英偉達(dá)創(chuàng)滿血DeepSeek推理世界紀(jì)錄 性能顯著提升

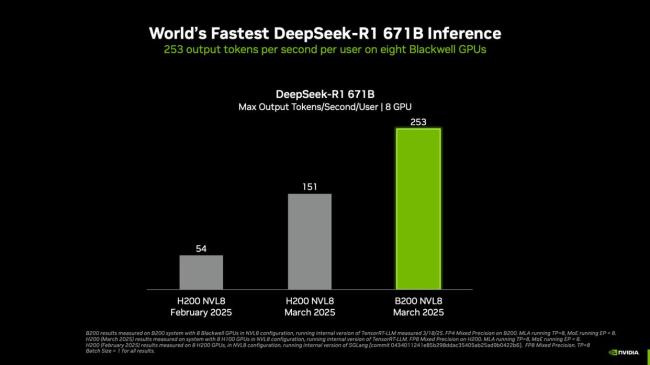
英偉達(dá)在NVIDIA GTC 2025上宣布,其NVIDIA Blackwell DGX系統(tǒng)創(chuàng)下DeepSeek-R1大模型推理性能的世界紀(jì)錄,。在搭載了八塊Blackwell GPU的單個(gè)DGX系統(tǒng)上運(yùn)行6710億參數(shù)的滿血DeepSeek-R1模型可實(shí)現(xiàn)每用戶每秒超250 token的響應(yīng)速度,,系統(tǒng)最高吞吐量突破每秒3萬token,。

隨著NVIDIA平臺繼續(xù)在最新的Blackwell Ultra GPU和Blackwell GPU上突破推理極限,,其性能將會不斷提高,。例如,,在運(yùn)行TensorRT-LLM軟件的NVL8配置的NVIDIA B200 GPU上,,單節(jié)點(diǎn)配置為DGX B200(8塊GPU)與DGX H200(8塊GPU),,測試參數(shù)為輸入1024 token / 輸出2048 token,;此前測試為輸入/輸出各1024 token,計(jì)算精度方面,,B200采用FP4,,H100/H200采用FP8精度。
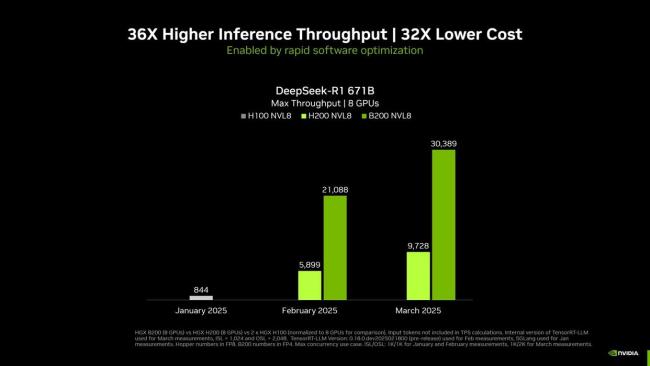
自2025年1月以來,,通過硬件和軟件的結(jié)合,,英偉達(dá)成功將DeepSeek-R1 671B模型的吞吐量提高了約36倍。節(jié)點(diǎn)配置包括DGX B200(8塊GPU),、DGX H200(8塊GPU)以及兩個(gè)DGX H100(8塊GPU)系統(tǒng),,測試參數(shù)依然采用TensorRT-LLM內(nèi)部版本,輸入1024 token / 輸出2048 token,,并發(fā)性MAX,,計(jì)算精度方面,B200采用FP4,,H100/H200采用FP8精度,。
與Hopper架構(gòu)相比,Blackwell架構(gòu)與TensorRT軟件相結(jié)合實(shí)現(xiàn)了顯著的推理性能提升,。DGX B200平臺在運(yùn)行TensorRT軟件并使用FP4精度時(shí),,與DGX H200平臺相比提供了3倍以上的推理吞吐量提升,適用于包括DeepSeek-R1,、Llama 3.1 405B和Llama 3.3 70B在內(nèi)的多個(gè)模型,。在對模型進(jìn)行量化以利用低精度計(jì)算優(yōu)勢時(shí),確保精度損失最小化是生產(chǎn)部署的關(guān)鍵,。在DeepSeek-R1模型上,,相較于FP8基準(zhǔn)精度,TensorRT Model Optimizer的FP4訓(xùn)練后量化技術(shù)在不同數(shù)據(jù)集上僅產(chǎn)生微乎其微的精度損失,。

