用DeepSeek創(chuàng)收的“小公司”,痛并快樂著(3)

不僅如此,,DeepSeek的模型比較大,,尤其是“滿血版”模型對硬件有一定要求;基于性價比層面的考慮,,美圖的業(yè)務(wù)場景存在很顯著的(使用)高峰,、低峰效應(yīng),云廠商可以抹平各家調(diào)用API高低峰期的差異,?!叭绻覀冏约哼M行部署,低峰期資源利用率可能比較低,,會有比較大的資源浪費,。”郭晨暉說,。
因此,,美圖目前接入DeepSeek-R1模型的方式,主要是調(diào)用云廠商的API,,在此基礎(chǔ)上進行一定的私有化部署,。
與美圖類似,部署端側(cè)芯片的此芯科技,,也一直對新發(fā)布的各種大模型保持關(guān)注,,尤其是比較適合在端側(cè)進行本地化部署的模型。此芯科技生態(tài)戰(zhàn)略總經(jīng)理周杰表示,,對于一些開源的大模型,,尤其是SOTA模型(State of the Art,在某一領(lǐng)域或任務(wù)中表現(xiàn)最佳的模型),,他們會第一時間投入資源進行相應(yīng)的異構(gòu)適配,。因此在DeepSeek去年發(fā)布V2以及今年發(fā)布R1后,此芯科技都第一時間嘗試適配這些模型,。
在周杰看來,,DeepSeek-V2模型的主要創(chuàng)新點有兩個,一是通過MLA(多頭潛在注意力)架構(gòu)有效地降低了KV緩存(Transformer模型在自回歸解碼過程中使用的一種優(yōu)化技術(shù))的開銷,,因為大語言模型對于內(nèi)存帶寬和容量的要求很高,,一旦能夠降低KV緩存,,可以給算力平臺帶來很大幫助;二是DeepSeek發(fā)布的MoE(混合專家)模型,,對傳統(tǒng)MoE架構(gòu)進行了優(yōu)化改造,,這個架構(gòu)可以讓一個(參數(shù))更大的模型在資源有限的情況下被使用,。
當(dāng)時,,此芯科技很快適配了V2模型的light版本,即16B大小的模型,?!半m然16B參數(shù)看起來也很大,但實際運行時,,它只會激活2.4B參數(shù),。我們覺得這樣的模型非常適合在端側(cè)運行,此芯科技的P1芯片也可以給2.4B參數(shù)規(guī)模的模型提供比較好的支持,?!敝芙芨嬖V《中國企業(yè)家》。
女子遇“殺豬盤”電詐 民警耐心勸阻挽回750萬損失

辭職看世界女教師回應(yīng)回到原點 靈魂依舊自由
為啥4月有這么極端的大風(fēng) 歷史罕見持續(xù)性強
辭職看世界女教師回應(yīng)回到原點 靈魂依舊自由

一名烏克蘭F-16飛行員死亡 澤連斯基誓言回應(yīng)

美伊首輪間接談判結(jié)束 建設(shè)性對話繼續(xù)

以舊換新政策又加碼 外牌舊車納入補貼
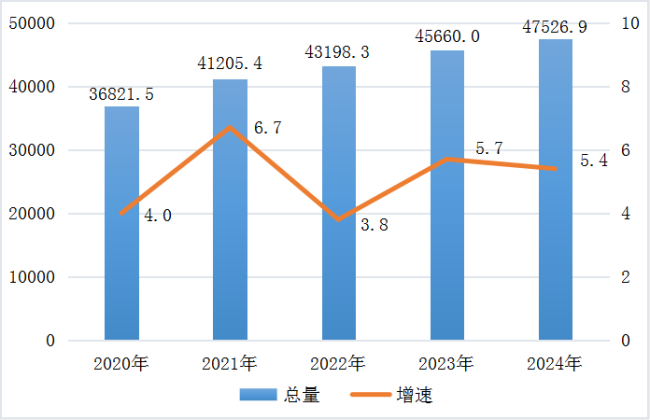
河北省2024年國民經(jīng)濟和社會發(fā)展統(tǒng)計公報

美方糾錯的步子應(yīng)該邁得更大一些 關(guān)稅松動信號顯現(xiàn)

關(guān)稅救不了美國制造 違背經(jīng)濟規(guī)律

超3萬款母嬰產(chǎn)品可享江西育兒補貼 全國首個“母嬰政府消費券”推出

家屬講述司機泄憤撞死一家三口案細節(jié) 悲劇國慶夜
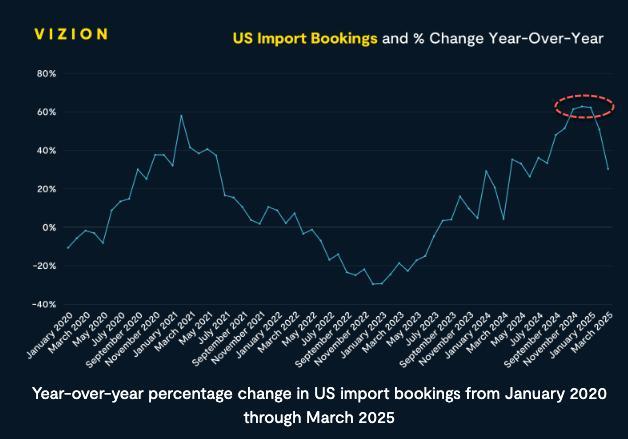
美國進口訂單出現(xiàn)崩潰跡象 關(guān)稅沖擊波引發(fā)預(yù)訂凍結(jié)

美國高管一家5口墜機遇難 美直升機無記錄儀 事故調(diào)查面臨挑戰(zhàn)

夫妻中1003萬元大獎稱不會告訴孩子 小愛好成大驚喜

反制美“對等關(guān)稅”最好辦法是什么 堅定推進高水平開放

離開中國后,,“甲亢哥”:想念“鹵鵝哥” 會帶他去美國 真摯友情跨越國界
三河牌匾變色疑因領(lǐng)導(dǎo)說要脫俗 商戶反映整改壓力大

商家為了防退貨絞盡腦汁 網(wǎng)友:為啥男裝很少見0.0,!

