰問中國救援醫(yī)療隊:感謝第一時間來緬提供幫助 查看搜救情況

緬甸地震的危害究竟有多大 次生災(zāi)害更令人擔(dān)憂

云南省第三批援緬物資起運 直抵地震重災(zāi)區(qū)

女生在線還原朋友摔倒過程 網(wǎng)友:這就是親生的閨蜜

俄戰(zhàn)機投3噸級炸彈轟炸烏軍 無掩護的士兵基本無法存活
特朗普不舍馬斯克任期將結(jié)束 稱贊其才華希望多留

電動車“消失”三天被藏山洞里 警方智破奇案

省委書記會見"全網(wǎng)最愛發(fā)錢老板" 共享發(fā)展紅利

新規(guī),!4月1日起實施,!自動駕駛迎來新機遇

中國出手!決定向緬甸提供1億元捐款,!

美國和伊朗開戰(zhàn)的可能性有多大 局勢升級引關(guān)注
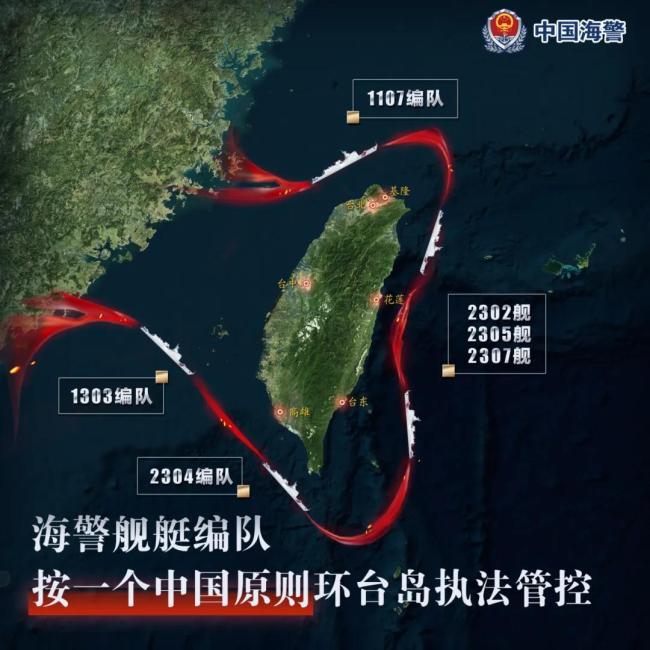
多支海警艦艇編隊位臺島周邊演練 依法管控實際行動
張國榮去世22周年 明星曬照緬懷
馬斯克的DOGE展開新一輪技術(shù)革新 硅谷邏輯重塑華盛頓

創(chuàng)新高,!金飾價格一夜瘋漲14元
杜蘭特腳踝扭傷預(yù)計將缺席至少一周 太陽賽程艱難

外媒:特朗普稱預(yù)計普京將在俄烏?;饏f(xié)議中“履行他的職責(zé)” 展現(xiàn)信心與期待

你敲了五聲我聽見了 被困者求生意志強烈回應(yīng)救援

臺防務(wù)部門:山東艦進(jìn)入臺灣所謂“應(yīng)變區(qū)” 啟動應(yīng)變機制嚴(yán)密監(jiān)控

大V:特朗普“百日訪華”計劃破產(chǎn) 沙特成首訪選擇
開盤:滬指漲0.15% 滬深兩市超3000股上漲
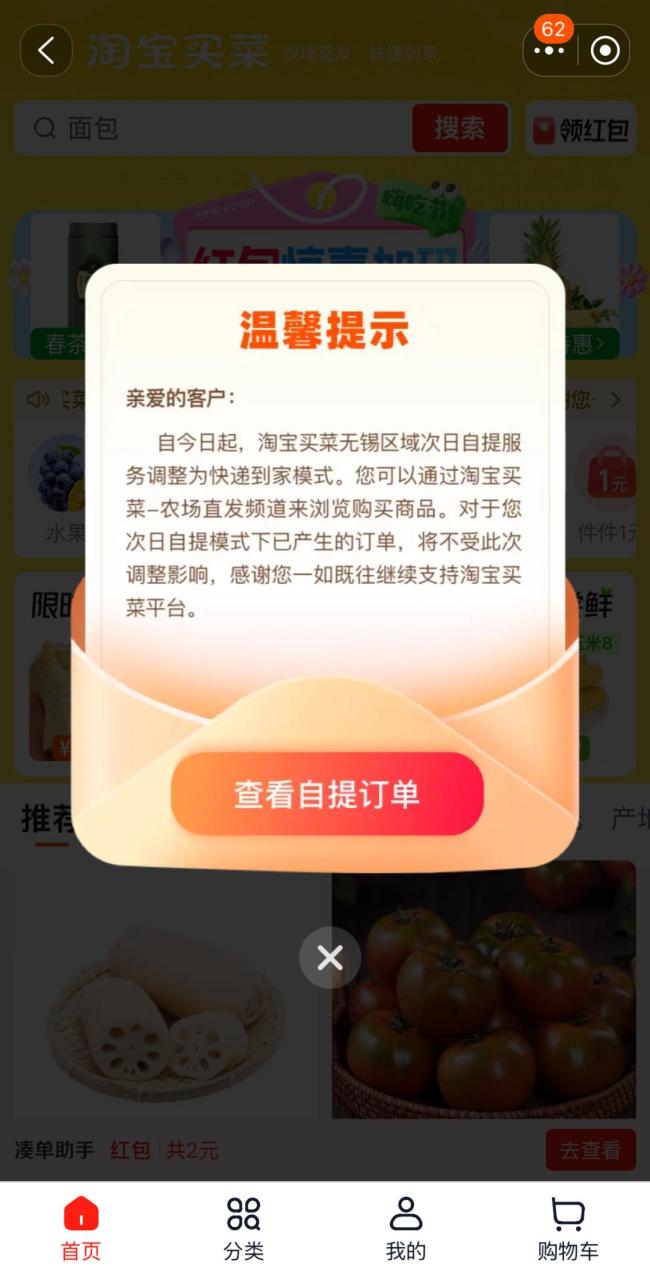
淘寶買菜次日達(dá)業(yè)務(wù)“急剎車”,,員工去年已預(yù)感風(fēng)險將至:賠N+1

