阿里千問(wèn)3登頂全球最強(qiáng)開(kāi)源模型 性能與成本雙重突破

阿里巴巴于4月29日凌晨開(kāi)源了新一代通義千問(wèn)模型Qwen3,簡(jiǎn)稱千問(wèn)3。該模型參數(shù)量?jī)H為DeepSeek-R1的三分之一,,成本顯著降低,性能卻全面超越R1,、OpenAI-o1等全球頂尖模型,成為目前最強(qiáng)的開(kāi)源模型之一。千問(wèn)3是國(guó)內(nèi)首個(gè)“混合推理模型”,能夠?qū)⒖焖俸蜕疃人伎技傻酵荒P椭?,?duì)簡(jiǎn)單需求可以迅速給出答案,而面對(duì)復(fù)雜問(wèn)題時(shí)則能進(jìn)行多步驟深入分析,,從而大大節(jié)省了算力消耗,。
千問(wèn)3采用了混合專家(MoE)架構(gòu),,總參數(shù)量為235B,,激活僅需22B。其預(yù)訓(xùn)練數(shù)據(jù)量達(dá)到36T,,并在后訓(xùn)練階段經(jīng)過(guò)多輪強(qiáng)化學(xué)習(xí),,實(shí)現(xiàn)了非思考模式與思考模式之間的無(wú)縫整合。千問(wèn)3在多個(gè)方面表現(xiàn)出色,,包括推理能力,、指令遵循、工具調(diào)用以及多語(yǔ)言支持等,,均達(dá)到了國(guó)產(chǎn)及全球開(kāi)源模型的新高度,。例如,在AIME25奧數(shù)水平測(cè)試中,,千問(wèn)3獲得了81.5分的成績(jī),,刷新了開(kāi)源記錄;在LiveCodeBench代碼能力評(píng)測(cè)中,,得分超過(guò)70分,,甚至超過(guò)了Grok3的表現(xiàn);而在ArenaHard的人類偏好對(duì)齊評(píng)估中,,以95.6分超越了OpenAI-o1及DeepSeek-R1,。值得注意的是,,盡管性能大幅提升,但千問(wèn)3的部署成本卻大幅下降,,只需4張H20即可完成滿血版部署,,顯存占用僅為性能相近模型的三分之一。

丈夫回應(yīng)妻子發(fā)求交房被指擦邊 只為維權(quán)無(wú)不當(dāng)

男孩帶病逝媽媽照片高考 考完第一時(shí)間去墓前祭拜

中使館感謝印度海軍施救中國(guó)船員 救援行動(dòng)持續(xù)進(jìn)行
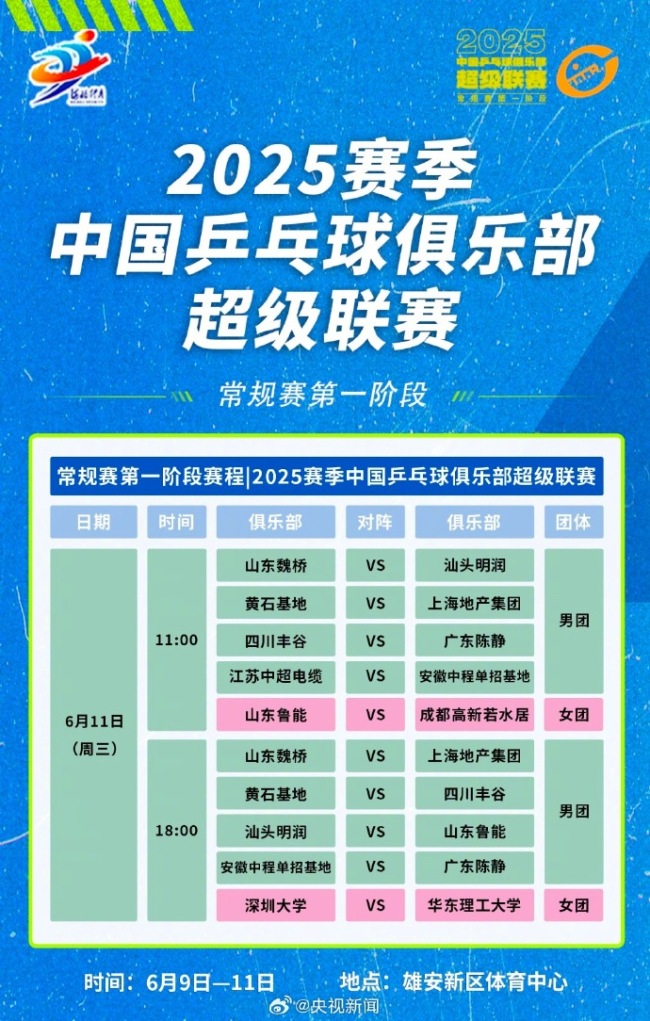
孫穎莎王楚欽樊振東隊(duì)伍分團(tuán)對(duì)決 網(wǎng)友:期待精彩比賽,!

