問DeepSeek:孩子手機成癮的底層邏輯 創(chuàng)新突破算力禁運(2)

在DeepSeekV3和R1推出后,,頂尖的模型效果和用戶體驗,,加上開源特性,大大緩解了我國在算法和算力上的困境,,但數(shù)據(jù)方面的挑戰(zhàn)依然存在,。高質(zhì)量數(shù)據(jù)能夠保障模型推理回答的準確性,多模態(tài)多種類的數(shù)據(jù)能提升模型的泛化性和推理能力,。然而,國內(nèi)和國外在可用數(shù)據(jù)量上存在天然差距。據(jù)W3Techs調(diào)研顯示,,英文網(wǎng)站占比為59.3%,,而中文只有1.3%。國內(nèi)可供訓練的公開中文數(shù)據(jù)不足,,標準化程度也不高,。IDC和浪潮信息的研究顯示,目前企業(yè)在應用人工智能中面臨的最大挑戰(zhàn)是缺乏高質(zhì)量可用數(shù)據(jù),,占比高達66%,。此外,數(shù)據(jù)采集與處理是國內(nèi)企業(yè)在生成式AI應用時的主要支出方向,。
DeepSeek采用創(chuàng)新性架構(MLA+MoE),,解決了許多工程化難題,使其在極低成本下成為最強的開源基礎模型之一,。DeepSeek的關鍵在于使用數(shù)據(jù)蒸餾技術,,得到更為精煉有用的數(shù)據(jù)。具體而言,,DeepSeek-R1-Zero模型通過自我嘗試和調(diào)整行為來學習,,不需要預先標注的數(shù)據(jù)。該模型在數(shù)學和編程方面表現(xiàn)優(yōu)異,,但也存在可讀性差的問題,。為此,DeepSeek團隊通過監(jiān)督微調(diào)和強化學習優(yōu)化模型,,使生成的答案更清晰,,語言更統(tǒng)一。
DeepSeek除了在算法層面進行創(chuàng)新和優(yōu)化,,其核心步驟中的數(shù)據(jù)都是自行人工處理或撰寫的,。爆火后,DeepSeek開啟了數(shù)據(jù)百曉生實習生招聘,,崗位要求不高但薪資豐厚,,顯示出對高質(zhì)量數(shù)據(jù)的重視。值得注意的是,,該崗位優(yōu)先考慮小語種專業(yè),,這可能是為了進軍全球市場所做的準備。
在具身智能和自動駕駛領域,,數(shù)據(jù)同樣面臨挑戰(zhàn),。上海交大博導盧策吾教授指出,具身智能面臨數(shù)據(jù)規(guī)模不足的問題,,工業(yè)級應用需要大量數(shù)據(jù)才能達到標準,。數(shù)據(jù)采集成本高昂,限制了數(shù)據(jù)規(guī)模。在自動駕駛領域,,端到端技術的核心在于通過大量數(shù)據(jù)訓練模型,,使其識別和預測各種駕駛場景。高質(zhì)量數(shù)據(jù)決定了模型輸出的準確性和可靠性,。華為在智駕方面的一半投入用于數(shù)據(jù)采集和處理,。特斯拉FSD測試里程需達60億英里才能滿足監(jiān)管要求,長尾數(shù)據(jù)的收集難度和成本更高,。

神十九乘組即時反饋太空之家舒適度 問卷視頻記錄體驗

美脫口秀告誡特朗普不要惹惱中國 提及《孫子兵法》警告

中國鍛壓協(xié)會發(fā)布關于加征關稅聲明 堅決反對貿(mào)易保護主義

烏稱俄襲擊蘇梅市 已致34人死亡 救援行動持續(xù)進行

美稱中美已通過中間人就關稅初步接觸 中方堅決反對美方霸凌行徑

老板設暖心暗號助人免費吃面 傳遞愛心與溫暖
美脫口秀告誡特朗普不要惹惱中國 提及《孫子兵法》警告

租戶沒關窗隔斷墻被吹倒 河南極端大風刮走整片落地窗

楊紫《家業(yè)》逛街路透,,和美女們說說笑笑…

如何看待烏軍F-16戰(zhàn)機被俄擊落 神話破滅引發(fā)熱議

接親玩跳繩游戲,調(diào)皮伴郎忽悠伴娘,,虛晃一槍,!

毛寧轉(zhuǎn)發(fā)王毅霸氣言論 彰顯中國決心
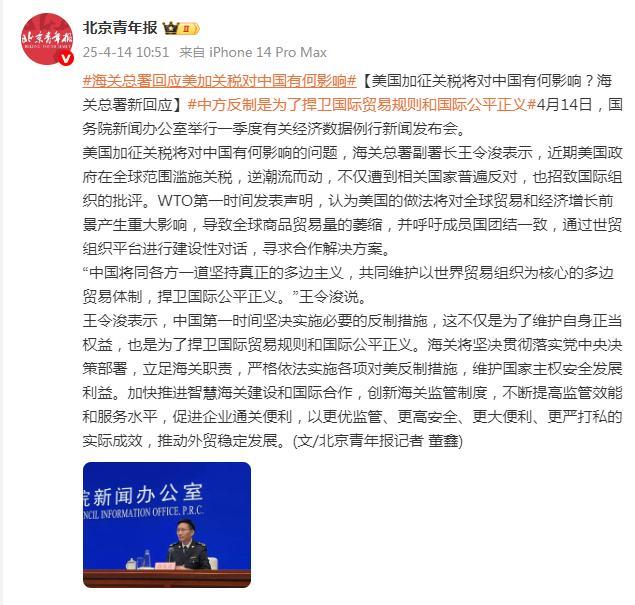
海關總署最新回應 堅決反制美國加征關稅