甲亢哥吃四川火鍋 辣到上躥下跳!

中國在南海東部海域發(fā)現(xiàn)億噸級油田 展現(xiàn)深層勘探潛力
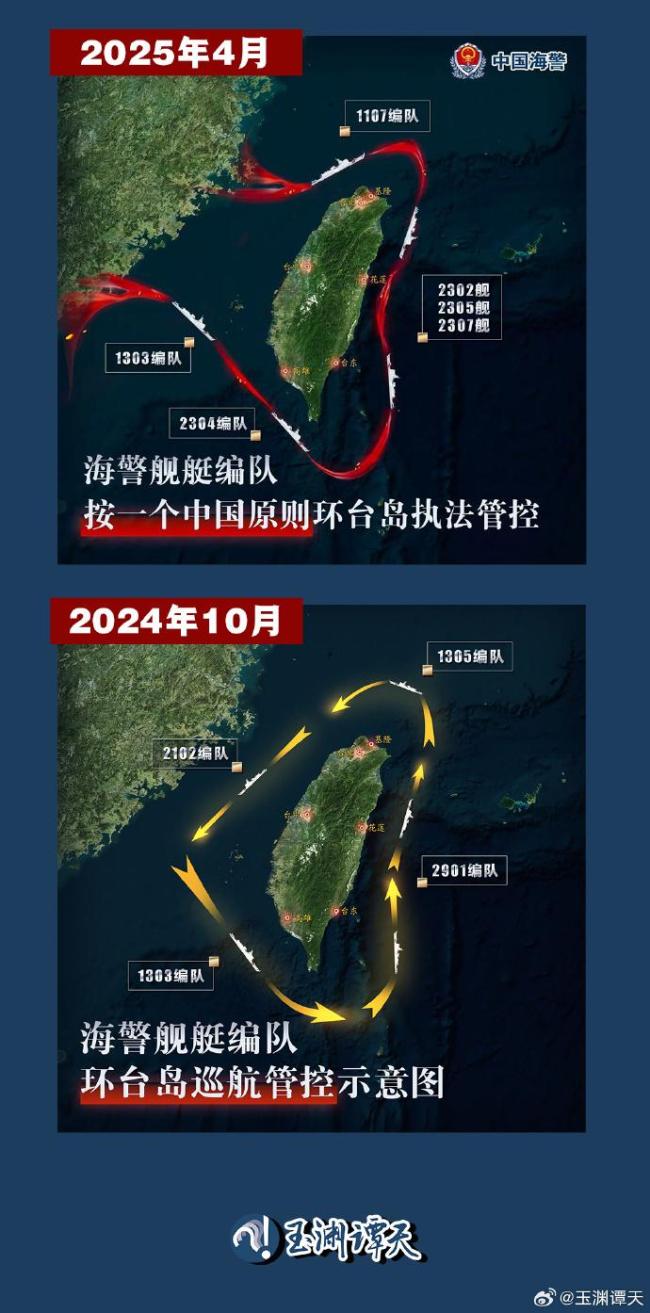
海警船用混天綾圈住臺灣 步步進(jìn)逼示警

馬斯克在線催生:不生人,,何來仁
相關(guān)新聞
工程院院士與DeepSeek過了一招 AI行業(yè)迎來“安卓時刻”
2025-03-03 08:49:55工程院院士與DeepSeek過了一招中國工程院院士汪懋華逝世 農(nóng)業(yè)工程巨擘隕落
2025-03-01 22:43:43中國工程院院士汪懋華逝世中國工程院院士姚穆逝世 紡織教育巨擘隕落
2025-02-19 19:44:10中國工程院院士姚穆逝世沉痛悼念中國工程院院士黃旭華 核潛艇之父千古
2025-02-08 10:16:54沉痛悼念中國工程院院士黃旭華中國工程院院士趙法箴逝世 海水養(yǎng)殖領(lǐng)域巨擘隕落
2025-02-26 20:17:26中國工程院院士趙法箴逝世DeepSeek推動中國股票價值增1.3萬億美元
人工智能(AI)大模型DeepSeek點燃的AI熱潮,正在引發(fā)全球資本流向中國,。
2025-02-17 10:11:09DeepSeek推動中國股票價值增1.3萬億美元