中美經(jīng)貿(mào)磋商原則上達(dá)成協(xié)議框架 會(huì)談取得積極進(jìn)展

只有中國(guó)能打掉美國(guó)的優(yōu)越感,!

十幾名美國(guó)警察追捕落單示威者 移民執(zhí)法引發(fā)沖突

美醫(yī)學(xué)界要求特朗普政府撤銷決定 突然撤換CDC疫苗咨詢小組所有成員

馬斯克2.7億政治捐款打水漂 盟友變對(duì)手

3天被拒18次,老年人租房難背后

李成鋼:中美原則上達(dá)成協(xié)議框架
丈夫回應(yīng)妻子發(fā)求交房被指擦邊 只為維權(quán)無(wú)不當(dāng)

“內(nèi)戰(zhàn)”言論背后美國(guó)局勢(shì)如何發(fā)展 憲政危機(jī)浮現(xiàn)
中使館感謝印度海軍施救中國(guó)船員 救援行動(dòng)持續(xù)進(jìn)行

女孩考試后獨(dú)自挑行李回家 腳步鏗鏘有力
男孩帶病逝媽媽照片高考 考完第一時(shí)間去墓前祭拜

澤連斯基要求美國(guó)歐洲采取行動(dòng) 施壓促和平

業(yè)內(nèi)人士回應(yīng)考古發(fā)現(xiàn)采藥昆侖石刻 引發(fā)學(xué)術(shù)爭(zhēng)議

特朗普稱洛杉磯被外國(guó)入侵,,紐森稱特朗普是個(gè)騙子,! 加州州長(zhǎng)反對(duì)派兵決定

瑞典環(huán)保少女反懟特朗普 情緒管理課建議
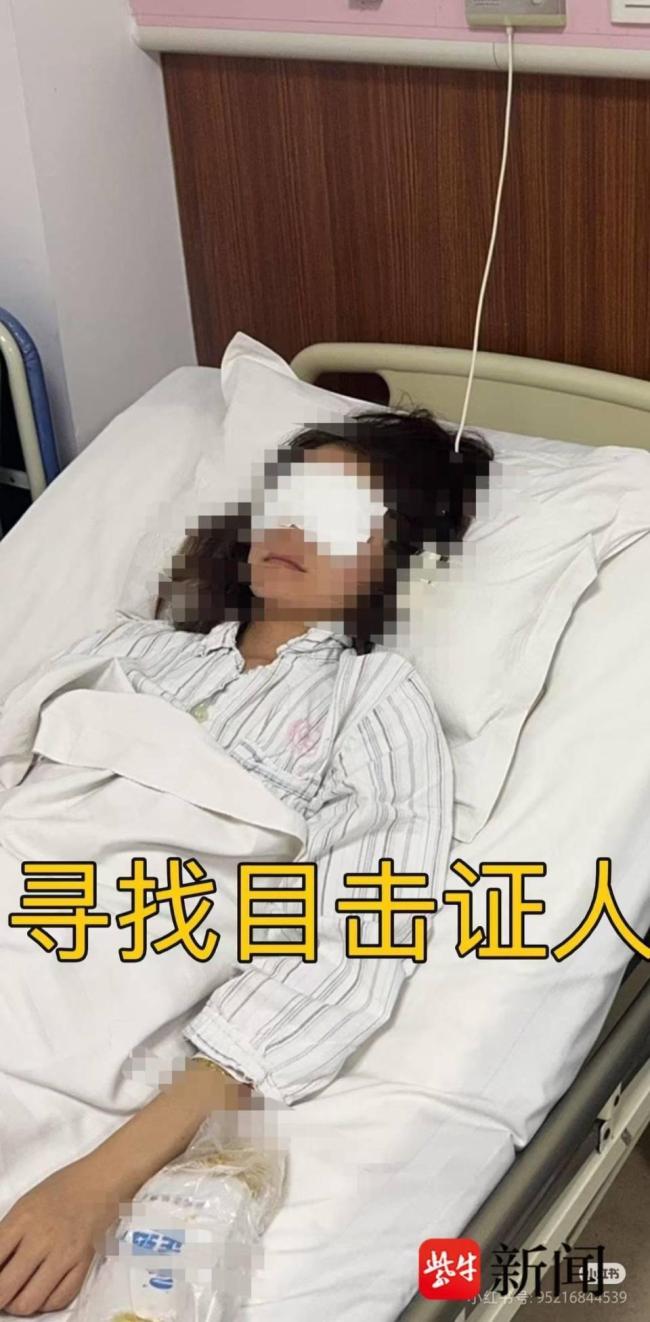
遭男子水槍攻擊失明女孩發(fā)聲 尋找目擊證人

一號(hào)臺(tái)風(fēng)來(lái)了 南海低壓或?qū)⒓訌?qiáng)登陸

加州落單示威者被十幾名美警追捕 移民“圍捕戰(zhàn)”持續(xù)升級(jí)

銀行出奇招日送LABUBU三四十個(gè) LABUBU成攬儲(chǔ)“神器”

