DeepSeek發(fā)布V3模型更新 性能再升級(jí)

3月24日晚,DeepSeek發(fā)布了模型更新——DeepSeek-V3-0324,。這次更新是DeepSeek V3模型的小版本升級(jí),,并非市場(chǎng)期待的DeepSeek-V4或R2,。其開源版本已上線Hugging Face,,模型體積為6850億參數(shù),。
同日,,DeepSeek在其官方交流群宣布,,DeepSeek V3模型已完成小版本升級(jí),,歡迎用戶前往官方網(wǎng)頁(yè)、App和小程序試用體驗(yàn),。API接口和使用方式保持不變,。
此前于2024年12月發(fā)布的DeepSeek-V3模型以“557.6萬美金比肩Claude 3.5效果”的高性價(jià)比著稱,多項(xiàng)評(píng)測(cè)成績(jī)超越了Qwen2.5-72B和Llama-3.1-405B等其他開源模型,,并在性能上與世界頂尖的閉源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲,。但截至目前,還沒有關(guān)于新版DeepSeek-V3的能力基準(zhǔn)測(cè)試榜單出現(xiàn),。
2025年1月,,DeepSeek發(fā)布了性能比肩OpenAI o1正式版的DeepSeek-R1模型。該模型在后訓(xùn)練階段大規(guī)模使用了強(qiáng)化學(xué)習(xí)技術(shù),,在僅有極少標(biāo)注數(shù)據(jù)的情況下,,極大提升了模型推理能力,。
V3是一個(gè)擁有6710億參數(shù)的專家混合模型(Moe),,其中370億參數(shù)處于激活狀態(tài)。傳統(tǒng)的大模型通常采用密集的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),,每個(gè)輸入token都會(huì)被激活并參與計(jì)算,,耗費(fèi)大量算力。此外,,傳統(tǒng)的混合專家模型中,,不平衡的專家負(fù)載是一個(gè)很大難題,會(huì)導(dǎo)致路由崩潰現(xiàn)象,,影響計(jì)算效率,。
為解決這個(gè)問題,DeepSeek對(duì)V3進(jìn)行了大膽創(chuàng)新,,提出了輔助損失免費(fèi)的負(fù)載均衡策略,,引入“偏差項(xiàng)”。在模型訓(xùn)練過程中,,每個(gè)專家都被賦予了一個(gè)偏差項(xiàng),,它會(huì)被添加到相應(yīng)的親和力分?jǐn)?shù)上,以此來決定top-K路由,。此外,,V3還采用了節(jié)點(diǎn)受限的路由機(jī)制,限制通信成本,。通過確保每個(gè)輸入最多只能被發(fā)送到預(yù)設(shè)數(shù)量的節(jié)點(diǎn)上,,V3能夠顯著減少跨節(jié)點(diǎn)通信的流量,提高訓(xùn)練效率,。
根據(jù)國(guó)外開源評(píng)測(cè)平臺(tái)kcores-llm-arena對(duì)V3-0324的最新測(cè)試數(shù)據(jù)顯示,,其代碼能力達(dá)到了328.3分,超過了普通版的Claude 3.7 Sonnet(322.3),可以比肩334.8分的思維鏈版本,。

夫妻中千萬大獎(jiǎng)稱不告訴孩子 等待孩子成熟再告知

特朗普當(dāng)著孫女的面羞辱記者:看見了嗎,?這些就是假新聞

無憂渡 夜華的頭套還留著呢 段半夏從懵懂少女成長(zhǎng)為守護(hù)者的弧光
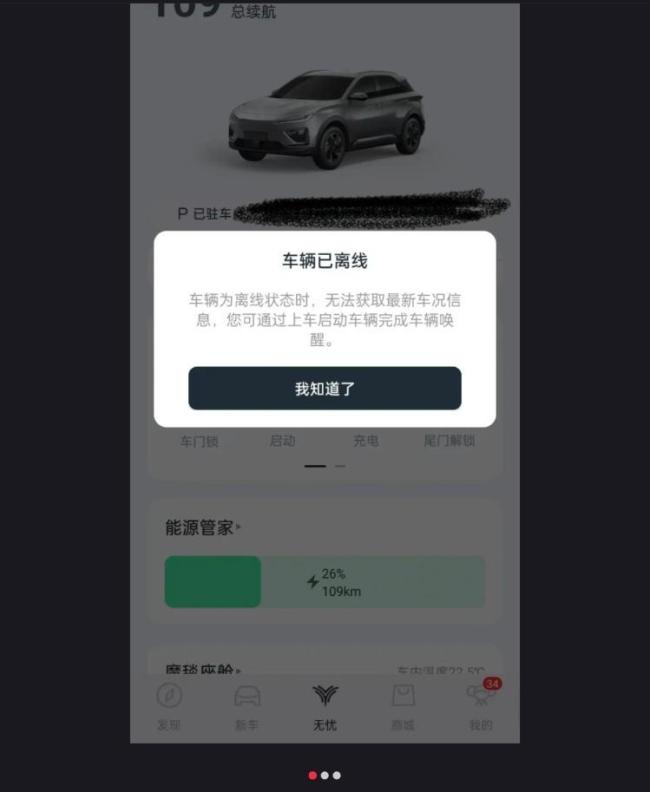
哪吒汽車 斷網(wǎng)事件引發(fā)信任危機(jī)

“對(duì)等關(guān)稅”重創(chuàng)美國(guó)小企業(yè) 反噬自身經(jīng)濟(jì)