男生去鎮(zhèn)上洗頭免費(fèi)吹造型效果驚人,!這個(gè)服務(wù)區(qū)共20項(xiàng)服務(wù)全部免費(fèi)

合肥深山驚現(xiàn)百木之王 古老灰楸樹綻放紫花
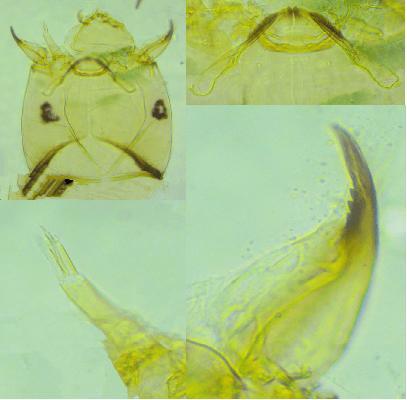
上海發(fā)現(xiàn)中國未有神秘生物 類奇異布紋藻現(xiàn)身

美方糾錯(cuò)的步子應(yīng)該邁得更大一些 關(guān)稅松動(dòng)信號顯現(xiàn)

辟謠美國建廠!百余股火速回應(yīng)穩(wěn)信心:關(guān)稅影響有限 澄清聲明穩(wěn)定市場情緒
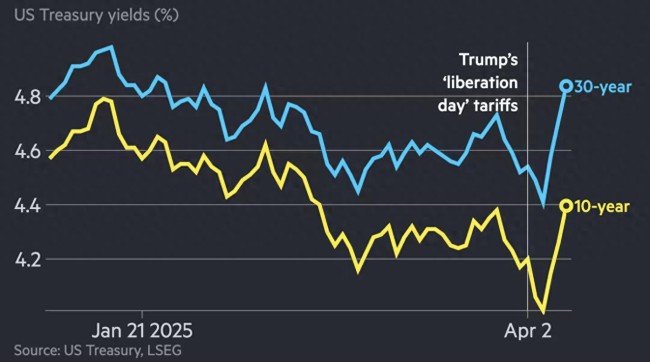
日本人大幅拋售美國國債?自民黨高官表態(tài)

越野車玩水被沖走兩人遇難 網(wǎng)紅景點(diǎn)悲劇引發(fā)關(guān)注
男生去鎮(zhèn)上洗頭免費(fèi)吹造型效果驚人,!這個(gè)服務(wù)區(qū)共20項(xiàng)服務(wù)全部免費(fèi)

小孩跳樓砸壞新車家長只賠幾百 車主索賠遇阻
上海發(fā)現(xiàn)中國未有神秘生物 類奇異布紋藻現(xiàn)身

全球發(fā)布,!哈工大打造機(jī)器人領(lǐng)域頂級國際期刊 匯聚全球頂尖學(xué)術(shù)資源

媒體:歐洲版“星鏈”前路漫漫 自主之路挑戰(zhàn)重重

美伊首輪間接談判結(jié)束 建設(shè)性對話繼續(xù)

大阪世博會中國館排隊(duì)一眼望不到頭 中國館成“頂流”