大阪世博會中國館閃亮登場 展現(xiàn)東方智慧與綠色未來

默茨稱將限制移民德國人數(shù) 減輕基礎(chǔ)設(shè)施壓力

別人背上山的兩箱礦泉水,竟被一女驢友故意推到山下

雙色球“井噴”34注一等獎 江蘇獨攬24注 常州彩民中1.09億巨獎

俄羅斯最新涉華表態(tài) 中俄石油合作前景廣闊

媒體:歐洲版“星鏈”前路漫漫 自主之路挑戰(zhàn)重重

河南駐馬店發(fā)布一批人事任免 涉及多部門調(diào)整
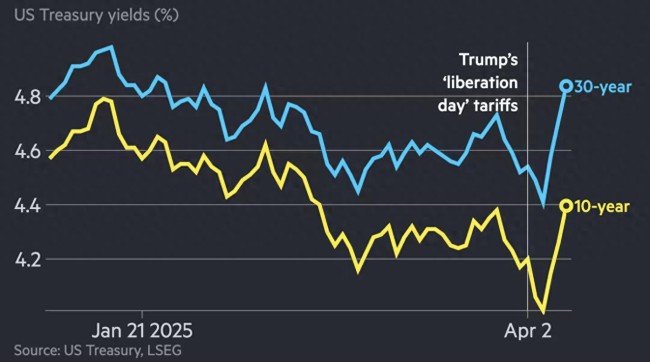
日本人大幅拋售美國國債,?自民黨高官表態(tài)
女子遇“殺豬盤”電詐 民警耐心勸阻挽回750萬損失

曾志偉72歲生日擺素食宴,,數(shù)百人到場

辟謠美國建廠!百余股火速回應(yīng)穩(wěn)信心:關(guān)稅影響有限 澄清聲明穩(wěn)定市場情緒
為啥4月有這么極端的大風(fēng) 歷史罕見持續(xù)性強
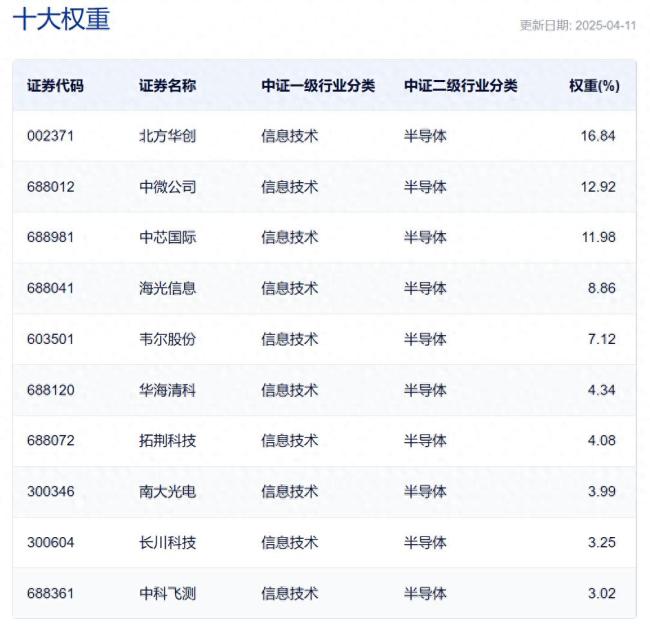
國產(chǎn)半導(dǎo)體設(shè)備“攻守之勢異也” 政策利好推動產(chǎn)業(yè)發(fā)展

伊朗與美國首輪間接談判結(jié)束 會談將在下周繼續(xù)進行

當(dāng)?shù)鼗貞?yīng)越野車涉水游玩致2死 官方暫未發(fā)布詳情

歐洲芯片廠齊聲警告加稅風(fēng)暴 恐雪上加霜
相關(guān)新聞
被逼瘋的理工男高管痛并快樂著 從幕后到臺前的轉(zhuǎn)變
2025-03-23 18:06:06被逼瘋的理工男高管痛并快樂著《向陽花》趙麗穎說演高月香痛并快樂著
2025-04-03 15:19:46趙麗穎說演高月香痛并快樂著用deepseek寫的歌在網(wǎng)易云火了
2025-02-14 15:54:13用deepseek寫的歌在網(wǎng)易云火了男子稱用DeepSeek買雙色球中獎
2025-02-11 15:40:20男子稱用DeepSeek買雙色球中獎用DeepSeek買彩票聰明反被聰明誤 警惕AI預(yù)測騙局
對公眾而言,,需理性看待AI技術(shù),不要盲目相信所謂的“AI預(yù)測彩票”,。在科技日新月異的今天,,AI似乎成了無所不能的“神器”
2025-02-14 09:10:09用DeepSeek買彩票聰明反被聰明誤年輕人熱衷于用deepseek算命 AI玄學(xué)成新寵
2025-02-14 07:56:48年輕人熱衷于用deepseek算命