俄稱對(duì)華石油供應(yīng)管夠 滿足中國(guó)需求

專家稱關(guān)稅戰(zhàn)讓美國(guó)的盟友都不再相信它

余承東和工程師拼手速還贏了

老板為報(bào)復(fù)員工扛20斤硬幣支付工資 惡意履行觸法網(wǎng)

嚴(yán)格依法實(shí)施各項(xiàng)對(duì)美反制措施 維護(hù)國(guó)家主權(quán)安全發(fā)展利益

中方果斷回?fù)?美軍“六代機(jī)”F-47危!稀土管制加碼
如何跟大國(guó)相處 美國(guó)還得補(bǔ)課

日本發(fā)生食物中毒事件 已有1人死亡 諾如病毒成疑兇
無憂渡 夜華的頭套還留著呢 段半夏從懵懂少女成長(zhǎng)為守護(hù)者的弧光

打扮成埃及女王逛大英博物館 博主吐槽引熱議

八個(gè)有望抗住關(guān)稅沖擊的出海賽道 解鎖全球生活方式共建者新角色

俄為何空襲烏克蘭蘇梅市 教堂鐘聲下的悲劇

緬甸災(zāi)區(qū)進(jìn)入防疫消殺 中方接力馳援 救援“接力棒”持續(xù)傳遞

老板扛20斤硬幣付工資法官讓其清點(diǎn) 惡意刁難員工
夫妻中千萬大獎(jiǎng)稱不告訴孩子 等待孩子成熟再告知
特朗普當(dāng)著孫女的面羞辱記者:看見了嗎,?這些就是假新聞

駐日大使館提醒注意防范地震 提高防災(zāi)意識(shí)

高關(guān)稅背景下中企如何“活下去” 三大策略穩(wěn)住腳跟

航模愛好者自制能飛上天的“殲-20” 紙箱變身特技戰(zhàn)機(jī)

剖析甲亢哥中國(guó)行直播連續(xù)劇 全民狂歡的流量盛宴

楊紫《家業(yè)》逛街路透,,和美女們說說笑笑…
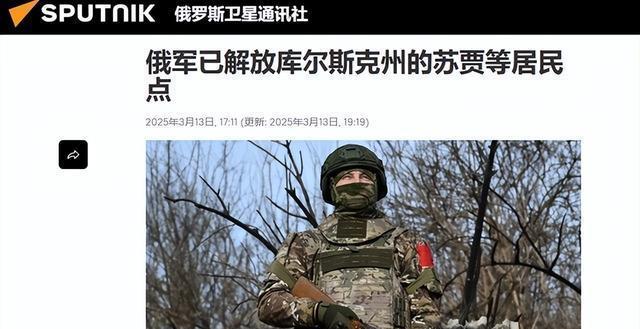
大V:烏軍在庫(kù)爾斯克損失極為慘重 俄軍反擊得勝

美國(guó)若想生產(chǎn)婚紗得先培養(yǎng)縫紉工 關(guān)稅政策沖擊婚慶業(yè)
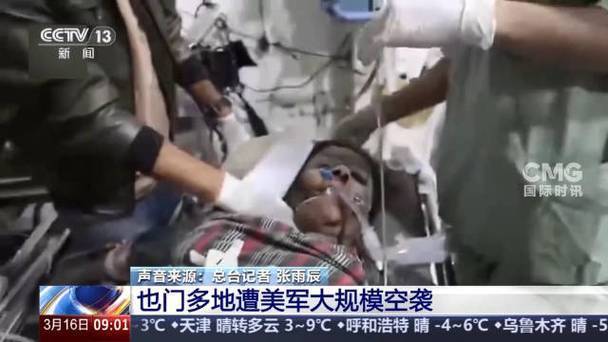
美軍再次空襲也門致多人死傷 建筑物遭襲被大火吞噬 硝煙中的平民悲劇

美對(duì)等關(guān)稅這劑藥反噬自身 單邊主義終損己利
12級(jí)大風(fēng)將蒙古獒幼崽刮到牧民家,網(wǎng)友:我想要一只牛

臺(tái)媒又炒:解放軍軍機(jī)6架次,、軍艦7艘持續(xù)在臺(tái)海周邊活動(dòng) 大陸回應(yīng)震懾“臺(tái)獨(dú)”

關(guān)稅博弈下A股涌現(xiàn)增持回購(gòu)潮 積極信號(hào)頻現(xiàn)

《我的后半生》劇情有多狗血 家庭崩塌與人性覺醒

美國(guó)突然宣布: 部分商品免除所謂“對(duì)等關(guān)稅” 電子產(chǎn)品獲豁免
相關(guān)新聞
馬斯克談DeepSeek xAI即將發(fā)布更強(qiáng)模型
2025-02-09 22:13:58馬斯克談DeepSeekDeepSeek發(fā)布新模型 Janus-Pro超越DALL-E 3
2025-01-28 09:17:49DeepSeek發(fā)布新模型英偉達(dá)平臺(tái)上線DeepSeek 先進(jìn)模型預(yù)覽發(fā)布
2025-01-31 20:32:36英偉達(dá)平臺(tái)上線DeepSeekDeepSeek上線國(guó)家超算互聯(lián)網(wǎng)平臺(tái) 多版本模型陸續(xù)更新
2025-02-06 08:45:33DeepSeek上線國(guó)家超算互聯(lián)網(wǎng)平臺(tái)DeepSeek 模型需求更高算力
2025-03-20 14:24:42DeepSeek馬斯克發(fā)布新模型 稱能力超DeepSeek Grok 3亮相引發(fā)關(guān)注
2025-02-18 13:56:45馬斯克發(fā)布新模型稱能力超DeepSeek