美國對中國威脅最大的核潛艇力量信譽一落千丈,到底發(fā)生了什么,?
神十九乘組即時反饋太空之家舒適度 問卷視頻記錄體驗

美軍將重返巴拿馬前美軍基地,?巴反對派指責美方發(fā)動“偽裝入侵” 引發(fā)民眾反感與抗議

臺灣加權指數(shù)漲幅擴大至2% 盤初表現(xiàn)強勁

18歲腦癱少年堅持跑完10公里馬拉松,,跑到終點的那一刻他就贏了!
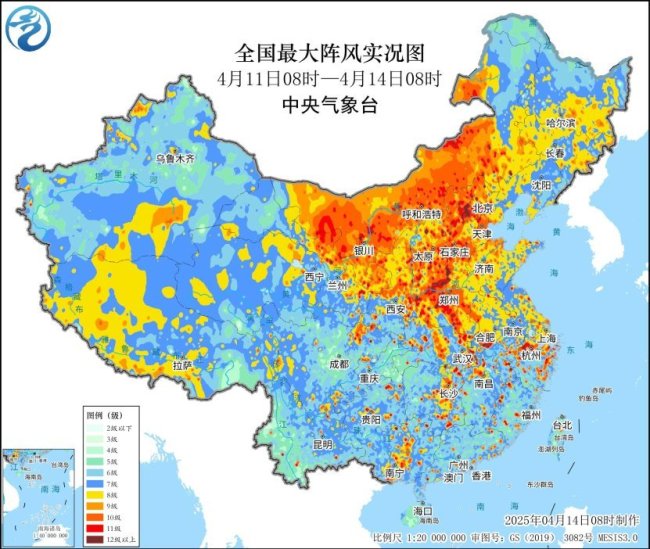
冷空氣什么時候離開,?接下來氣溫如何變化,?

黃智賢:臺灣唯一出路是統(tǒng)一

美防長威脅:如果談判失敗,,美軍已準備好確保伊朗永遠不會擁有核武器 展示軍事打擊能力
中國鍛壓協(xié)會發(fā)布關于加征關稅聲明 堅決反對貿(mào)易保護主義

小心異常春困!多種疾病的前期癥狀與春困很像

哈登:季后賽就是要毫無保留 拼盡一切手段

告別雪球,,“中國巴菲特”暫停投資布道的秘密 長鏡頭

中越將開展第38次北部灣聯(lián)合巡邏 增進兩軍合作

聊城教師被指誘騙多名女生戀愛 發(fā)生性關系 涉事教師遭嚴肅處理

大V:為防烏閃擊布良斯克俄率先發(fā)難
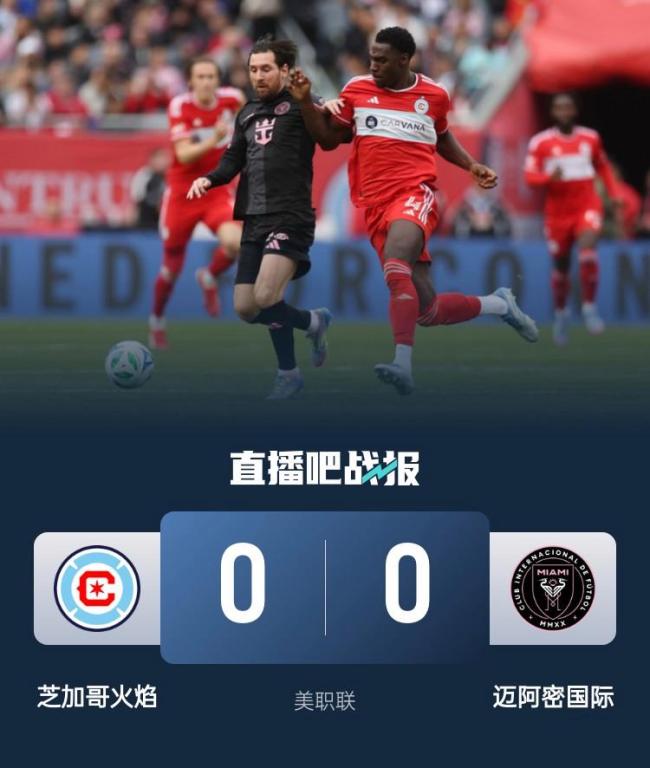
邁阿密0-0芝加哥集錦:梅西任意球兩度中楣 蘇牙痛失單刀 雙方互交白卷

A股三大指數(shù)齊上漲 創(chuàng)業(yè)板指領漲1.44%

烏方證實一飛行員已死亡 F-16戰(zhàn)機被擊落

烏克蘭基輔市遭俄軍無人機襲擊:致3人受傷并引發(fā)火災

清華博士在中山造“腦機” 夢想走進現(xiàn)實

美專家:特朗普關稅損害美國際信譽 政策變化加劇不確定性

玉樹地震15周年祭 銘記那場傷痛
相關新聞
網(wǎng)友問DeepSeek最多的問題是什么
2025-02-18 15:44:42網(wǎng)友問DeepSeek最多的問題十問解構DeepSeek AI新勢力崛起
2025-02-03 09:06:41十問解構DeepSeek問DeepSeek最帥的動漫人物是誰 大家聊得火熱
2025-02-21 14:02:06問DeepSeek最帥的動漫人物是誰DeepSeek回答最想問人類什么問題 AI統(tǒng)治未來,?
2025-01-29 12:36:28DeepSeek回答最想問人類什么問題當我問DeepSeek不想上班怎么辦 從躺平模式切換到元氣滿滿
2025-02-05 08:29:05當我問DeepSeek不想上班怎么辦應屆博士被DeepSeek面試官連問3小時 高壓面試引熱議
2025-02-10 12:28:17應屆博士被DeepSeek面試官連問3小時