氫能再迎重磅利好 基金重倉(cāng)股出爐 多只概念股獲基金青睞

臺(tái)網(wǎng)紅館長(zhǎng)上海被投喂美食三件套 大陸之行引關(guān)注

一船只在印度海域發(fā)生爆炸 船員傷亡情況引關(guān)注

臺(tái)灣網(wǎng)紅“館長(zhǎng)”來(lái)大陸:看看就知道誰(shuí)說(shuō)謊了 實(shí)地體驗(yàn)破除謠言

特斯拉市值一夜大漲4000億 科技股領(lǐng)漲美股
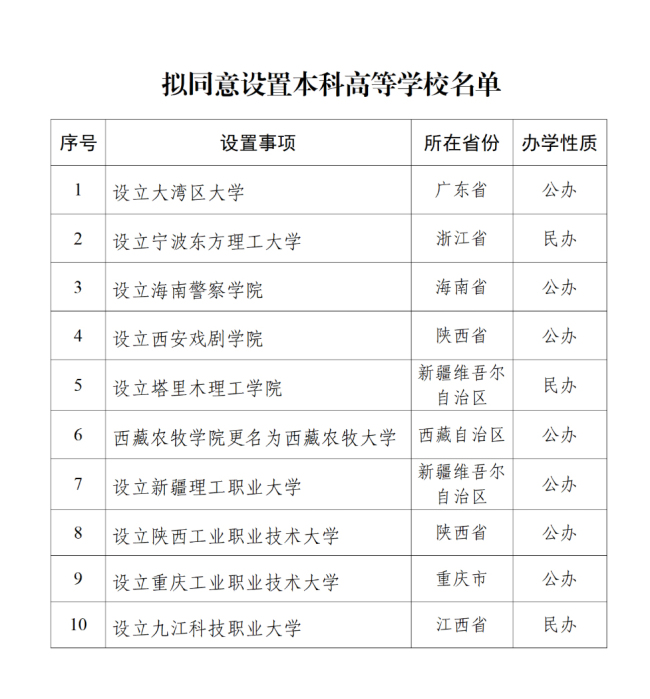
大灣區(qū)大學(xué)要來(lái)了 擬同意設(shè)置公示

小米汽車承諾支付賬期不超60天 多家車企跟進(jìn)響應(yīng)
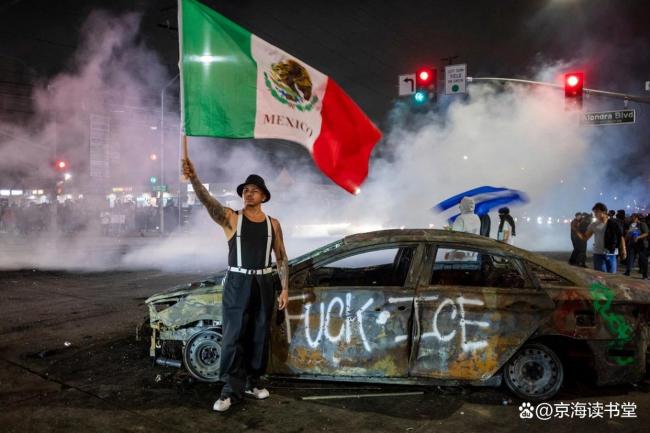
美國(guó)洛杉磯爆發(fā)的大規(guī)模騷亂的本質(zhì)及未來(lái)趨勢(shì)

英澳加等制裁以財(cái)長(zhǎng)及國(guó)安部長(zhǎng) 五國(guó)聯(lián)合行動(dòng)

專家:李在明要強(qiáng)化韓美關(guān)系 展開(kāi)實(shí)用外交策略

廣東U16女足姑娘淚灑賽場(chǎng) 雖敗猶榮未來(lái)可期
相關(guān)新聞
通義App全面上線千問(wèn)3 最強(qiáng)開(kāi)源模型體驗(yàn)升級(jí)
2025-04-29 13:32:13通義App全面上線千問(wèn)3阿里萬(wàn)相大模型登上全球開(kāi)源榜首 下載量破百萬(wàn)
2025-03-03 10:47:59阿里萬(wàn)相大模型登上全球開(kāi)源榜首阿里萬(wàn)相視頻大模型宣布開(kāi)源 全模態(tài)全尺寸模型開(kāi)源
2025-02-26 11:13:00阿里萬(wàn)相視頻大模型宣布開(kāi)源小米首個(gè)推理大模型開(kāi)源 超越OpenAI與阿里模型
2025-04-30 12:54:33小米首個(gè)推理大模型開(kāi)源阿里通義千問(wèn)模型Qwen3有哪些亮點(diǎn) 多尺寸全模態(tài)支持
阿里通義千問(wèn)開(kāi)源負(fù)責(zé)人林俊旸在X上發(fā)文暗示,,Qwen3模型有望于4月28日發(fā)布
2025-04-29 21:25:44阿里通義千問(wèn)模型Qwen3有哪些亮點(diǎn)DeepSeek后又一大模型向全球開(kāi)源 吉利貢獻(xiàn)開(kāi)源力量
2025-02-19 08:09:19DeepSeek后又一大模型向全球開(kāi)源