一峪口貼警告“兩年失聯(lián)9人” 提醒游客勿走小路

俄羅斯最新涉華表態(tài) 中俄石油合作前景廣闊

默茨稱將限制移民德國人數(shù) 減輕基礎(chǔ)設(shè)施壓力

老婆睡覺前被老公惹怒,老婆一個(gè)動(dòng)作當(dāng)場把老公治服
合肥深山驚現(xiàn)百木之王 古老灰楸樹綻放紫花

歐盟磋商設(shè)立共同防務(wù)基金 促進(jìn)統(tǒng)一軍購

“鹵鵝哥”回應(yīng)10萬元獎(jiǎng)勵(lì) 房貸與車貸的及時(shí)雨

美國反復(fù)打臉又挽尊傷最狠是自身 關(guān)稅政策自食其果

雷霆本賽季68勝創(chuàng)隊(duì)史新紀(jì)錄 歷史級別戰(zhàn)績

歐洲芯片廠齊聲警告加稅風(fēng)暴 恐雪上加霜
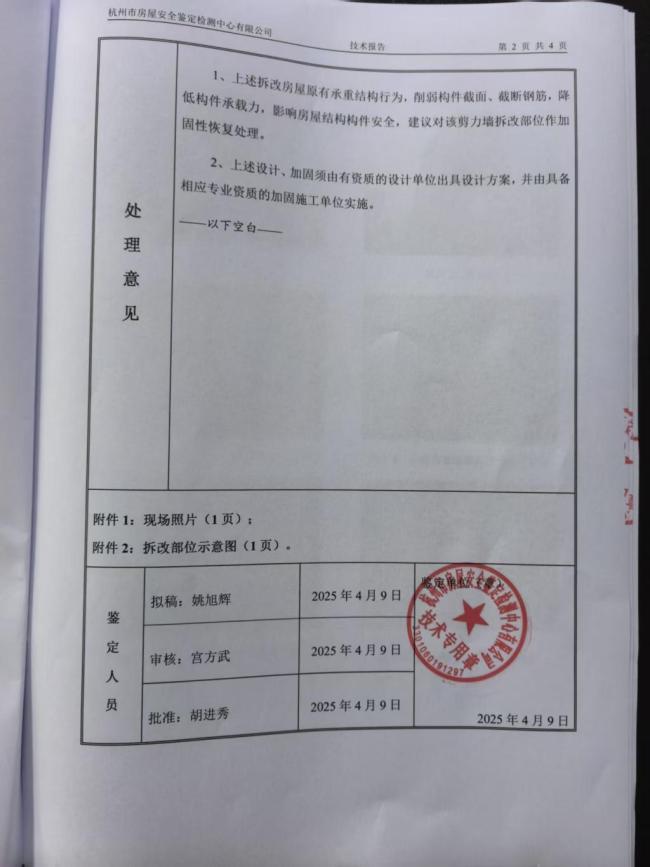
當(dāng)?shù)鼗貞?yīng)小區(qū)8樓承重墻被鑿 建議加固恢復(fù)處理

尹錫悅出席公審 首場審判開啟

臺民調(diào)稱近六成民眾反對“大罷免” 主流民意不贊成

一名烏克蘭F-16飛行員死亡 澤連斯基誓言回應(yīng)

關(guān)稅救不了美國制造 違背經(jīng)濟(jì)規(guī)律

TVB視帝王浩信想挑戰(zhàn)一下古偶賽道和拍鄉(xiāng)村愛情

2年半賣出30萬罐,,90后廚師為什么要把“奶油”塞進(jìn)自動(dòng)售貨機(jī),?

10個(gè)會悄悄讓人變胖的習(xí)慣 警惕這些小習(xí)慣

美國高管一家5口墜機(jī)遇難 美直升機(jī)無記錄儀 事故調(diào)查面臨挑戰(zhàn)

伊朗與美國首輪間接談判結(jié)束 會談將在下周繼續(xù)進(jìn)行

離開中國后,,“甲亢哥”:想念“鹵鵝哥” 會帶他去美國 真摯友情跨越國界
相關(guān)新聞
黃仁勛揭秘下一代芯片Rubin,英偉達(dá)想要吃“DeepSeek紅利” 推理時(shí)代的新機(jī)遇
2025-03-19 12:03:54黃仁勛揭秘下一代芯片Rubin英偉達(dá)上線DeepSeek 領(lǐng)先推理模型預(yù)覽版發(fā)布
2025-02-01 01:41:22英偉達(dá)上線DeepSeek英偉達(dá)稱DeepSeek離不開其芯片 市場需求增加
1月28日,,全球多家科技巨頭因DeepSeek的技術(shù)進(jìn)步而受到影響,英偉達(dá)的股價(jià)在美股市場收跌16.86%,,每股報(bào)18.58美元
2025-01-28 18:22:15英偉達(dá)稱DeepSeek離不開其芯片英偉達(dá):DeepSeek未來需要更多芯片 市場需求旺盛
2025-01-28 11:24:53英偉達(dá)DeepSeek崛起沖擊美股 英偉達(dá)股價(jià)大跌17%
2025-01-28 07:17:05美股DeepSeek繼續(xù)給巨頭上壓力 英偉達(dá)業(yè)績超預(yù)期
2025-02-28 18:41:01DeepSeek繼續(xù)給巨頭上壓力