研究:中美模型質(zhì)量差距縮小至0.3% AI競爭白熱化(2)

美國仍然是強(qiáng)大模型的最大生產(chǎn)國,2024年發(fā)布了40個(gè)模型,,中國發(fā)布了15個(gè),,歐洲發(fā)布了3個(gè)。但許多其他地區(qū)也在加入這場競賽,,包括中東,、拉丁美洲和東南亞。塞爾曼說,,2015年左右,,中國走上了成為人工智能領(lǐng)域頂尖參與者的道路,他們通過教育投資實(shí)現(xiàn)了這一目標(biāo),。我們看到這開始有了回報(bào),。
AI領(lǐng)域還出現(xiàn)了“開放權(quán)重”模型在數(shù)量和性能上的驚人增長,如DeepSeek和Meta的LLaMa,。用戶可以自由查看這些模型在訓(xùn)練過程中學(xué)習(xí)到的并用于預(yù)測的參數(shù),,不過其他細(xì)節(jié),如訓(xùn)練代碼,,可能仍保密,。最初,不公開這些因素的封閉系統(tǒng)明顯更優(yōu)越,,但到2024年初,,這些類別中頂級競爭者之間的性能差距縮小到了8%,到2025年初則縮小到了1.7%,。
加利福尼亞州門洛帕克的非營利性研究機(jī)構(gòu)SRI的計(jì)算機(jī)科學(xué)家,、該報(bào)告的聯(lián)合主任雷·佩羅特說,,這對任何無力從頭構(gòu)建模型的人來說肯定是好事,包括許多小公司和學(xué)者,。OpenAI計(jì)劃在未來幾個(gè)月內(nèi)發(fā)布一個(gè)開放權(quán)重模型,。
2022年ChatGPT公開推出后,開發(fā)人員將大部分精力投入到通過擴(kuò)大模型規(guī)模來提升系統(tǒng)性能上,。這一趨勢仍在繼續(xù):訓(xùn)練一個(gè)典型的領(lǐng)先人工智能模型所消耗的能源目前每年翻一番,;每個(gè)模型使用的計(jì)算資源每五個(gè)月翻一番;訓(xùn)練數(shù)據(jù)集的規(guī)模每八個(gè)月翻一番,。
然而,,各公司也在發(fā)布性能非常出色的小型模型。例如,,2022年在MMLU上得分超過60%的最小模型使用了5400億個(gè)參數(shù),;到2024年,一個(gè)模型僅用38億個(gè)參數(shù)就達(dá)到了相同的分?jǐn)?shù),。小型模型比大型模型訓(xùn)練速度更快,、回答問題更迅速,且能耗更低,。佩羅特說,,這對各方面都有幫助。
塞爾曼說,,一些小型模型可以模仿大型模型的行為,,或者利用比舊系統(tǒng)更好的算法和硬件。人工智能系統(tǒng)使用的硬件的平均能源效率每年提高約40%,。由于這些進(jìn)步,在MMLU上得分超過60%的成本大幅下降,,從2022年11月的每百萬個(gè)token約20美元降至2024年10月的每百萬個(gè)token約7美分,。
盡管在幾項(xiàng)常見的基準(zhǔn)測試中取得了顯著進(jìn)步,但該指數(shù)強(qiáng)調(diào),,生成式人工智能仍然存在一些問題,,如隱性偏見和“幻覺”傾向,即吐出虛假信息,。塞爾曼說,,它們在很多方面給他留下了深刻印象,但在其他方面也讓他感到恐懼,。它們在犯一些非?;镜腻e(cuò)誤方面讓他感到驚訝。

俄軍高級官員汽車爆炸案嫌犯已被捕 烏克蘭特工落網(wǎng)

丁俊暉遭布雷切爾7連鞭 首階段1比7落后

周鴻祎稱自己要去重慶榮昌吃鹵鵝了 格局與流量雙贏

金融圈大消息,,重磅新規(guī)全文來了 嚴(yán)把銀行業(yè)高管準(zhǔn)入關(guān)口

詹?。夯蜀R后防線需升級,,整體陣容待調(diào)整

美防長為何稱中美20分鐘分出勝負(fù) 解放軍高超音速導(dǎo)彈威脅

印巴兩次短暫交火 聯(lián)合國呼吁保持“最大克制”

泰國國王親開飛機(jī)出訪 艙內(nèi)畫面曝光 展現(xiàn)高超飛行技術(shù)

兒子偷偷考上北大媽媽震驚成表情包 全網(wǎng)點(diǎn)贊逆襲之路

俄軍高級官員汽車爆炸案嫌疑人被捕 烏克蘭特工被拘留

臺20萬民眾集會怒罵賴清德,島內(nèi)反對賴清德的聲勢越來越大

特朗普:美國船只應(yīng)免費(fèi)通過蘇伊士和巴拿馬運(yùn)河 引發(fā)國際爭議

劉曉艷老師還是太全面了,,表情包撞臉文物

大V:阿薩德大概率可以善終 普京拒絕引渡保平安
周鴻祎稱自己要去重慶榮昌吃鹵鵝了 格局與流量雙贏
女子險(xiǎn)被假客服騙走47萬 警惕不明鏈接陷阱

數(shù)千名在美外國學(xué)生將恢復(fù)合法身份 簽證風(fēng)波迎來轉(zhuǎn)機(jī)
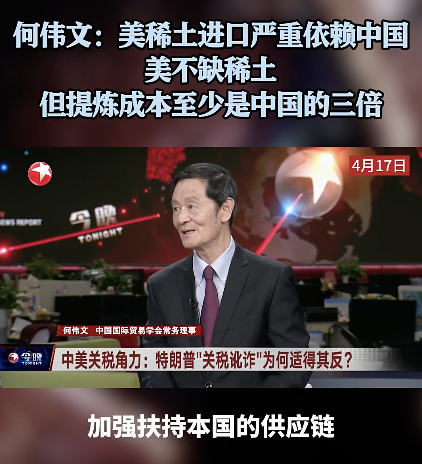
美國能擺脫對中國的稀土依賴嗎,?

男生枕頭越來越黃證明雄激素一直在!
俄軍高級官員汽車爆炸案嫌犯已被捕 烏克蘭特工落網(wǎng)
丁俊暉遭布雷切爾7連鞭 首階段1比7落后

伊朗爆炸目擊者稱現(xiàn)場黑煙滾滾 傷亡慘重救援緊急

學(xué)者談沙特砸巨資迎接特朗普 豪擲千億迎特朗普

94年的郭露西將成全球最年輕白手起家女性億萬富翁 AI創(chuàng)業(yè)成就輝煌

越南女孩街頭強(qiáng)勢圍觀解放軍,,中國軍人太有型了,!

中國海警在鐵線礁展示五星紅旗宣示主權(quán) 依法巡查取證

肖國棟無緣斯諾克世錦賽8強(qiáng) 決勝局惜敗希金斯

一個(gè)擁抱一碗牛肉面 女警勸回離家出走的高三女生

白宮爭吵后美烏總統(tǒng)首次會晤 梵蒂岡葬禮前會談

42歲鄧家佳被9歲女孩貼臉開大!鄧家佳直言自己沒有年齡焦慮

為何印度斷水能掐巴方“七寸” 水源之爭背后的危機(jī)

男子稱退租時(shí)遭二房東摸防盜欄驗(yàn)灰,,并強(qiáng)制扣除150元清潔費(fèi)

美放談判煙霧中方否認(rèn)關(guān)稅磋商 混淆視聽言論遭駁斥
美聯(lián)儲投降:鴿派信號提振市場

臺20萬民眾集會怒罵賴清德
相關(guān)新聞
研究表明西北風(fēng)也有營養(yǎng)
盡管喝西北風(fēng)不能填飽肚子,,但有強(qiáng)有力的證據(jù)表明能從空氣中吸收一些除氧氣之外的營養(yǎng)物質(zhì)。
2024-11-20 14:49:40研究表明西北風(fēng)也有營養(yǎng)研究顯示亞洲人更能忍耐工作
2024-10-24 15:21:41研究顯示亞洲人更能忍耐工作我國月球樣品研究取得重大進(jìn)展
2024-11-28 09:02:11我國月球樣品研究取得重大進(jìn)展研究說周五是出錯(cuò)率最高的一天
2024-11-29 13:49:45研究說周五是出錯(cuò)率最高的一天鳥類研究表明女兒對父母幫助更大
白眉雀織是一種生活在非洲卡拉哈里沙漠的群居鳥類,,它們以家庭為單位生活,,通常一個(gè)家庭中會有一對繁殖的鳥和多達(dá)10個(gè)非繁殖的“助手”協(xié)助喂養(yǎng)雛鳥。
2024-10-30 17:00:25鳥類研究表明女兒對父母幫助更大我國造出二維金屬材料 開創(chuàng)研究新領(lǐng)域
2025-03-13 15:16:51我國造出二維金屬材料